

参考视频:雷神谷粒商城项目
Ⅰ.仿京东购物车系统
- 购物车Redis数据结构选型:
- 双层 Map:
Map<String,Map<String,String>>- 第一层 Map,Key 是用户 id
- 第二层 Map,Key 是购物车中商品 id,值是购物项数据
- 双层 Map:
- 购物车两个核心功能:新增商品到购物车、查询购物车
- 新增商品:判断是否登录
- 是:则添加商品到后台 Redis 中,把 user 的唯一标识符作为 key。
- 否:则添加商品到后台 Redis 中,使用随机生成的 user-key 作为 key。
- 新增商品:判断是否登录
- 查询购物车列表:判断是否登录
- 否:直接根据 user-key 查询 Redis 中数据并展示
- 是:已登录,则需要先根据 user-key 查询 Redis 是否有数据。
- 有:需要提交到后台添加到 Redis ,合并数据,而后查询。
- 否:直接去后台查询 Redis ,而后返回
1、购物车需求
1)、需求描述:
- 用户可以在登录状态下将商品添加到购物车【用户购物车/在线购物车】
- 放入数据库
- mongodb
- 放入 redis(采用)
- 登录以后,会将临时购物车的数据全部合并过来,并清空临时购物车;
- 用户可以在未登录状态下将商品添加到购物车【游客购物车/离线购物车/临时购物车】
- 放入 localstorage(客户端存储,后台不存)
- cookie
- WebSQL
- 放入 redis(采用)
- 浏览器即使关闭,下次进入,临时购物车数据都在
- 用户可以使用购物车一起结算下单
- 给购物车添加商品
- 用户可以查询自己的购物车
- 用户可以在购物车中修改购买商品的数量。
- 用户可以在购物车中删除商品。
- 选中不选中商品
- 在购物车中展示商品优惠信息
- 提示购物车商品价格变化
2)、数据结构

Map<String k1,Map<String k2,CartItemInfo>>| 在redis中- k1:标识每一个用户的购物车 | key:用户标识
- k2:购物项的商品id | value:Hash(k:商品id,v:购物项详情)
因此每一个购物项信息,都是一个对象,基本字段包括:
{
skuId: 2131241,
check: true,
title: "Apple iphone.....",
defaultImage: "...",
price: 4999,
count: 1,
totalPrice: 4999,
skuSaleVO: {...}
}另外,购物车中不止一条数据,因此最终会是对象的数组。即:
[
{...},{...},{...}
]Redis 有 5 种不同数据结构,这里选择哪一种比较合适呢?
Map<String, List<String>>
- 首先不同用户应该有独立的购物车,因此购物车应该以用户的作为 key 来存储,Value 是 用户的所有购物车信息。这样看来基本的
k-v结构就可以了。- 但是,我们对购物车中的商品进行增、删、改操作,基本都需要根据商品 id 进行判断, 为了方便后期处理,我们的购物车也应该是
k-v结构,key 是商品 id,value 才是这个商品的 购物车信息。 综上所述,我们的购物车结构是一个双层 Map:Map<String,Map<String,String>>- 第一层 Map,Key 是用户 id
- 第二层 Map,Key 是购物车中商品 id,值是购物项数据
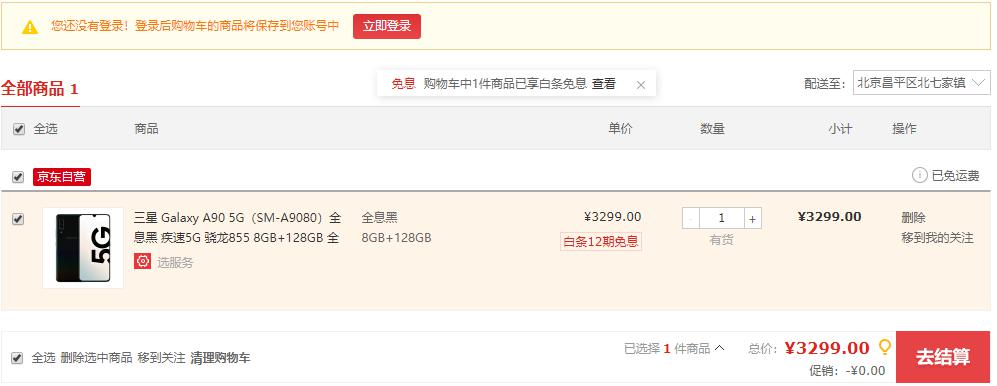
3)、流程
参照京东
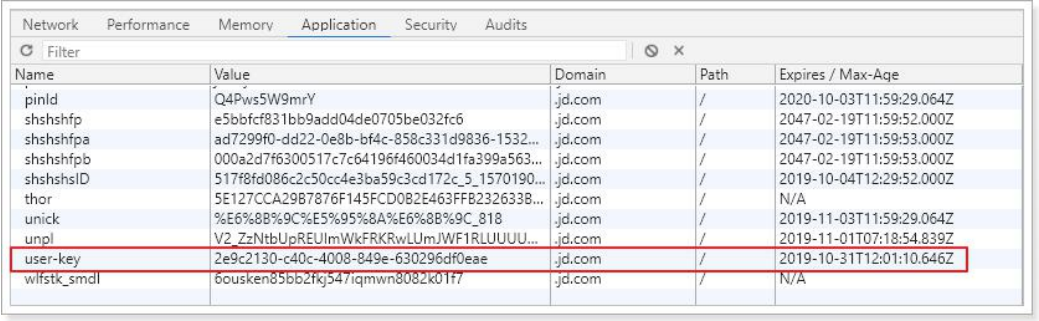
user-key 是随机生成的 id,不管有没有登录都会有这个 cookie 信息。
两个功能:新增商品到购物车、查询购物车。
新增商品:判断是否登录
- 是:则添加商品到后台 Redis 中,把 user 的唯一标识符作为 key。
否:则添加商品到后台 redis 中,使用随机生成的 user-key 作为 key。
查询购物车列表:判断是否登录
- 否:直接根据 user-key 查询 redis 中数据并展示
- 是:已登录,则需要先根据 user-key 查询 redis 是否有数据。
- 有:需要提交到后台添加到 redis,合并数据,而后查询。
- 否:直接去后台查询 redis,而后返回。
4)、引入依赖
<!-- 引入redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>2、添加购物车
- 用户信息数据传输To
- tempUser = false表示默认是登录用户,即将用户唯一id作为缓存key
- tempUser = true表示是游客身份,系统将生成随机码user-key作为缓存key
@ToString
@Data
public class UserInfoTo {
private Long userId;
private String userKey;//一定封装
private boolean tempUser = false;
}- 购物车拦截器
/**
* 拦截器
* 在执行目标方法之前,判断用户的登录状态,并封装传递给controller目标请求
* @author Klaus
* @date 2022/9/19
*/
public class CartInterceptor implements HandlerInterceptor {
public static ThreadLocal<UserInfoTo> threadLocal = new ThreadLocal<>();
/**
* 目标方法执行之前
* @param request
* @param response
* @param handler
* @return
* @throws Exception
*/
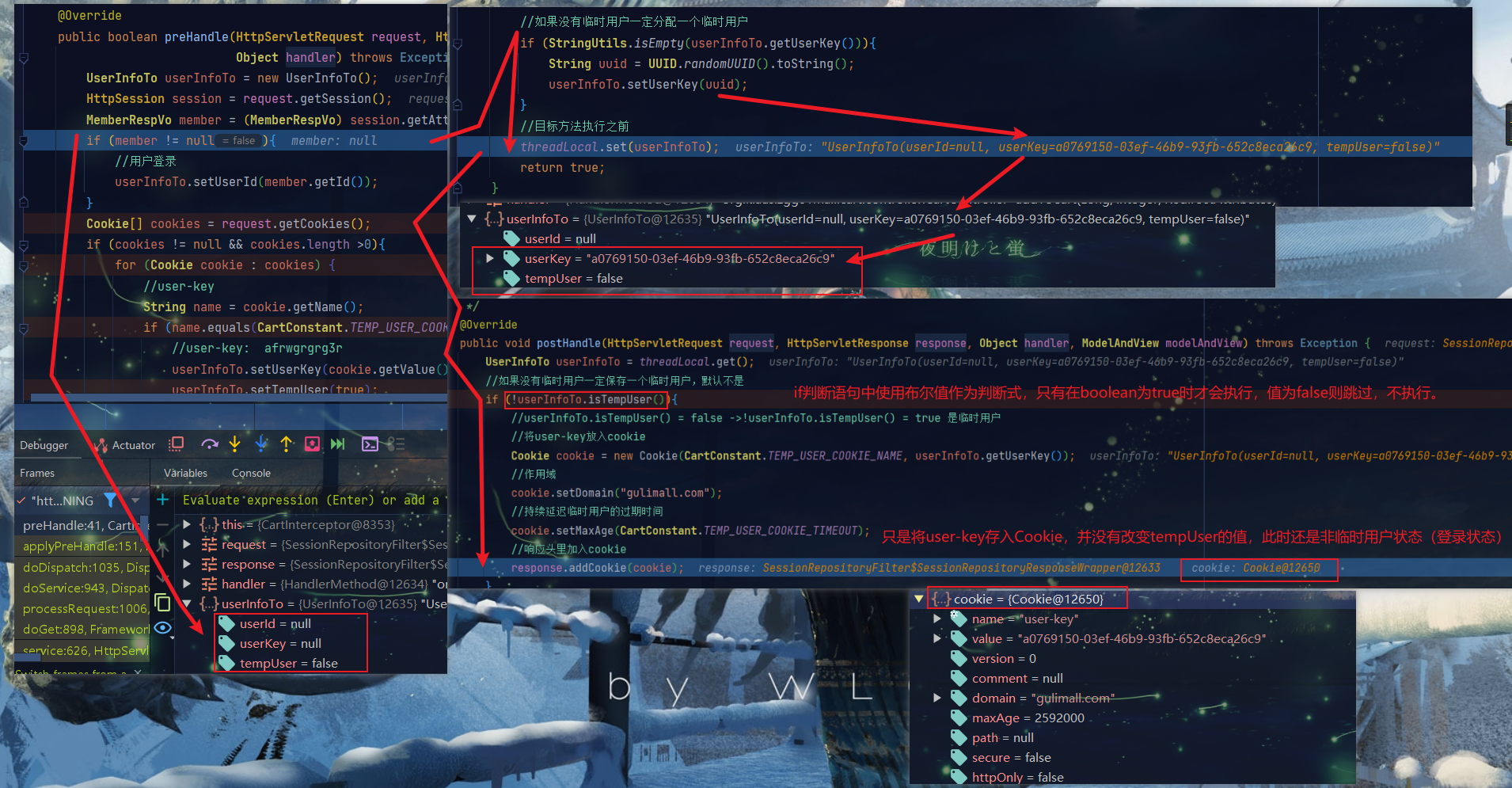
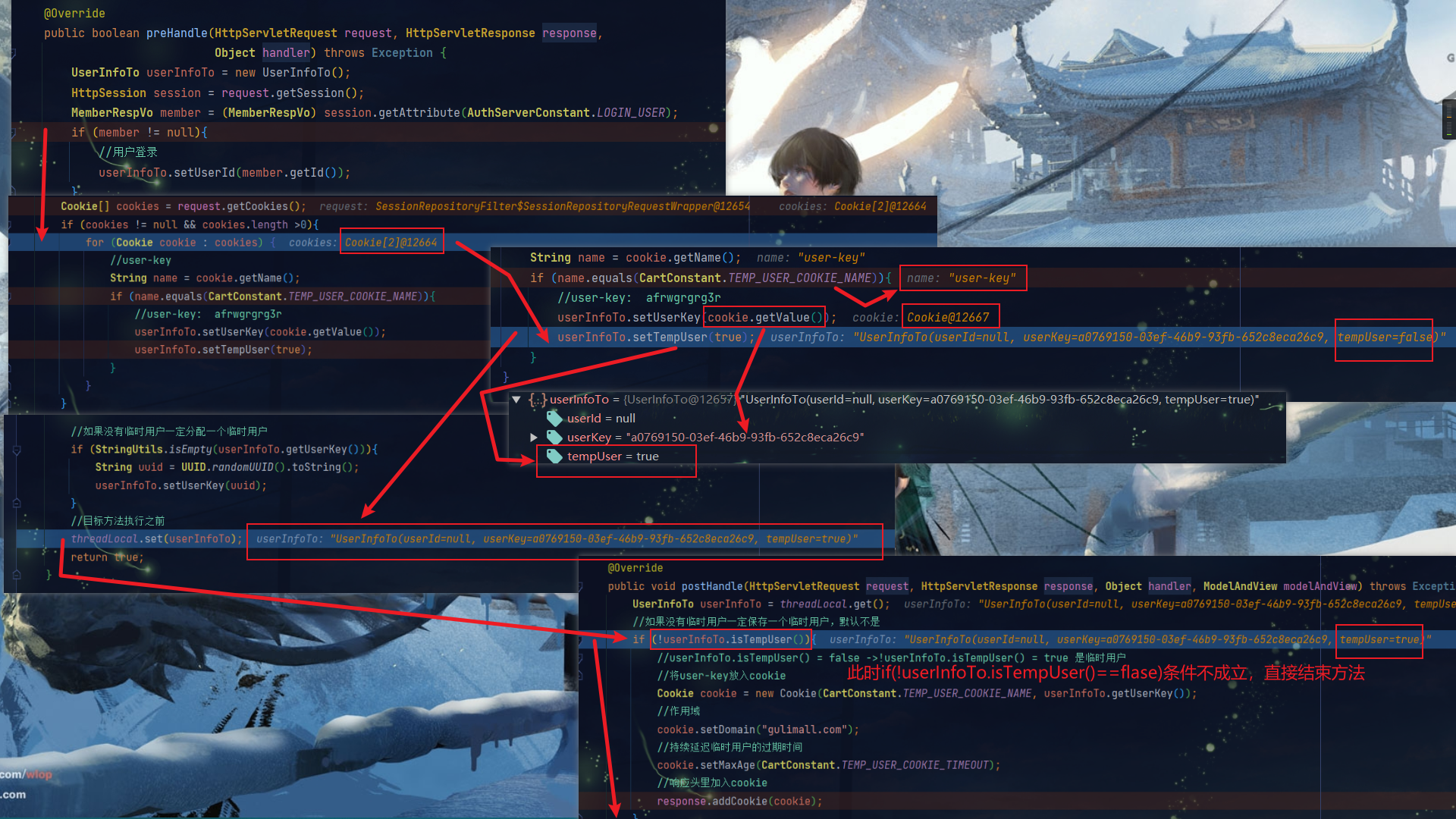
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response,
Object handler) throws Exception {
UserInfoTo userInfoTo = new UserInfoTo();
HttpSession session = request.getSession();
MemberRespVo member = (MemberRespVo) session.getAttribute(AuthServerConstant.LOGIN_USER);
if (member != null){
//用户登录
userInfoTo.setUserId(member.getId());
}
Cookie[] cookies = request.getCookies();
if (cookies != null && cookies.length >0){
for (Cookie cookie : cookies) {
//user-key
String name = cookie.getName();
if (name.equals(CartConstant.TEMP_USER_COOKIE_NAME)){
//user-key: afrwgrgrg3r
userInfoTo.setUserKey(cookie.getValue());
userInfoTo.setTempUser(true);
}
}
}
//如果没有临时用户一定分配一个临时用户
if (StringUtils.isEmpty(userInfoTo.getUserKey())){
String uuid = UUID.randomUUID().toString();
userInfoTo.setUserKey(uuid);
}
//目标方法执行之前
threadLocal.set(userInfoTo);
return true;
}
/**
* 业务执行之后,分配临时用户,让浏览器保存
* @param request
* @param response
* @param handler
* @param modelAndView
* @throws Exception
*/
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
UserInfoTo userInfoTo = threadLocal.get();
//如果没有临时用户一定保存一个临时用户,默认不是
if (!userInfoTo.isTempUser()){
//是临时用户
//将user-key放入cookie
Cookie cookie = new Cookie(CartConstant.TEMP_USER_COOKIE_NAME, userInfoTo.getUserKey());
//作用域
cookie.setDomain("gulimall.com");
//持续延迟临时用户的过期时间
cookie.setMaxAge(CartConstant.TEMP_USER_COOKIE_TIMEOUT);
//响应头里加入cookie
response.addCookie(cookie);
}
}
}DEBUG拦截器
- 首次访问首页(未登录状态),执行目标方法之前(添加商品到购物车),在页面没有异步请求没超时前完成以下步骤(超时直接404,操作失败)
- 在规定时间(30s左右)内完成以上操作,将user-key存入Cookie成功,返回preHandle方法
添加购物车接口
org.klaus.zgg01mall.cart.controller.CartController#addToCart
/**
* 添加商品到购物车
* redirectAttributes.addFlashAttribute():将数据放在session里面可以在页面取出,但是只能取一次
* redirectAttributes.addAttribute("skuId", skuId);将数据放在url后面
* @return
*/
@GetMapping("/addToCart")
public String addToCart(@RequestParam("skuId") Long skuId,
@RequestParam("num") Integer num,
RedirectAttributes redirectAttributes) throws ExecutionException, InterruptedException {
cartService.addToCart(skuId, num);
// model.addAttribute("skuId", skuId); //Required Long parameter 'skuId' is not present
redirectAttributes.addAttribute("skuId", skuId);
//添加商品到购物车,重定向到成功页面->刷新页面不会再增加购物车数量http://cart.gulimall.com/addToCart?skuId=35&num=1
return "redirect:http://cart.gulimall.com/addToCartSuccess.html";
}org.klaus.zgg01mall.cart.vo.Cart
/**
* 整个购物车的内容
* 需要计算的属性,必须重写他的get方法,保证每次获取属性都会进行计算
* @author Klaus
* @date 2022/9/19
*/
public class Cart {
private List<CartItem> items;
private Integer countNum;//商品数量
private Integer countType;//商品类型数量
private BigDecimal totalAmount;//商品总价
private BigDecimal reduce = new BigDecimal("0.00");//减免价格
public List<CartItem> getItems() {
return items;
}
public void setItems(List<CartItem> items) {
this.items = items;
}
/**
* 统计每一行*数量 再相加
* @return
*/
public Integer getCountNum() {
int count = 0;
if (items != null && items.size() > 0) {
for (CartItem item : items) {
count += item.getCount();
}
}
return count;
}
/**
* 统计每一行相加
* @return
*/
public Integer getCountType() {
int count = 0;
if (items != null && items.size() > 0) {
for (CartItem item : items) {
count += 1;
}
}
return count;
}
public BigDecimal getTotalAmount() {
BigDecimal amount = new BigDecimal("0");
//1、计算购物项总价
if (items != null && items.size() > 0) {
for (CartItem item : items) {
if (item.getCheck()){
//购物项被选中才进行计算
BigDecimal totalPrice = item.getTotalPrice();
amount = amount.add(totalPrice);
}
}
}
//2、减去优惠总价
BigDecimal subtract = amount.subtract(getReduce());
return subtract;
}
public BigDecimal getReduce() {
return reduce;
}
public void setReduce(BigDecimal reduce) {
this.reduce = reduce;
}
}org.klaus.zgg01mall.cart.vo.CartItem
/**
* 购物项
* 例如:
* {
* skuId: 2131241,
* check: true,
* title: "Apple iphone.....",
* defaultImage: "...",
* price: 4999,
* count: 1,
* totalPrice: 4999,
* skuSaleVO: {...}
* }
* @author Klaus
* @date 2022/9/19
*/
public class CartItem {
private Long skuId;
private Boolean check = true;
private String title;
private String image;
private List<String> skuAttrs;
private BigDecimal price;
private Integer count;
private BigDecimal totalPrice;
....
/**
* 计算当前项总价
* @return
*/
public BigDecimal getTotalPrice() {
return this.price.multiply(new BigDecimal("" + this.count));
}
public void setTotalPrice(BigDecimal totalPrice) {
this.totalPrice = totalPrice;
}
}- 添加购物车方法实现
org.klaus.zgg01mall.cart.service.impl.CartServiceImpl#addToCart- 对购物车进行Redis的hash绑定操作
Map<String, List<String>>
- 对购物车进行Redis的hash绑定操作
| key=String | value=List<String> |
|---|---|
| userId/userKey | cart=Map<skuId,cartItem> |
| userId/userKey | cart=Map<skuId,cartItem> |
| userId/userKey | cart=Map<skuId,cartItem> |
/**
* 第一层 Map, Key 是用户 id
* 第二层 Map, Key 是购物车中商品 id, 值是购物项数据
* 将商品添加到购物车
*
* @param skuId
* @param num
* @return
*/
@Override
public CartItem addToCart(Long skuId, Integer num) throws ExecutionException, InterruptedException {
//操作购物车
BoundHashOperations<String, Object, Object> cartOps = getCartOps();
String res = (String) cartOps.get(skuId.toString());
if (StringUtils.isEmpty(res)) {
//购物车没有这个商品执行以下代码
//2、添加新商品到购物车
CartItem cartItem = new CartItem();
CompletableFuture<Void> getSkuInfoTask = CompletableFuture.runAsync(() -> {
//1、远程查询当前要添加的商品的信息
R r = productFeignService.getSkuInfo(skuId);
SkuInfoVo data = r.getData("skuInfo", new TypeReference<SkuInfoVo>() {
});
cartItem.setCheck(true);
cartItem.setCount(num);
cartItem.setImage(data.getSkuDefaultImg());
cartItem.setTitle(data.getSkuTitle());
cartItem.setSkuId(skuId);
cartItem.setPrice(data.getPrice());
}, executor);
//3、远程查询sku的组合信息
CompletableFuture<Void> getSkuSaleAttrValues = CompletableFuture.runAsync(() -> {
List<String> values = productFeignService.getSkuSaleAttrValues(skuId);
cartItem.setSkuAttrs(values);
}, executor);
//异步全部完成才加入缓存
CompletableFuture.allOf(getSkuInfoTask, getSkuSaleAttrValues).get();
String s = JSON.toJSONString(cartItem);
//加入缓存,skuId cartItem
cartOps.put(skuId.toString(), s);
return cartItem;
} else {
//购物车有此商品,进行数量修改
CartItem cartItem = JSON.parseObject(res, CartItem.class);
//当前操作仅修改了逆转回来的数据,还需要更新redis
cartItem.setCount(cartItem.getCount() + num);
//再将修改后的数据转为json并存入redis
cartOps.put(skuId.toString(), JSON.toJSONString(cartItem));
return cartItem;
}
}- hash绑定方法,通过StringRedisTemplate将cartKey=gulimall:cart:userId/userKey与hash进行绑定操作
/**
* 获取到我们要操作的购物车
*
* @return
*/
private BoundHashOperations<String, Object, Object> getCartOps() {
UserInfoTo userInfoTo = CartInterceptor.threadLocal.get();
//1、判断用户是否登录了
String cartKey = "";
if (userInfoTo.getUserId() != null) {
//用户登录了
cartKey = CART_PREFIX + userInfoTo.getUserId();
} else {
//用户没登录
cartKey = CART_PREFIX + userInfoTo.getUserKey();
}
//将购物车加入缓存绑定操作(hash)
BoundHashOperations<String, Object, Object> operations = redisTemplate.boundHashOps(cartKey);
return operations;
}添加购物车时由String res = (String) cartOps.get(skuId.toString());判断指定商品是否加入了购物车,没有就进行添加购物车操作,异步全部完成封装购物项的信息后才加入缓存,将购物项转为Json形式存入hash中->String s = JSON.toJSONString(cartItem);cartOps.put(skuId.toString(), s); 购物车有此商品则进行添加操作,将缓存中的Json数据转为购物项对象进行添加操作,添加完再转回Json并存入hash中
3、购物车列表
- 购物车列表接口
org.klaus.zgg01mall.cart.controller.CartController#cartListPage
/**
* 浏览器有一个cookie:user-key:标识用户身份,一个月后过期
* 如果第一次使用jd的购物车功能,都会给一个临时的用户身份
* 浏览器以后保存,每次访问都会带上这个cookie;
*
* 登录:session有
* 没登录,按照cookie里面带来user-key来做
* 第一次,如果没有临时用户,会帮忙创建一个临时用户。
* @return
*/
@GetMapping("/cart.html")
public String cartListPage(Model model) throws ExecutionException, InterruptedException {
//1、快速得到用户信息:id,user-key
// UserInfoTo userInfoTo = CartInterceptor.threadLocal.get();
// System.out.println(userInfoTo);
Cart cart = cartService.getCart();
model.addAttribute("cart", cart);
return "cartList";
}- 获取整个购物车方法实现
org.klaus.zgg01mall.cart.service.impl.CartServiceImpl#getCart
/**
* 获取整个购物车
*
* @return
*/
@Override
public Cart getCart() throws ExecutionException, InterruptedException {
Cart cart = new Cart();
UserInfoTo userInfoTo = CartInterceptor.threadLocal.get();
if (userInfoTo.getUserId() != null) {
//1、登录
String cartKey = CART_PREFIX + userInfoTo.getUserId();
//1.1、如果临时购物车的数据还没有合并【合并购物车】
//临时购物车的所有购物项
String tempCartKey = CART_PREFIX + userInfoTo.getUserKey();
List<CartItem> tempCartItems = getCartItems(tempCartKey);
if (tempCartItems != null) {
//临时购物车有数据,需要合并
for (CartItem item : tempCartItems) {
addToCart(item.getSkuId(), item.getCount());
}
//合并完后清除临时购物车的数据
clearCart(tempCartKey);
}
//3、获取登录后的购物车数据【包含合并过来的临时购物车的数据,和登录后的购物车数据】
List<CartItem> cartItems = getCartItems(cartKey);
cart.setItems(cartItems);
} else {
//2、没登录
String cartKey = CART_PREFIX + userInfoTo.getUserKey();
//获取临时购物车的所有购物项
List<CartItem> cartItems = getCartItems(cartKey);
cart.setItems(cartItems);
}
return cart;
}- 获取所有购物项方法
org.klaus.zgg01mall.cart.service.impl.CartServiceImpl#getCartItems- 获取购物项再次进行hash绑定操作,因为之前已经绑定过一次,如果添加过购物车,缓存中是有数据的,直接遍历缓存中的Json数据并转为购物项对象返回出去,若没有则返回null
private List<CartItem> getCartItems(String cartKey) {
BoundHashOperations<String, Object, Object> hashOps = redisTemplate.boundHashOps(cartKey);
List<Object> values = hashOps.values();
if (values != null && values.size() > 0) {
List<CartItem> collect = values.stream().map((obj) -> {
String str = (String) obj;
CartItem cartItem = JSON.parseObject(str, CartItem.class);
return cartItem;
}).collect(Collectors.toList());
return collect;
}
return null;
}4、添加购物车成功页
- 添加购物车成功页接口
org.klaus.zgg01mall.cart.controller.CartController#addToCartSuccessPage
/**
* 跳转到成功页,增加购物车用到2个页面,防止在添加购物车之后再刷新页面时自动增加
* @param skuId
* @param model
* @return
*/
@GetMapping("/addToCartSuccess.html")
public String addToCartSuccessPage(@RequestParam("skuId")Long skuId, Model model){
//重定向到成功页面,再次查询购物车数据即可
CartItem item = cartService.getCartItem(skuId);
model.addAttribute("item", item);
return "success";
}- 获取购物项方法实现
org.klaus.zgg01mall.cart.service.impl.CartServiceImpl#getCartItem- 获取hash操作并拿到指定skuId的购物项Json,然后转为对象返回出去
/**
* 获取购物车中某个购物项
*
* @param skuId
* @return
*/
@Override
public CartItem getCartItem(Long skuId) {
BoundHashOperations<String, Object, Object> cartOps = getCartOps();
String str = (String) cartOps.get(skuId.toString());
//将缓存中的数据转为vo对象
CartItem cartItem = JSON.parseObject(str, CartItem.class);
return cartItem;
}5、删除购物项
- 删除购物项接口
@GetMapping("/deleteItem")
public String deleteItem(@RequestParam("skuId") Long skuId){
cartService.deleteItem(skuId);
return "redirect:http://cart.gulimall.com/cart.html";
}- 删除购物项方法实现
- 通过hash操作删除指定skuId的购物项
/**
* 删除购物项
*
* @param skuId
*/
@Override
public void deleteItem(Long skuId) {
BoundHashOperations<String, Object, Object> cartOps = getCartOps();
//删除指定键
cartOps.delete(skuId.toString());
}6、改变购物项数量
- 改变购物项数量接口
@GetMapping("/countItem")
public String countItem(@RequestParam("skuId") Long skuId,
@RequestParam("num") Integer num){
cartService.changeItemCount(skuId, num);
return "redirect:http://cart.gulimall.com/cart.html";
}- 改变购物项数量方法实现
- 改变数量后通过hash操作将对象转为Json并存入hash
/**
* 修改购物项数量
*
* @param skuId
* @param num
*/
@Override
public void changeItemCount(Long skuId, Integer num) {
CartItem cartItem = getCartItem(skuId);
cartItem.setCount(num);
BoundHashOperations<String, Object, Object> cartOps = getCartOps();
cartOps.put(skuId.toString(), JSON.toJSONString(cartItem));
}7、选中购物项
- 选中购物项接口
@GetMapping("/checkItem")
public String checkItem(@RequestParam("skuId") Long skuId,
@RequestParam("check") Integer check){
cartService.checkItem(skuId, check);
return "redirect:http://cart.gulimall.com/cart.html";
}- 选中购物项方法实现
- 改变购物项的选中状态后通过hash操作将对象转为Json并存入hash
/**
* 勾选购物项
*
* @param skuId
* @param check
*/
@Override
public void checkItem(Long skuId, Integer check) {
BoundHashOperations<String, Object, Object> cartOps = getCartOps();
CartItem cartItem = getCartItem(skuId);
cartItem.setCheck(check == 1 ? true : false);
//将vo对象转为json序列化的文本
String s = JSON.toJSONString(cartItem);
cartOps.put(skuId.toString(), s);
}8、获取当前登录用户的购物项列表
- 获取当前登录用户的购物项列表接口(此接口是给订单服务远程调用的)
/**
* 不是页面跳转需加@ResponseBody
* @return
*/
@GetMapping("/currentUserCartItems")
@ResponseBody
public List<CartItem> currentUserCartItems(){
return cartService.getUserCartItems();
}- 获取当前登录用户的购物项列表方法实现
/**
* 获取当前用户的所有购物项
*
* @return
*/
@Override
public List<CartItem> getUserCartItems() {
UserInfoTo userInfoTo = CartInterceptor.threadLocal.get();
if (userInfoTo.getUserId() == null){
//没登录
return null;
}else {
//登录了
String cartKey = CART_PREFIX + userInfoTo.getUserId();
List<CartItem> cartItems = getCartItems(cartKey);
//只要选中了的购物项
List<CartItem> collect = cartItems.stream().filter(item ->
item.getCheck()//默认是true
).map(item->{
// R price = productFeignService.getPrice(item.getSkuId());
BigDecimal price = productFeignService.getPrice(item.getSkuId());
//todo 更新为最新的价格
// String data = (String) price.get("data");
// item.setPrice(new BigDecimal(data));
item.setPrice(price);
return item;
}).collect(Collectors.toList());
return collect;
}
}Ⅱ.解决分布式下session共享问题
1、session原理

2、分布式下session共享问题
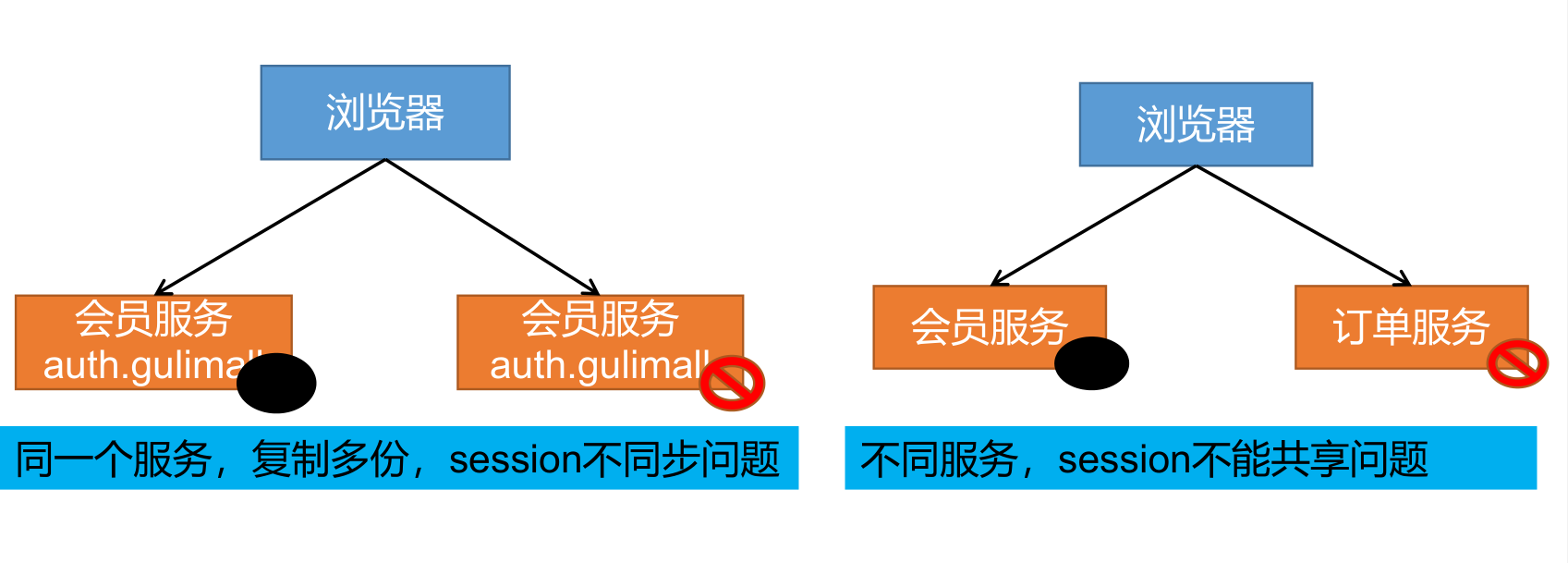
3、解决 - session复制
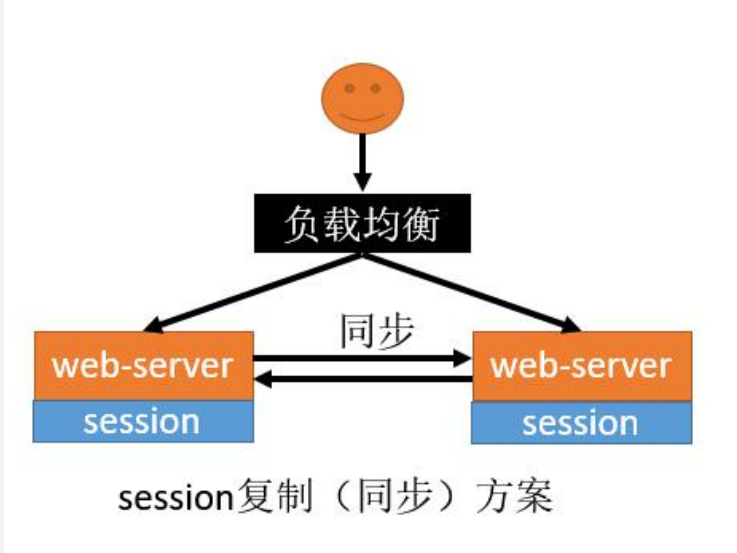
- 优点
- web-server(Tomcat)原生支持,只需要修改配置文件
- 缺点
- session同步需要数据传输,占用大量网络带宽,降低了服务器群的业务处理能力
- 任意一台web-server保存的数据都是所有web-server的session总和,受到内存限制无法水平扩展更多的web-server
- 大型分布式集群情况下,由于所有web-server都全量保存数据,所以此方案不可取。
4、解决 - 客户端存储
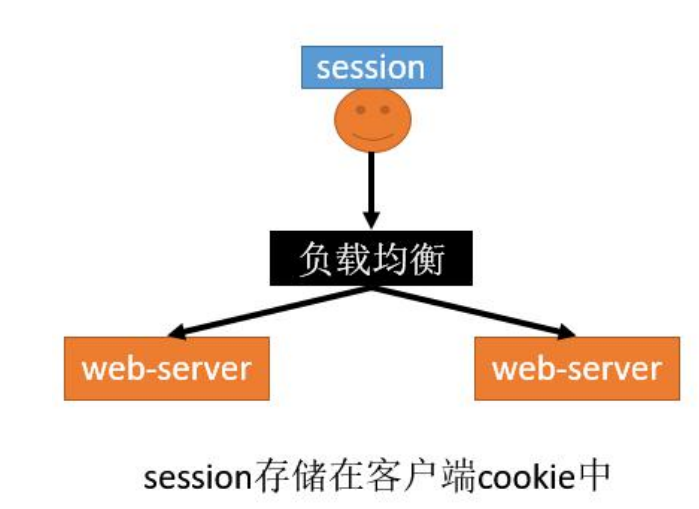
优点
- 服务器不需存储session,用户保存自己的session信息到cookie中。节省服务端资源
缺点
- 都是缺点,这只是一种思路。
- 具体如下:
- 每次http请求,携带用户在cookie中的完整信息,浪费网络带宽
- session数据放在cookie中,cookie有长度限制4K,不能保存大量信息
- session数据放在cookie中,存在泄漏、篡改、窃取等安全隐患
这种方式不会使用。
5、解决 - hash一致性
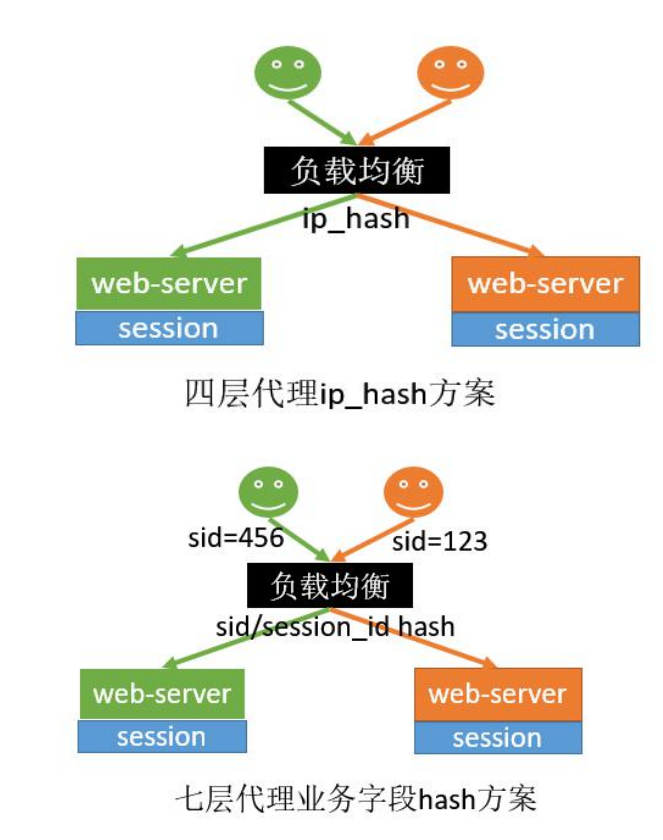
- 优点:
- 只需要改nginx配置,不需要修改应用代码
- 负载均衡,只要hash属性的值分布是均匀的,多台web-server的负载是均衡的
- 可以支持web-server水平扩展(session同步法是不行的,受内存限制)
- 缺点
- session还是存在web-server中的,所以web-server重启可能导致部分session丢失,影响业务,如部分用户需要重新登录
- 如果web-server水平扩展,rehash后session重新分布,也会有一部分用户路由不到正确的session
- 但是以上缺点问题也不是很大,因为session本来都是有有效期的。所以这两种反向代理的方式可以使用
6、解决 - 统一存储
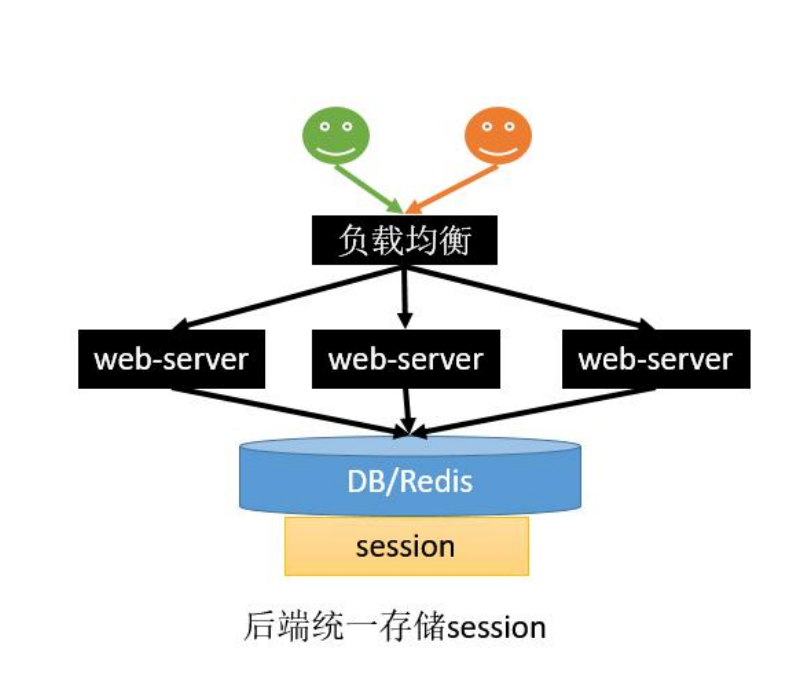
- 优点:
- 没有安全隐患
- 可以水平扩展,数据库/缓存水平切分即可
- web-server重启或者扩容都不会有session丢失
- 不足
- 增加了一次网络调用,并且需要修改应用代码;如将所有的getSession方法替换为从Redis查数据的方式。redis获取数据比内存慢很多
- 上面缺点可以用SpringSession完美解决
7、解决 - 不同服务,子域session共享
jsessionid这个cookie默认是当前系统域名的。当我们分拆服务,不同域名部署的时候,我们可以使用 如下解决方案;
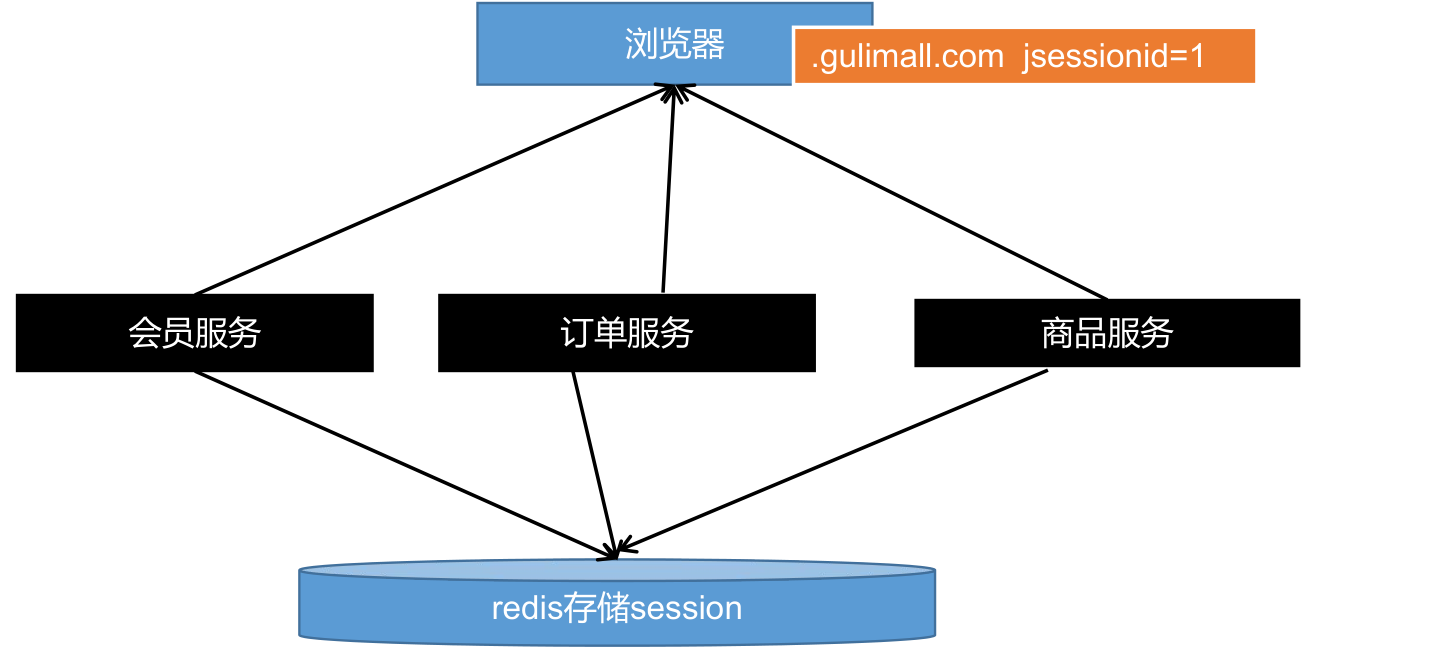
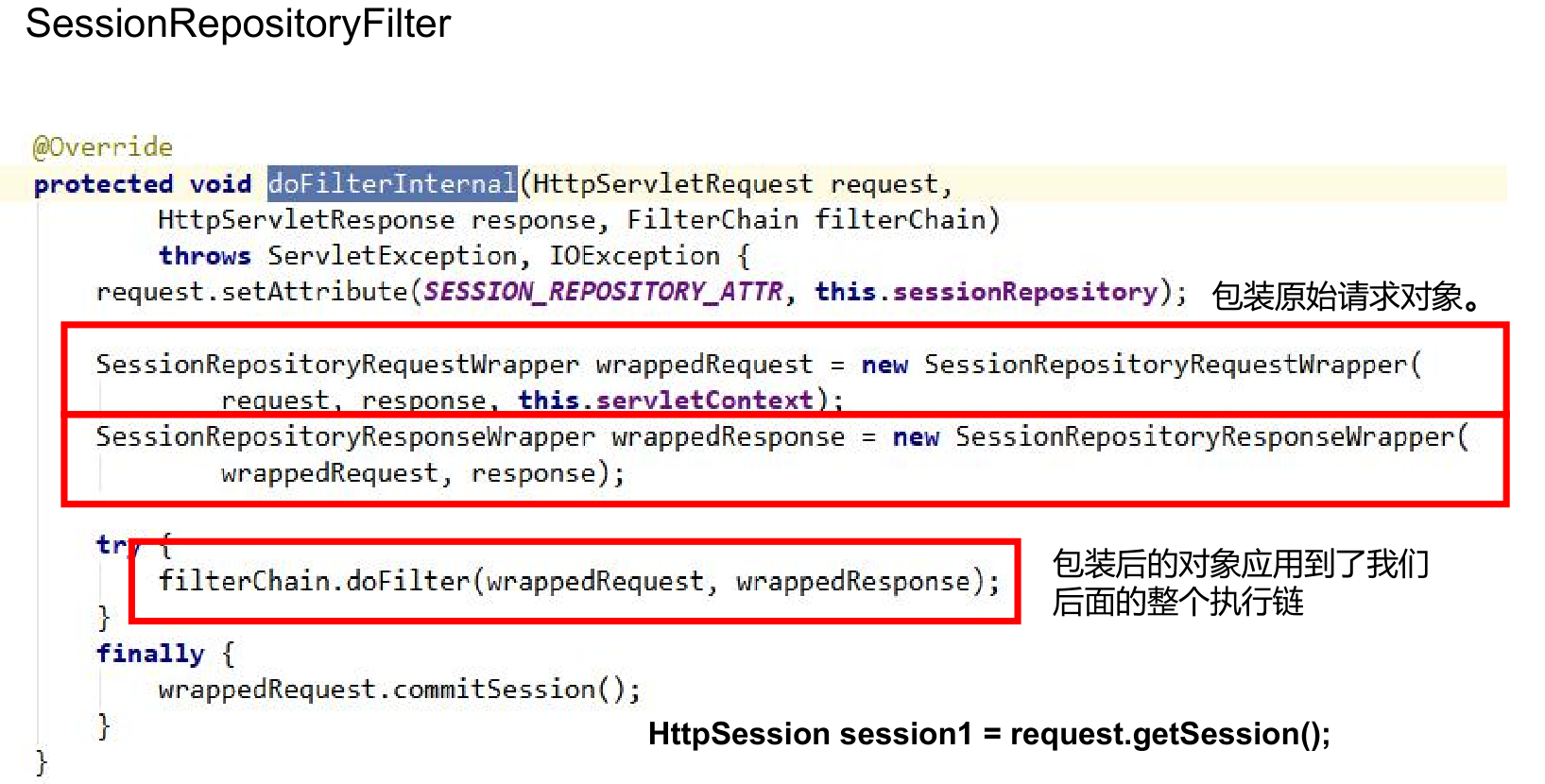
8、SpringSession核心原理
9、应用
/**
* 核心原理
* 1、@EnableRedisHttpSession导入RedisHttpSessionConfiguration配置
* 1)、给容器中添加了一个组件
* 传入SessionRepository==》【RedisOperationsSessionRepository】===》redis操作session,session的增删改查封装类
* 2)、SessionRepositoryFilter==》Filter(web):session存储过滤器;每个请求过来都必须经过Filter
* I)、创建的时候,就自动从容器中获取了SessionRepository
* II)、原始的HttpServletRequest request, HttpServletResponse response都被分别包装成了SessionRepositoryRequestWrapper,SessionRepositoryResponseWrapper
* III)、以后获取session-》request.getSession();(原始的)
* //SessionRepositoryRequestWrapper重写getSession方法
* IV)、wrapperRequest.getSession();==> SessionRepository中获取的到
* 装饰者模式;
*
* 自动延期;redis中的数据也是有过期时间的
*/
@EnableRedisHttpSession //整合redis作为session存储- 导入相关依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--整合Springsession完成session共享问题-->
<dependency>
<groupId>org.springframework.session</groupId>
<artifactId>spring-session-data-redis</artifactId>
</dependency>- SpringBootApplication类加上注解@EnableRedisHttpSession开启SpringSession
- 配置文件添加相关配置
spring.redis.host=192.168.10.103
spring.redis.port=6379
spring.session.store-type=REDIS- 添加配置类配置子域session共享
/**
* @author Klaus
* @date 2022/9/17
*/
@Configuration
public class GulimallSessionConfig {
@Bean
public CookieSerializer cookieSerializer(){
DefaultCookieSerializer cookieSerializer = new DefaultCookieSerializer();
cookieSerializer.setDomainName("gulimall.com");
cookieSerializer.setCookieName("KLAUSSESSION");
return cookieSerializer;
}
@Bean
public RedisSerializer<Object> springSessionDefaultRedisSerializer() {
return new GenericJackson2JsonRedisSerializer();
}
}使用session共享的目的是让需要用到登录session的页面都能共享到同一个session
Ⅲ.商品系统缓存所有分类
一、缓存
本地缓存
//本地缓存可以使用map
private Map<String, Object> cache;1、缓存使用
为了系统性能的提升,我们一般都会将部分数据放入缓存中,加速访问。而 db 承担数据落盘工作。
哪些数据适合放入缓存?
- 即时性、数据一致性要求不高的
- 访问量大且更新频率不高的数据(读多,写少)
举例:电商类应用,商品分类,商品列表等适合缓存并加一个失效时间(根据数据更新频率来定),后台如果发布一个商品,买家需要 5 分钟才能看到新的商品一般还是可以接受的。
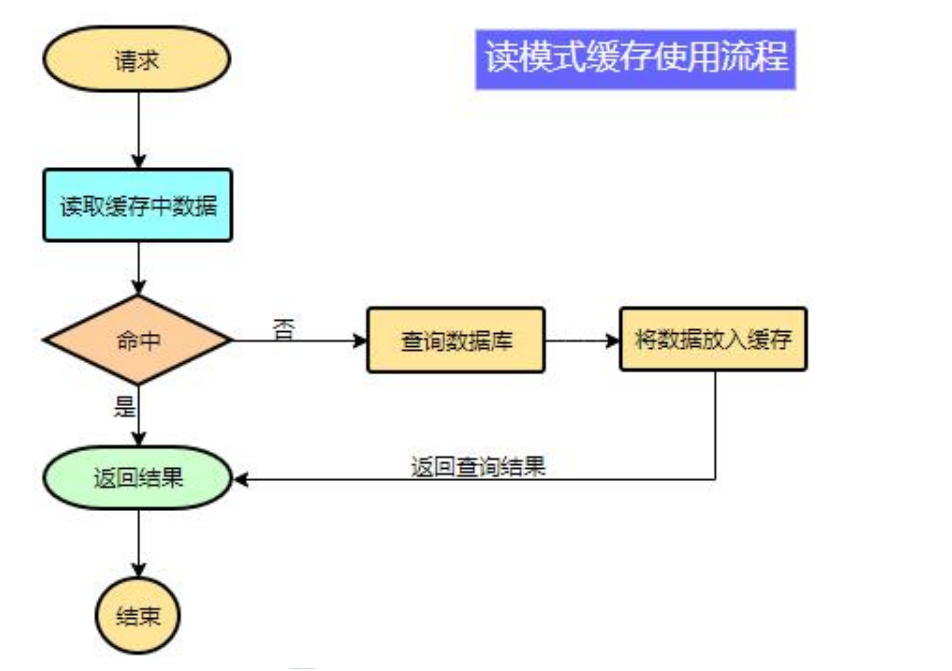
data = cache.load(id);//从缓存加载数据
If(data == null){
data = db.load(id);//从数据库加载数据
cache.put(id,data);//保存到 cache 中
}
return data;注意:在开发中,凡是放入缓存中的数据我们都应该指定过期时间,使其可以在系统即使没有主动更新数据也能自动触发数据加载进缓存的流程。避免业务崩溃导致的数据永久不一致问题。
2、整合 redis 作为缓存
- 1、引入 redis-starter
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>- 2、配置 redis
spring.redis.host=192.168.10.103
spring.redis.port=6379- 3、使用 RedisTemplate 操作 redis
@Autowired
StringRedisTemplate stringRedisTemplate;
@Test
public void testStringRedisTemplate(){
ValueOperations<String, String> ops = stringRedisTemplate.opsForValue();
ops.set("hello","world_"+ UUID.randomUUID().toString());
String hello = ops.get("hello");
System.out.println(hello);
}- 4、切换使用 jedis
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
产生堆外内存溢出:OutOfDirectMemoryError
- SpringBoot2.0以后默认使用lettuce作为操作redis的客户端,它使用netty进行网络通信
- lettuce的bug导致netty堆外内存溢出 -Xmx 100m;netty如果没有指定堆外内存,默认使用-Xmx 100m
- 可以通过-Di0.netty.maxDirectMemory进行设置
解决方案:不能只使用-Di0.netty.maxDirectMemory去调大堆外内存
- 升级lettuce客户端
- 切换使用老版的jedis
lettuce,jedis操作redis的底层客户端,Spring再次封装redisTemplate
二、缓存失效问题
分布式缓存-本地模式在分布式下的问题
先来解决大并发读情况下的缓存失效问题;
1、高并发下缓存失效问题-缓存穿透
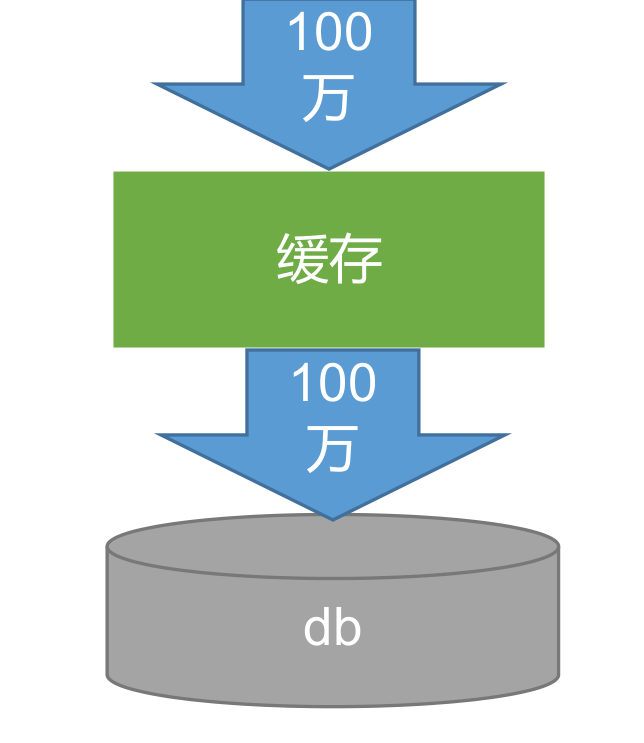
缓存穿透是指查询一个一定不存在的数据,由于缓存是不命中,将去查询数据库,但是数据库也无此记录,我们没有将这次查询的 null 写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
风险:
- 在流量大时,可能 DB 就挂掉了,要是有人利用不存在的 key 频繁攻击我们的应用,数据库瞬时压力增大,最终导致崩溃,这就是漏洞。
解决:
- 缓存空结果、并且设置短的过期时间。
2、高并发下缓存失效问题-缓存雪崩
缓存雪崩是指在我们设置缓存时采用了相同的过期时间,导致缓存在某一时刻同时失效,请求全部转发到 DB,DB 瞬时压力过重雪崩。
解决:
- 原有的失效时间基础上增加一个随机值,比如 1-5 分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
3、高并发下缓存失效问题-缓存击穿
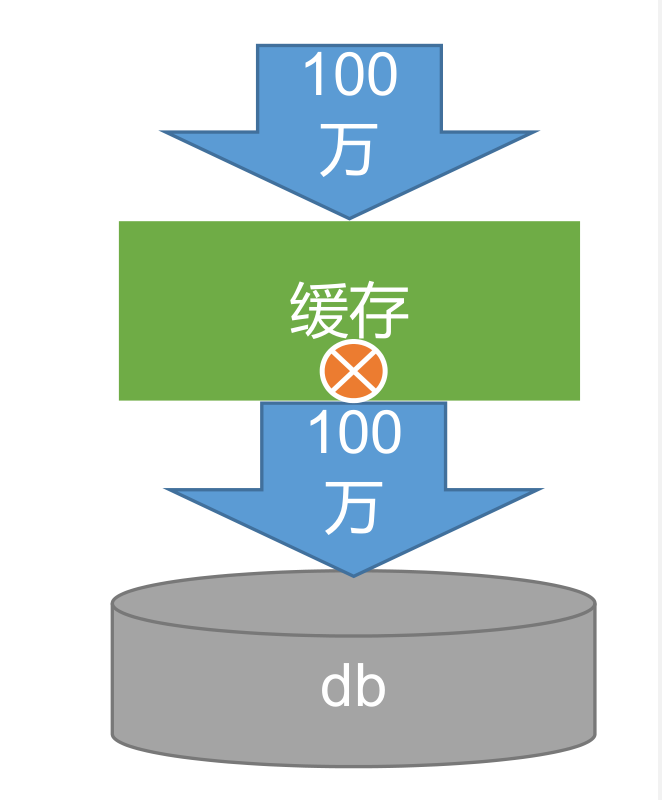
- 对于一些设置了过期时间的 key,如果这些 key 可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。
- 这个时候,需要考虑一个问题:如果这个 key 在大量请求同时进来前正好失效,那么所有对这个 key 的数据查询都落到 db,我们称为缓存击穿。
- 解决:
- 加锁
- 大量并发只让一个去查,其他人等待,查到以后释放锁,其他人获取到锁,先查缓存,就会有数据,不用去db
- 加锁
三、缓存数据一致性
1、缓存数据一致性 - 双写模式
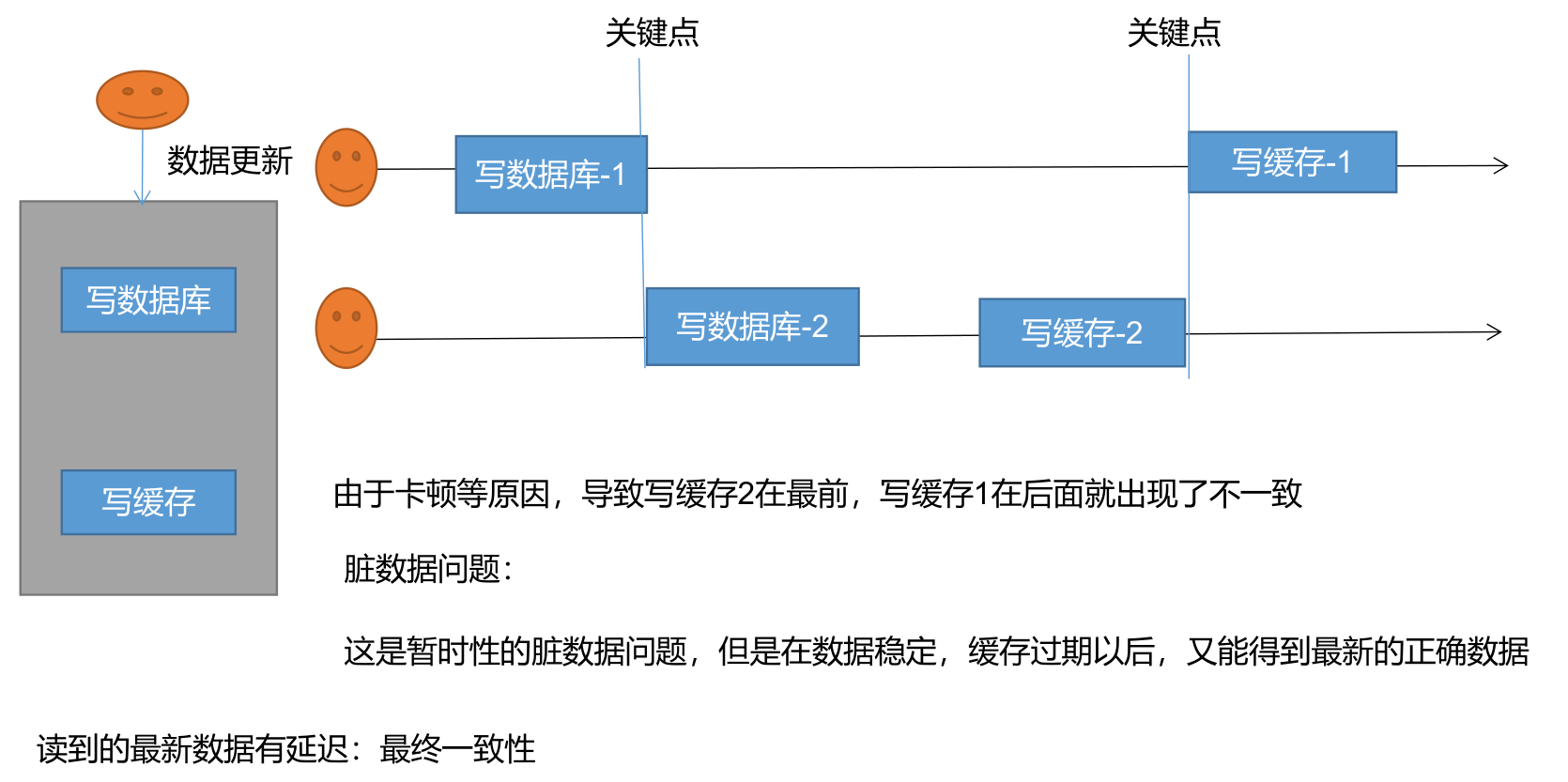
如何保证数据库和缓存双写一致性?
数据库和缓存(比如:redis)双写数据一致性问题,是一个跟开发语言无关的公共问题。尤其在高并发的场景下,这个问题变得更加严重。
我很负责的告诉你,该问题无论在面试,还是工作中遇到的概率非常大,所以非常有必要跟大家一起探讨一下。
今天这篇文章我会从浅入深,跟大家一起聊聊,数据库和缓存双写数据一致性问题常见的解决方案,这些方案中可能存在的坑,以及最优方案是什么。
1.常见方案
- 通常情况下,我们使用缓存的主要目的是为了提升查询的性能。
- 大多数情况下,我们是这样使用缓存的:
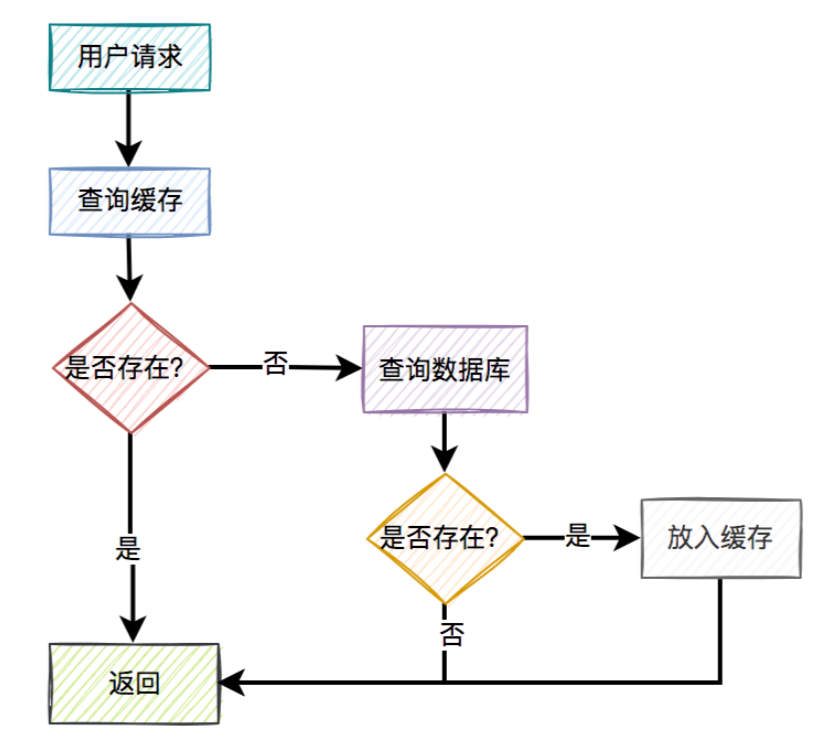
- 用户请求过来之后,先查缓存有没有数据,如果有则直接返回。
- 如果缓存没数据,再继续查数据库。
- 如果数据库有数据,则将查询出来的数据,放入缓存中,然后返回该数据。
- 如果数据库也没数据,则直接返回空。
- 这是缓存非常常见的用法。一眼看上去,好像没有啥问题。
- 但你忽略了一个非常重要的细节:如果数据库中的某条数据,放入缓存之后,又立马被更新了,那么该如何更新缓存呢?
- 不更新缓存行不行?
- 答:当然不行,如果不更新缓存,在很长的一段时间内(决定于缓存的过期时间),用户请求从缓存中获取到的都可能是旧值,而非数据库的最新值。这不是有数据不一致的问题?
- 那么,我们该如何更新缓存呢?
- 目前有以下4种方案:
- 先写缓存,再写数据库
- 先写数据库,再写缓存
- 先删缓存,再写数据库
- 先写数据库,再删缓存
- 目前有以下4种方案:
接下来,我们详细说说这4种方案。
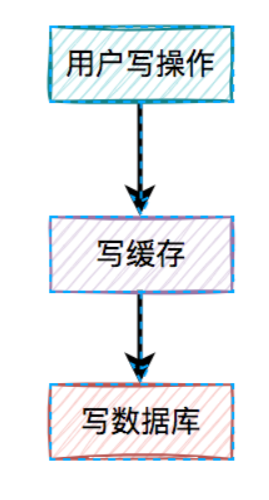
2.先写缓存,再写数据库
对于更新缓存的方案,很多人第一个想到的可能是在写操作中直接更新缓存(写缓存),更直接明了。
那么,问题来了:在写操作中,到底是先写缓存,还是先写数据库呢?
我们在这里先聊聊先写缓存,再写数据库的情况,因为它的问题最严重。
某一个用户的每一次写操作,如果刚写完缓存,突然网络出现了异常,导致写数据库失败了。
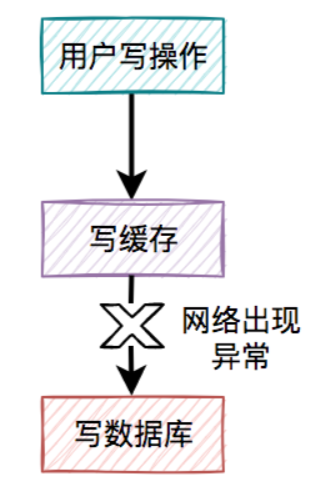
- 其结果是缓存更新成了最新数据,但数据库没有,这样缓存中的数据不就变成脏数据了?如果此时该用户的查询请求,正好读取到该数据,就会出现问题,因为该数据在数据库中根本不存在,这个问题非常严重。
- 我们都知道,缓存的主要目的是把数据库的数据临时保存在内存,便于后续的查询,提升查询速度。
- 但如果某条数据,在数据库中都不存在,你缓存这种“
假数据”又有啥意义呢?- 因此,先写缓存,再写数据库的方案是不可取的,在实际工作中用得不多。
3.先写数据库,再写缓存
- 既然上面的方案行不通,接下来,聊聊先写数据库,再写缓存的方案,该方案在低并发编程中有人在用(我猜的)。
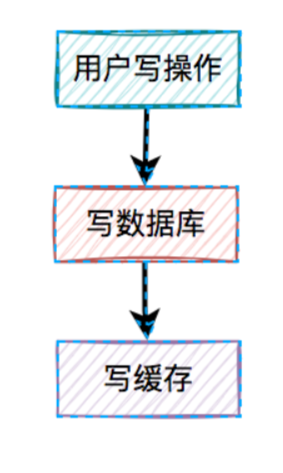
用户的写操作,先写数据库,再写缓存,可以避免之前“假数据”的问题。但它却带来了新的问题。
什么问题呢?
写缓存失败了
高并发下的问题
浪费系统资源
3.1 写缓存失败了
- 如果把写数据库和写缓存操作,放在同一个事务当中,当写缓存失败了,我们可以把写入数据库的数据进行回滚。
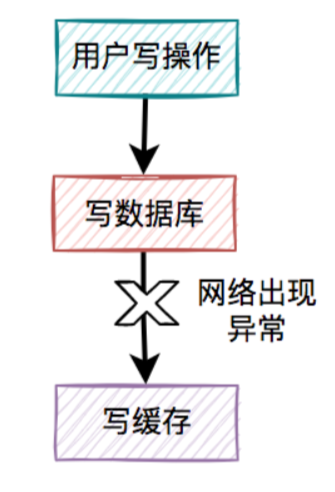
- 如果是并发量比较小,对接口性能要求不太高的系统,可以这么玩。
- 但如果在高并发的业务场景中,写数据库和写缓存,都属于远程操作。为了防止出现大事务,造成的死锁问题,通常建议写数据库和写缓存不要放在同一个事务中。
- 也就是说在该方案中,如果写数据库成功了,但写缓存失败了,数据库中已写入的数据不会回滚。
- 这就会出现:数据库是
新数据,而缓存是旧数据,两边数据不一致的情况。
3.2 高并发下的问题
假设在高并发的场景中,针对同一个用户的同一条数据,有两个写数据请求:a和b,它们同时请求到业务系统。
其中请求a获取的是旧数据,而请求b获取的是新数据,如下图所示:
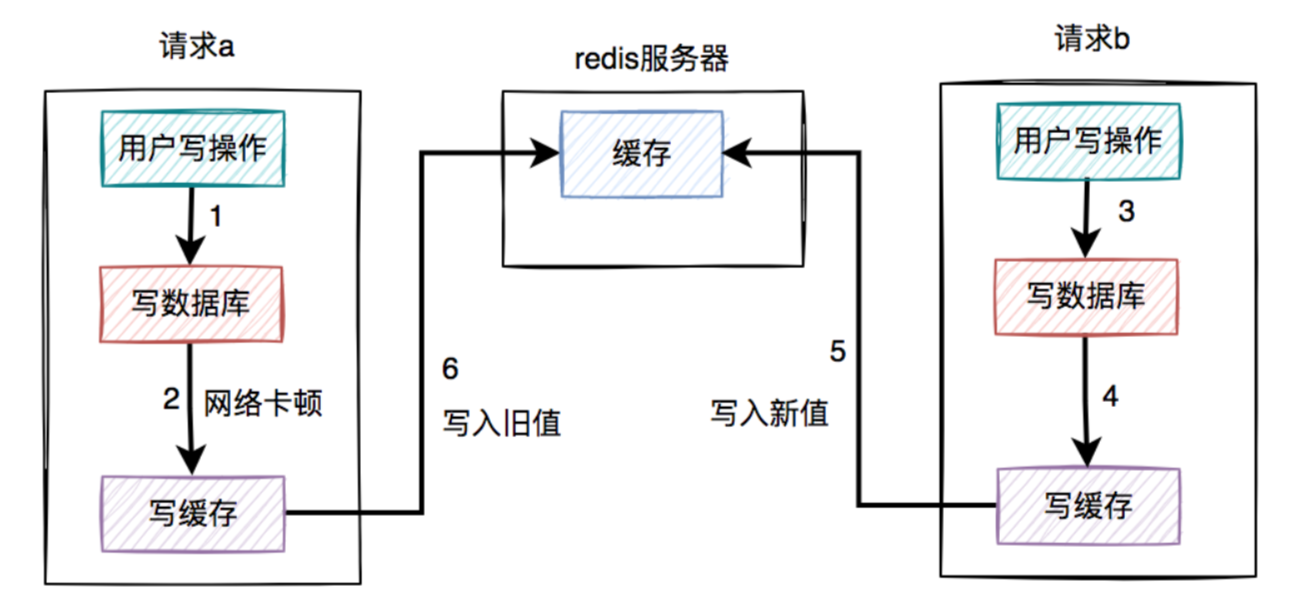
- 请求a先过来,刚写完了数据库。但由于网络原因,卡顿了一下,还没来得及写缓存。
- 这时候请求b过来了,先写了数据库。
- 接下来,请求b顺利写了缓存。
- 此时,请求a卡顿结束,也写了缓存。
- 很显然,在这个过程当中,请求b在缓存中的
新数据,被请求a的旧数据覆盖了。- 也就是说:在高并发场景中,如果多个线程同时执行先写数据库,再写缓存的操作,可能会出现数据库是新值,而缓存中是旧值,两边数据不一致的情况。
3.3 浪费系统资源
该方案还有一个比较大的问题就是:每个写操作,写完数据库,会马上写缓存,比较浪费系统资源。
为什么这么说呢?
你可以试想一下,如果写的缓存,并不是简单的数据内容,而是要经过非常复杂的计算得出的最终结果。这样每写一次缓存,都需要经过一次非常复杂的计算,不是非常浪费系统资源吗?
尤其是cpu和内存资源。
还有些业务场景比较特殊:写多读少。
如果在这类业务场景中,每个用的写操作,都需要写一次缓存,有点得不偿失。
由此可见,在高并发的场景中,先写数据库,再写缓存,这套方案问题挺多的,也不太建议使用。
如果你已经用了,赶紧看看踩坑了没?
4.先删缓存,再写数据库
通过上面的内容我们得知,如果直接更新缓存的问题很多。
那么,为何我们不能换一种思路:不去直接更新缓存,而改为删除缓存呢?
删除缓存方案,同样有两种:
- 先删缓存,再写数据库
- 先写数据库,再删缓存
我们一起先看看:先删缓存,再写数据库的情况。
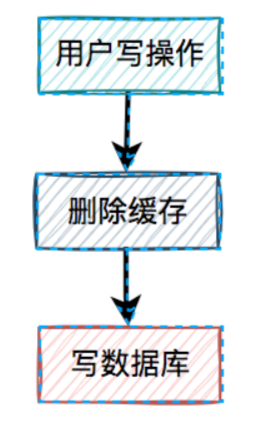
说白了,在用户的写操作中,先执行删除缓存操作,再去写数据库。这套方案,可以是可以,但也会有一样问题。
4.1 高并发下的问题
- 假设在高并发的场景中,同一个用户的同一条数据,有一个读数据请求c,还有另一个写数据请求d(一个更新操作),同时请求到业务系统。如下图所示:
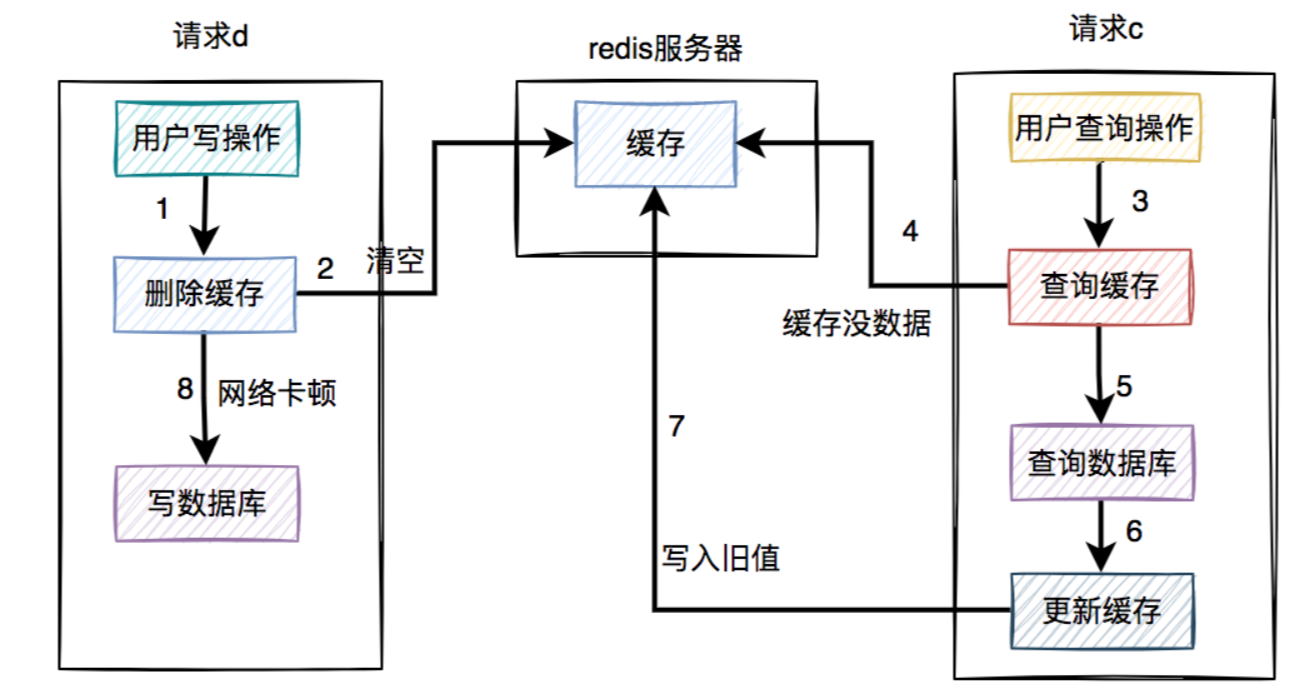
- 请求d先过来,把缓存删除了。但由于网络原因,卡顿了一下,还没来得及写数据库。
- 这时请求c过来了,先查缓存发现没数据,再查数据库,有数据,但是旧值。
- 请求c将数据库中的旧值,更新到缓存中。
- 此时,请求d卡顿结束,把新值写入数据库。
- 在这个过程当中,请求d的新值并没有被请求c写入缓存,同样会导致缓存和数据库的数据不一致的情况。
- 那么,这种场景的数据不一致问题,能否解决呢?
- 缓存双删
4.2 缓存双删
在上面的业务场景中,一个读数据请求,一个写数据请求。当写数据请求把缓存删了之后,读数据请求,可能把当时从数据库查询出来的旧值,写入缓存当中。
有人说还不好办,请求d在写完数据库之后,把缓存重新删一次不就行了?
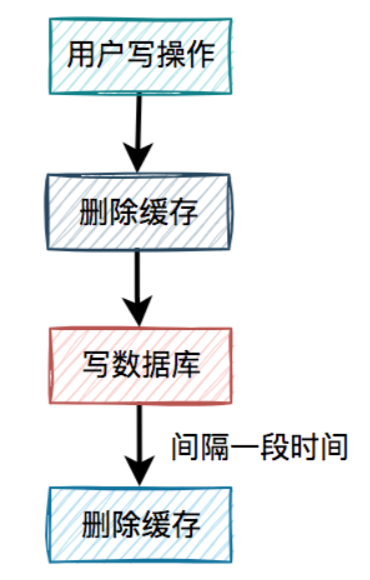
这就是我们所说的缓存双删,即在写数据库之前删除一次,写完数据库后,再删除一次。
该方案有个非常关键的地方是:第二次删除缓存,并非立马就删,而是要在一定的时间间隔之后。
我们再重新回顾一下,高并发下一个读数据请求,一个写数据请求导致数据不一致的产生过程:
- 请求d先过来,把缓存删除了。但由于网络原因,卡顿了一下,还没来得及写数据库。
- 这时请求c过来了,先查缓存发现没数据,再查数据库,有数据,但是旧值。
- 请求c将数据库中的旧值,更新到缓存中。
- 此时,请求d卡顿结束,把新值写入数据库。
- 一段时间之后,比如:500ms,请求d将缓存删除。
这样来看确实可以解决缓存不一致问题。
那么,为什么一定要间隔一段时间之后,才能删除缓存呢?
请求d卡顿结束,把新值写入数据库后,请求c将数据库中的旧值,更新到缓存中。
此时,如果请求d删除太快,在请求c将数据库中的旧值更新到缓存之前,就已经把缓存删除了,这次删除就没任何意义。必须要在请求c更新缓存之后,再删除缓存,才能把旧值及时删除了。
所以需要在请求d中加一个时间间隔,确保请求c,或者类似于请求c的其他请求,如果在缓存中设置了旧值,最终都能够被请求d删除掉。
接下来,还有一个问题:如果第二次删除缓存时,删除失败了该怎么办?
这里先留点悬念,后面会详细说。
5.先写数据库,再删缓存
- 从前面得知,先删缓存,再写数据库,在并发的情况下,也可能会出现缓存和数据库的数据不一致的情况。
- 那么,我们只能寄希望于最后的方案了。
- 接下来,我们重点看看先写数据库,再删缓存的方案。
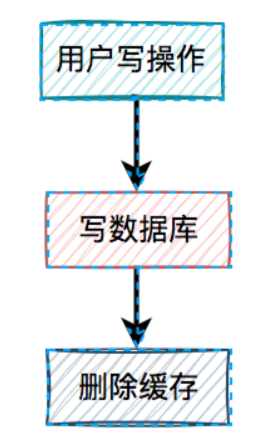
- 在高并发的场景中,有一个读数据请求,有一个写数据请求,更新过程如下:
- 请求e先写数据库,由于网络原因卡顿了一下,没有来得及删除缓存。
- 请求f查询缓存,发现缓存中有数据,直接返回该数据。
- 请求e删除缓存。
- 在这个过程中,只有请求f读了一次旧数据,后来旧数据被请求e及时删除了,看起来问题不大。
- 但如果是读数据请求先过来呢?
- 请求f查询缓存,发现缓存中有数据,直接返回该数据。
- 请求e先写数据库。
- 请求e删除缓存。
- 这种情况看起来也没问题呀?
- 答:对的。
- 但就怕出现下面这种情况,即缓存自己失效了。如下图所示:
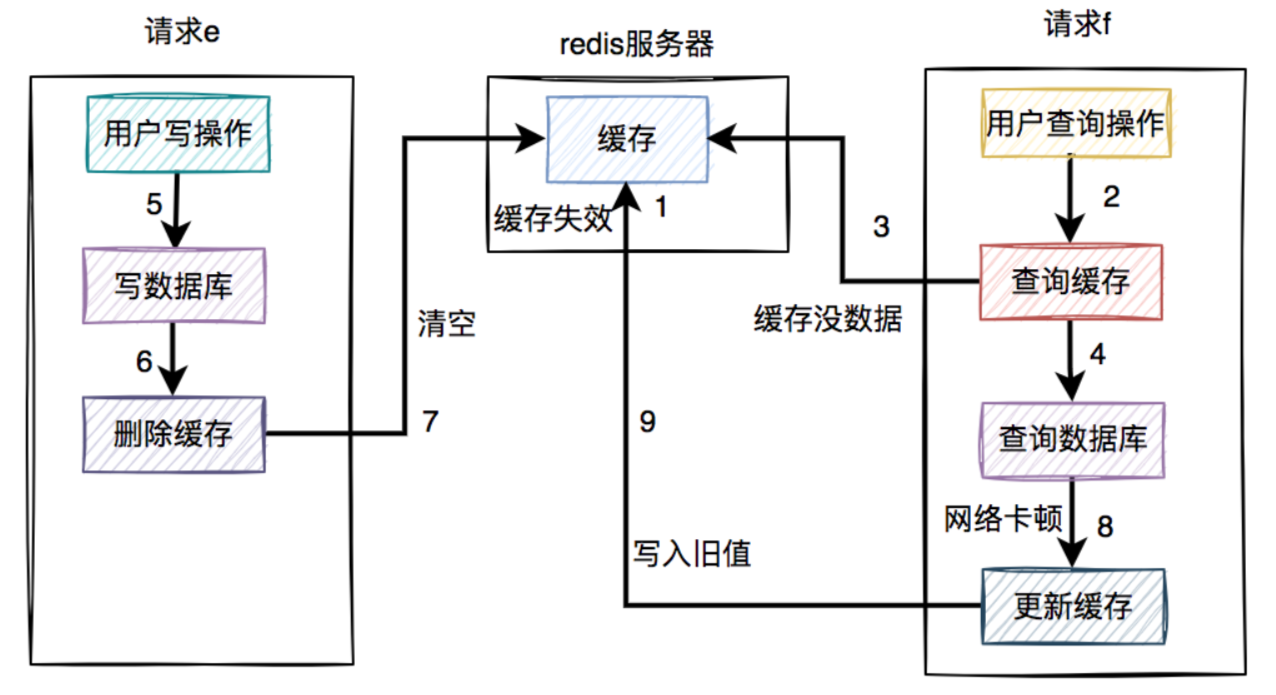
- 缓存过期时间到了,自动失效。
- 请求f查询缓存,发缓存中没有数据,查询数据库的旧值,但由于网络原因卡顿了,没有来得及更新缓存。
- 请求e先写数据库,接着删除了缓存。
- 请求f更新旧值到缓存中。
这时,缓存和数据库的数据同样出现不一致的情况了。
但这种情况还是比较少的,需要同时满足以下条件才可以:
- 缓存刚好自动失效。
- 请求f从数据库查出旧值,更新缓存的耗时,比请求e写数据库,并且删除缓存的还长。
我们都知道查询数据库的速度,一般比写数据库要快,更何况写完数据库,还要删除缓存。所以绝大多数情况下,写数据请求比读数据情况耗时更长。
由此可见,系统同时满足上述两个条件的概率非常小。
推荐大家使用先写数据库,再删缓存的方案,虽说不能100%避免数据不一致问题,但出现该问题的概率,相对于其他方案来说是最小的。
- 但在该方案中,如果删除缓存失败了该怎么办呢?
6.删缓存失败怎么办?
- 其实先写数据库,再删缓存的方案,跟缓存双删的方案一样,有一个共同的风险点,即:如果缓存删除失败了,也会导致缓存和数据库的数据不一致。
- 那么,删除缓存失败怎么办呢?
- 答:需要加
重试机制。
- 答:需要加
- 在接口中如果更新了数据库成功了,但更新缓存失败了,可以立刻重试3次。如果其中有任何一次成功,则直接返回成功。如果3次都失败了,则写入数据库,准备后续再处理。
- 当然,如果你在接口中直接
同步重试,该接口并发量比较高的时候,可能有点影响接口性能。 - 这时,就需要改成
异步重试了。 - 异步重试方式有很多种,比如:
- 每次都单独起一个线程,该线程专门做重试的工作。但如果在高并发的场景下,可能会创建太多的线程,导致系统OOM问题,不太建议使用。
- 将重试的任务交给线程池处理,但如果服务器重启,部分数据可能会丢失。
- 将重试数据写表,然后使用elastic-job等定时任务进行重试。
- 将重试的请求写入mq等消息中间件中,在mq的consumer中处理。
- 订阅mysql的binlog,在订阅者中,如果发现了更新数据请求,则删除相应的缓存。
7.定时任务
- 使用定时任务重试的具体方案如下:
- 当用户操作写完数据库,但删除缓存失败了,需要将用户数据写入重试表中。如下图所示:
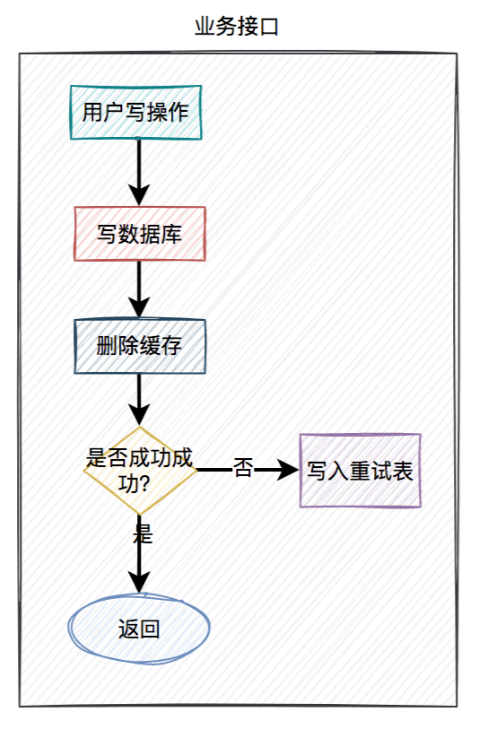
- 在定时任务中,异步读取重试表中的用户数据。重试表需要记录一个重试次数字段,初始值为0。然后重试5次,不断删除缓存,每重试一次该字段值+1。如果其中有任意一次成功了,则返回成功。如果重试了5次,还是失败,则我们需要在重试表中记录一个失败的状态,等待后续进一步处理。
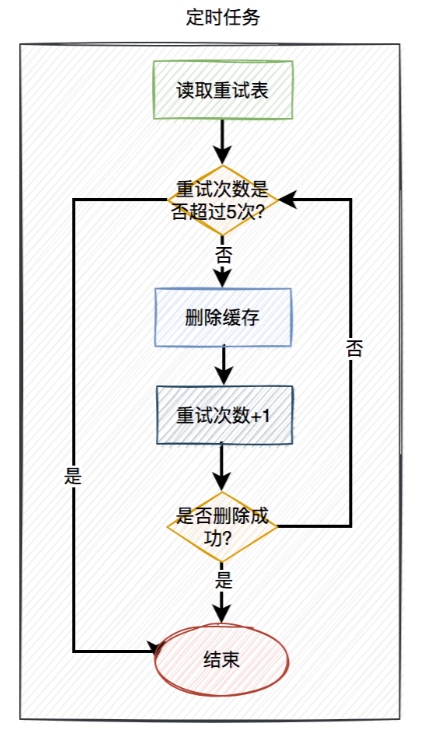
- 在高并发场景中,定时任务推荐使用
elastic-job。相对于xxl-job等定时任务,它可以分片处理,提升处理速度。同时每片的间隔可以设置成:1,2,3,5,7秒等。
- 如果大家对定时任务比较感兴趣的话,可以看看我的另一篇文章《学会这10种定时任务,我有点飘了》,里面列出了目前最主流的定时任务。
- 使用定时任务重试的话,有个缺点就是实时性没那么高,对于实时性要求特别高的业务场景,该方案不太适用。但是对于一般场景,还是可以用一用的。
- 但它有一个很大的优点,即数据是落库的,不会丢数据。
8.mq
- 在高并发的业务场景中,mq(消息队列)是必不可少的技术之一。它不仅可以异步解耦,还能削峰填谷。对保证系统的稳定性是非常有意义的。
- 对mq有兴趣的朋友可以看看我的另一篇文章《mq的那些破事儿》。
- mq的生产者,生产了消息之后,通过指定的topic发送到mq服务器。然后mq的消费者,订阅该topic的消息,读取消息数据之后,做业务逻辑处理。
- 使用mq重试的具体方案如下:
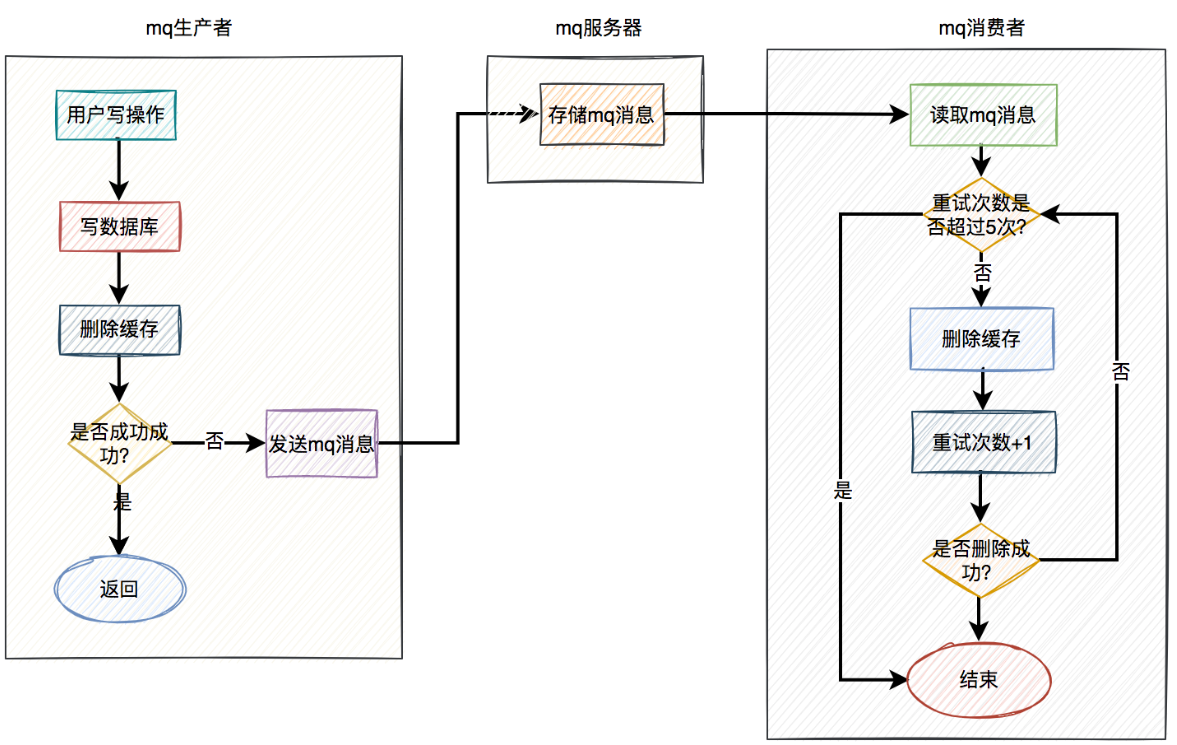
- 当用户操作写完数据库,但删除缓存失败了,产生一条mq消息,发送给mq服务器。
- mq消费者读取mq消息,重试5次删除缓存。如果其中有任意一次成功了,则返回成功。如果重试了5次,还是失败,则写入死信队列中。
- 推荐mq使用rocketmq,重试机制和死信队列默认是支持的。使用起来非常方便,而且还支持顺序消息,延迟消息和事务消息等多种业务场景。
- 当然在该方案中,删除缓存可以完全走异步。即用户的写操作,在写完数据库之后,不用立刻删除一次缓存。而直接发送mq消息,到mq服务器,然后有mq消费者全权负责删除缓存的任务。
- 因为mq的实时性还是比较高的,因此改良后的方案也是一种不错的选择。
9.binlog
- 前面我们聊过的,无论是定时任务,还是mq(消息队列),做重试机制,对业务都有一定的侵入性。
- 在使用定时任务的方案中,需要在业务代码中增加额外逻辑,如果删除缓存失败,需要将数据写入重试表。
- 而使用mq的方案中,如果删除缓存失败了,需要在业务代码中发送mq消息到mq服务器。
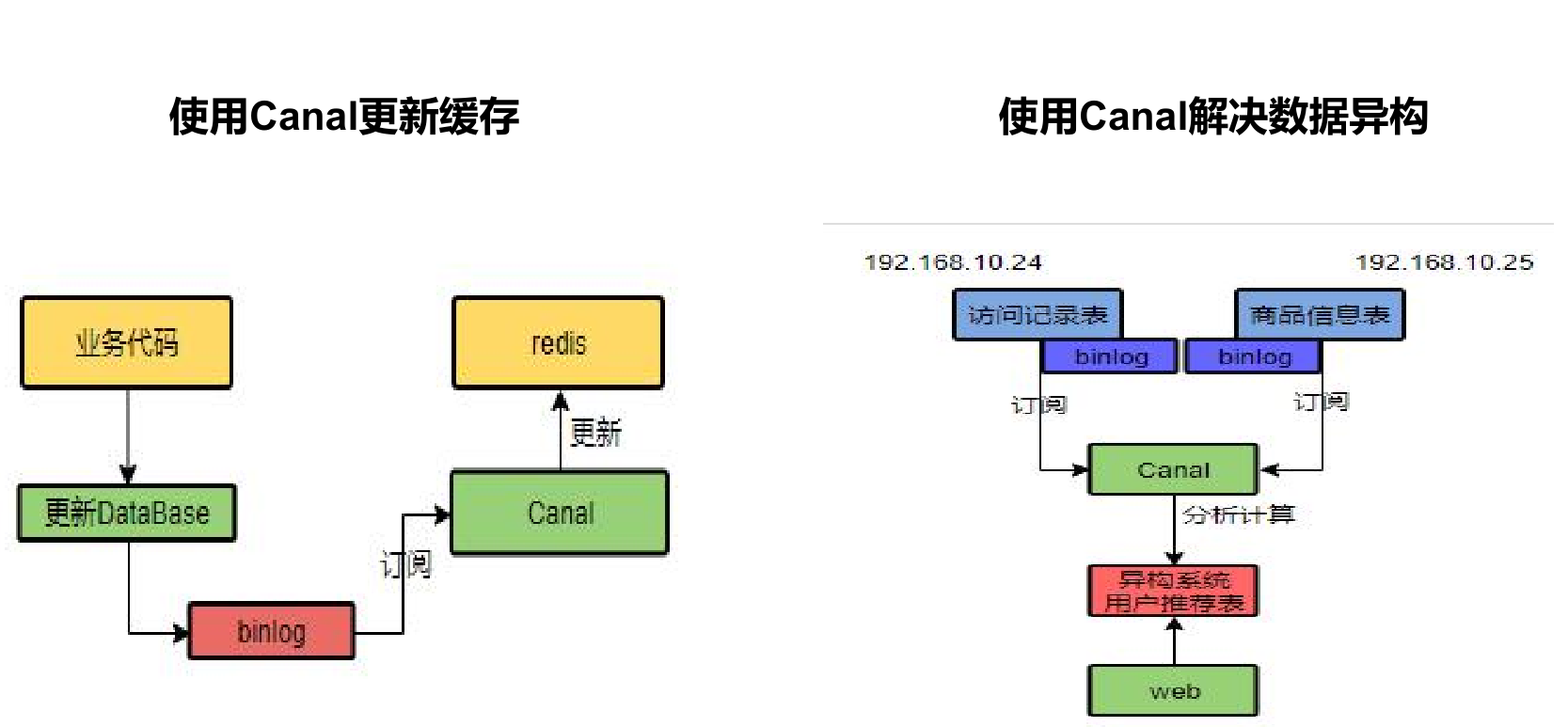
- 其实,还有一种更优雅的实现,即监听binlog,比如使用:canal等中间件。
- 具体方案如下:
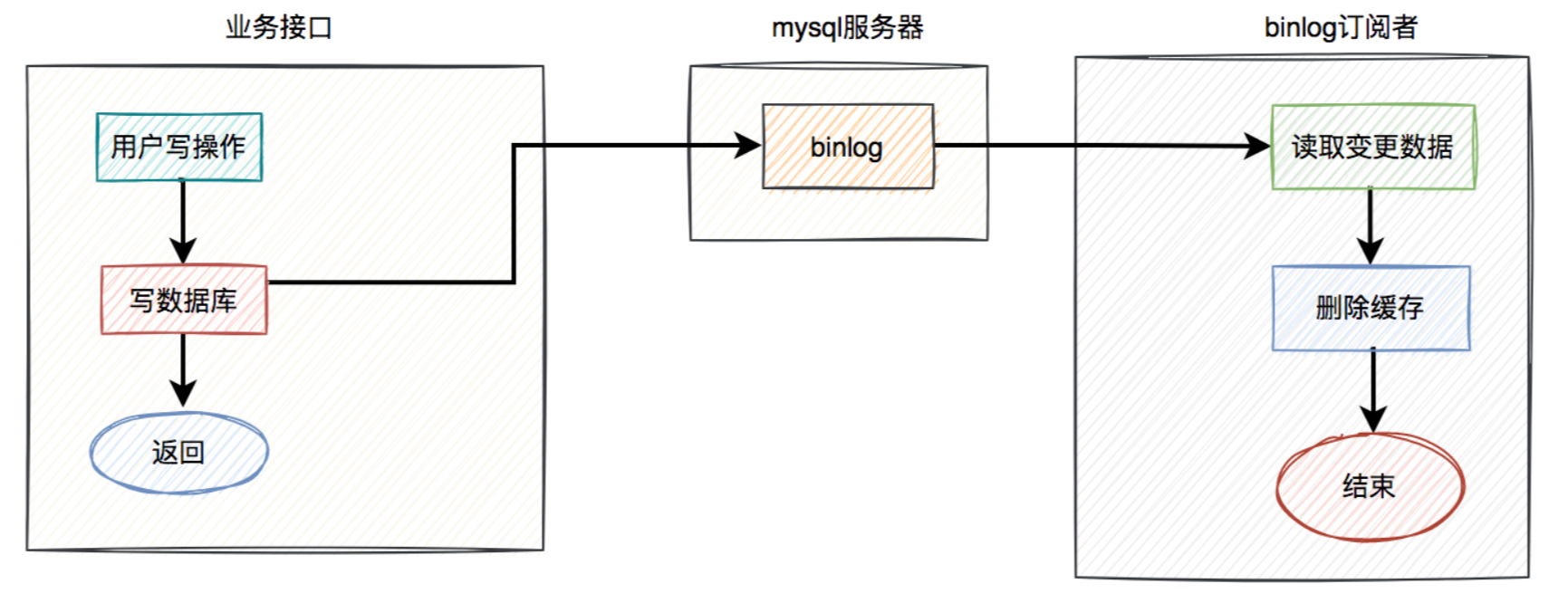
- 在业务接口中写数据库之后,就不管了,直接返回成功。
- mysql服务器会自动把变更的数据写入binlog中。
- binlog订阅者获取变更的数据,然后删除缓存。
- 这套方案中业务接口确实简化了一些流程,只用关心数据库操作即可,而在binlog订阅者中做缓存删除工作。
- 但如果只是按照图中的方案进行删除缓存,只删除了一次,也可能会失败。
- 如何解决这个问题呢?
- 答:这就需要加上前面聊过的
重试机制了。如果删除缓存失败,写入重试表,使用定时任务重试。或者写入mq,让mq自动重试。
- 答:这就需要加上前面聊过的
- 在这里推荐使用mq
自动重试机制。
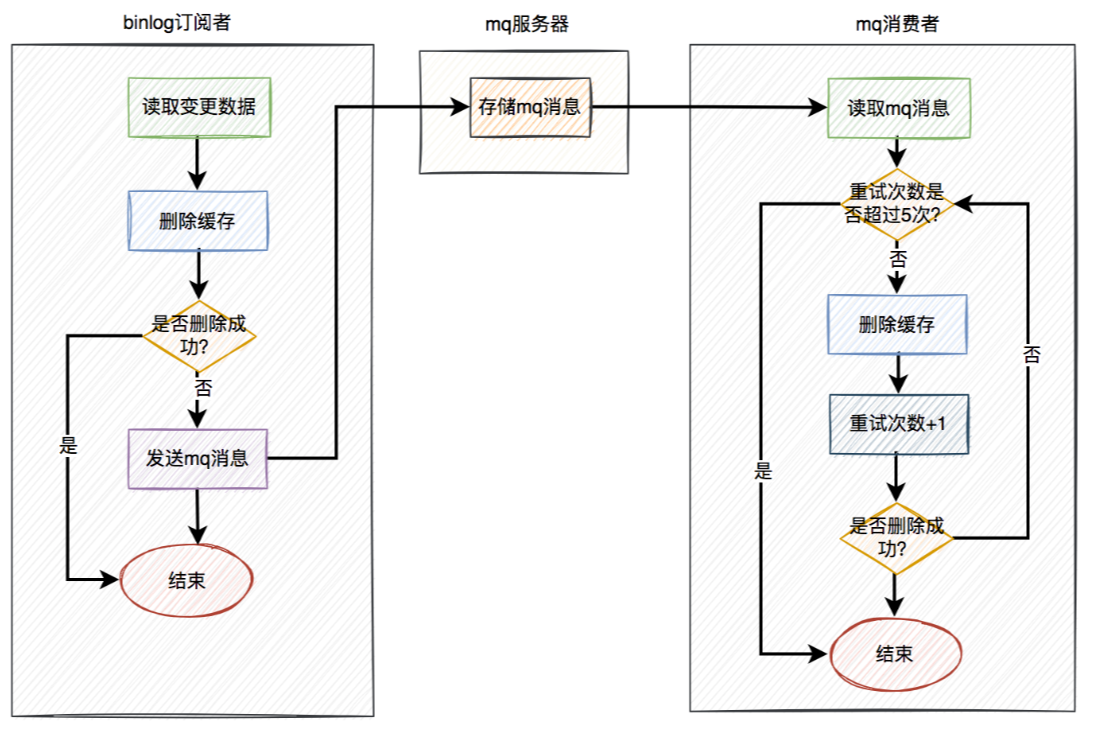
在binlog订阅者中如果删除缓存失败,则发送一条mq消息到mq服务器,在mq消费者中自动重试5次。如果有任意一次成功,则直接返回成功。如果重试5次后还是失败,则该消息自动被放入死信队列,后面可能需要人工介入。
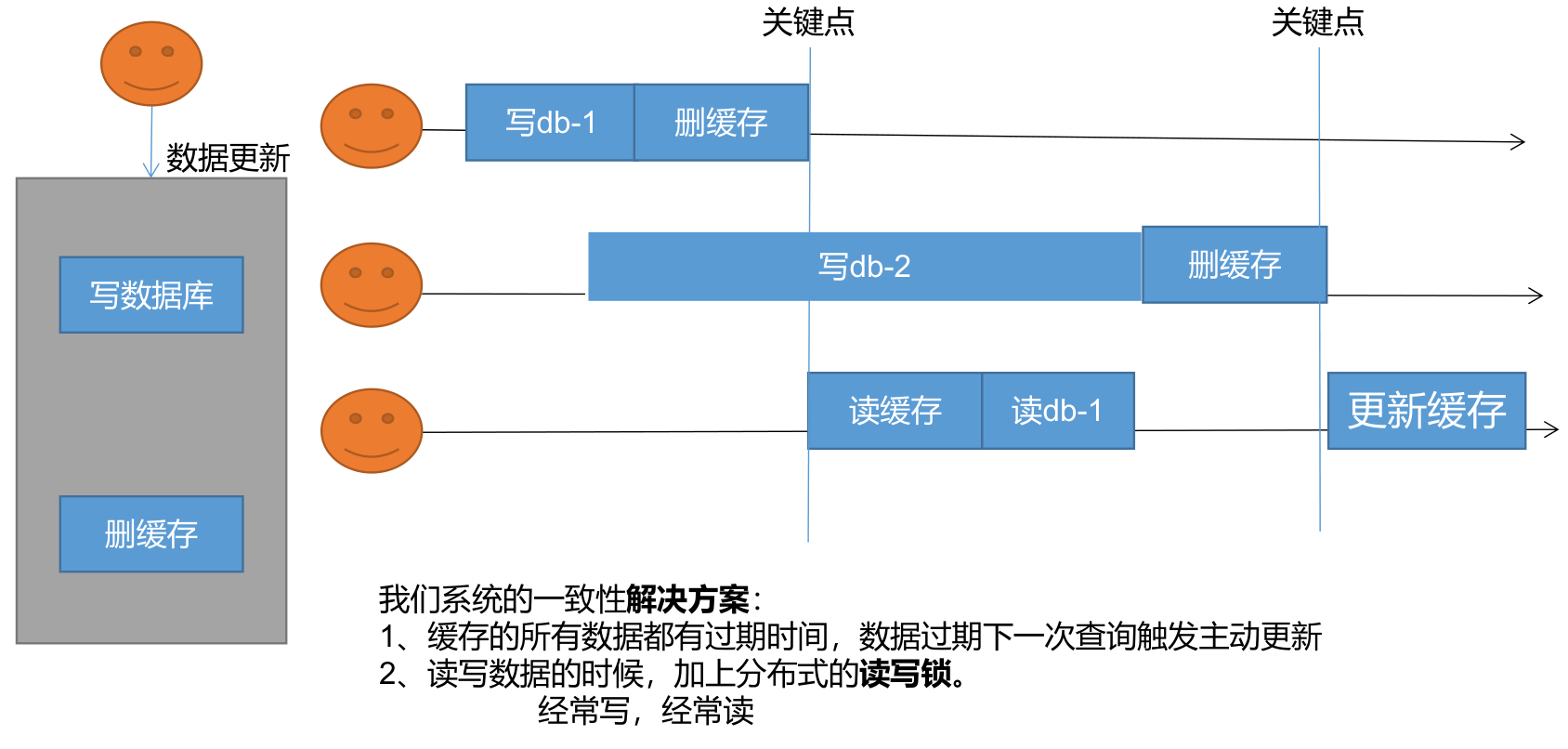
2、缓存数据一致性 - 失效模式
3、缓存数据一致性 - 解决方案
- 无论是双写模式还是失效模式,都会导致缓存的不一致问题。即多个实例同时更新会出事。怎么办?
- 1、如果是用户纬度数据(订单数据、用户数据),这种并发几率非常小,不用考虑这个问题,缓存数据加上过期时间,每隔一段时间触发读的主动更新即可
- 2、如果是菜单,商品介绍等基础数据,也可以去使用canal订阅binlog的方式。
- 3、缓存数据+过期时间也足够解决大部分业务对于缓存的要求。
- 4、通过加锁保证并发读写,写写的时候按顺序排好队。读读无所谓。所以适合使用读写锁。(业务不关心脏数据,允许临时脏数据可忽略);
- 总结:
- 我们能放入缓存的数据本就不应该是实时性、一致性要求超高的。所以缓存数据的时候加上过期时间,保证每天拿到当前最新数据即可。
- 我们不应该过度设计,增加系统的复杂性
- 遇到实时性、一致性要求高的数据,就应该查数据库,即使慢点。
4、缓存数据一致性 - 解决-Canal
四、分布式锁
1、分布式锁与本地锁
org.klaus.zgg01mall.product.service.impl.CategoryServiceImpl#getDataFromDb- 抽取业务方法方便加锁
/**
* 抽取业务方法
*
* @return
*/
private Map<String, List<Catalog2Vo>> getDataFromDb() {
//获取缓存
String catalogJson = stringRedisTemplate.opsForValue().get("catalogJson");
if (!StringUtils.isEmpty(catalogJson)) {
//缓存不为空直接返回
Map<String, List<Catalog2Vo>> result = JSON.parseObject(catalogJson, new TypeReference<Map<String, List<Catalog2Vo>>>() {
});
return result;
}
System.out.println("查询了数据库。。。");
/**
* 缓存为空,进行查询业务
* 1、将数据库的多次查询变为一次,即方法抽取
*/
//查询所有
List<CategoryEntity> selectList = baseMapper.selectList(null);
//1、查出所有1级分类 父分类集合,一级分类父分类id为0
List<CategoryEntity> level1Categorys = getParent_cid(selectList, 0L);
//2、封装数据
Map<String, List<Catalog2Vo>> map = level1Categorys.stream().collect(Collectors.toMap(
//"pCId":"c2{}"
k -> k.getCatId().toString(),
v -> {
//2.1、每一个的一级分类,查到这个一级分类的[二级分类]
//得到二级分类实体集合 抽取查询方法-> baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("parent_cid", v.getCatId()));
//todo 父分类集合, 当前分类id(v为当前遍历的一级分类)
List<CategoryEntity> catalog2Entities = getParent_cid(selectList, v.getCatId());
//2.2、封装上面的结果
List<Catalog2Vo> catalog2Vos = null;
//父分类不为空,即二级分类实体集合不为空
if (catalog2Entities != null) {
//遍历拿到每个二级分类集合
catalog2Vos = catalog2Entities.stream().map(l2 -> {
//封装二级分类vo数据
Catalog2Vo catalog2Vo = new Catalog2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName());
//2.2.1、找当前二级分类的三级分类封装成vo baseMapper.selectList(new QueryWrapper<CategoryEntity>(). eq("parent_cid", l2.getCatId()));
// (三级分类父分类)父分类集合, 当前分类id(l2为当前遍历的二级分类)
List<CategoryEntity> catalog3Entities = getParent_cid(selectList, l2.getCatId());
List<Catalog2Vo.Catalog3Vo> catalog3Vos = null;
if (catalog3Entities != null) {
catalog3Vos = catalog3Entities.stream().map(l3 -> {
//2.2.2、封装成指定格式
Catalog2Vo.Catalog3Vo catalog3Vo = new Catalog2Vo.Catalog3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());
return catalog3Vo;
}).collect(Collectors.toList());
catalog2Vo.setCatalog3List(catalog3Vos);
}
return catalog2Vo;
}).collect(Collectors.toList());
}
return catalog2Vos;
}));
//todo 3、查到的数据再放入缓存,将对象转为json放入缓存中
String s = JSON.toJSONString(map);
//将数据放入缓存
stringRedisTemplate.opsForValue().set("catalogJson", s, 1, TimeUnit.DAYS);
//将数据库查到的结果直接返回,即将数据库查到的结果放一份到缓存中并返回
return map;
}
/**
* 抽取获取父分类id的查询方法,优化三级分类数据获取,使得在压力测试中吞吐量有明显的提高;
* 查询数据库是影响吞吐量高低的重要因素之一,因此尽量减少数据库的查询
*
* @param selectList
* @param parent_cid
* @return
*/
private List<CategoryEntity> getParent_cid(List<CategoryEntity> selectList, Long parent_cid) {
//return baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("parent_cid", v.getCatId()));
//直接进行过滤得到当前遍历的父分类id为传入的父分类id
List<CategoryEntity> collect = selectList.stream().filter(item -> item.getParentCid().equals(parent_cid)).collect(Collectors.toList());
return collect;
}- 使用本地锁
/**
* 使用redis缓存的同时使用本地锁(同步锁)来执行业务
*
* @return
*/
public Map<String, List<Catalog2Vo>> getCatalogJsonFromDbWithLocalLock() {
//如果缓存中有就用缓存的
// Map<String, List<Catalog2Vo>> catalogJson = (Map<String, List<Catalog2Vo>>) cache.get("catalogJson");
// if (catalogJson.get("catalogJson") == null){
// //调用业务xxx
// //返回数据又放入缓存
// cache.put("catalogJson", parent_cid);
// }
// return catalogJson;
//只要是同一把锁,就能锁住需要的这个锁的所有线程
//1、synchronized (this):SpringBoot所有的组件在容器中都是单例的
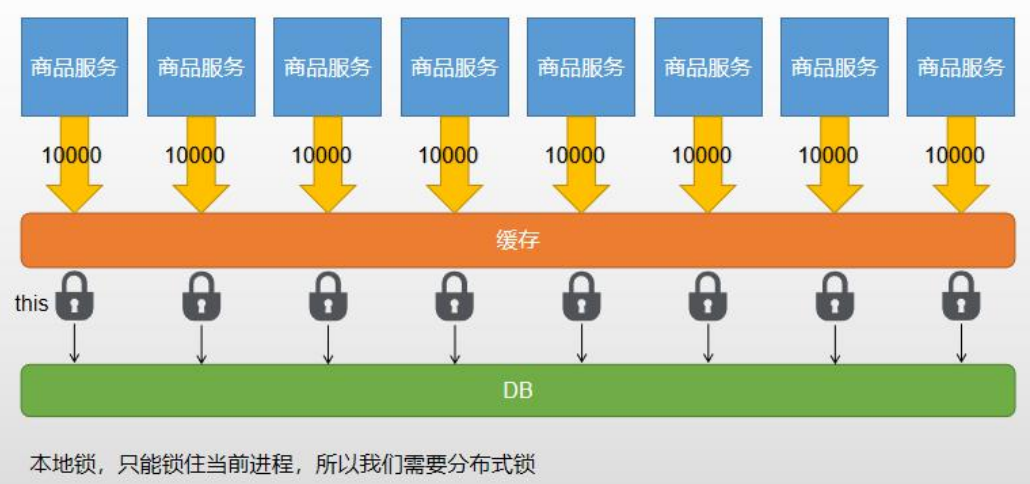
//todo 本地锁synchronized,JUC(Lock),在分布式情况下,想要锁住所有,必须使用分布式锁
//单实例的加锁,即本地锁只能锁住当前进程
synchronized (this) {
//得到锁以后,我们应该再去缓存中确定一次,如果没有才需要继续查询
return getDataFromDb();
}
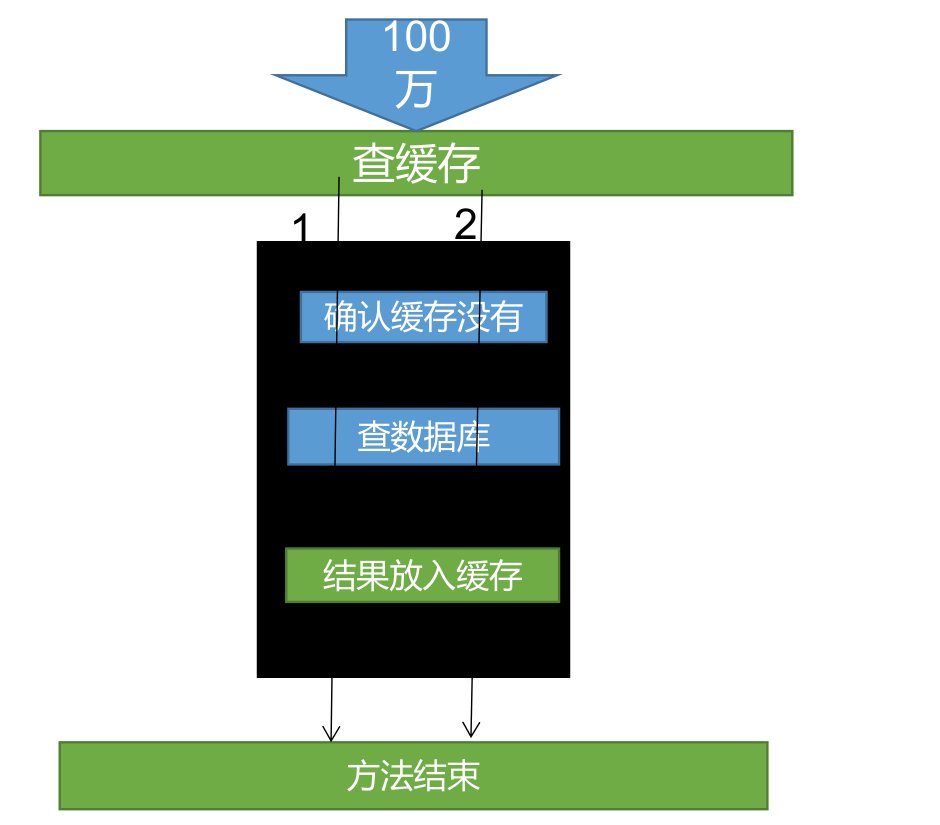
}锁-时序问题
2、分布式锁演进
分布式锁演进-基本原理
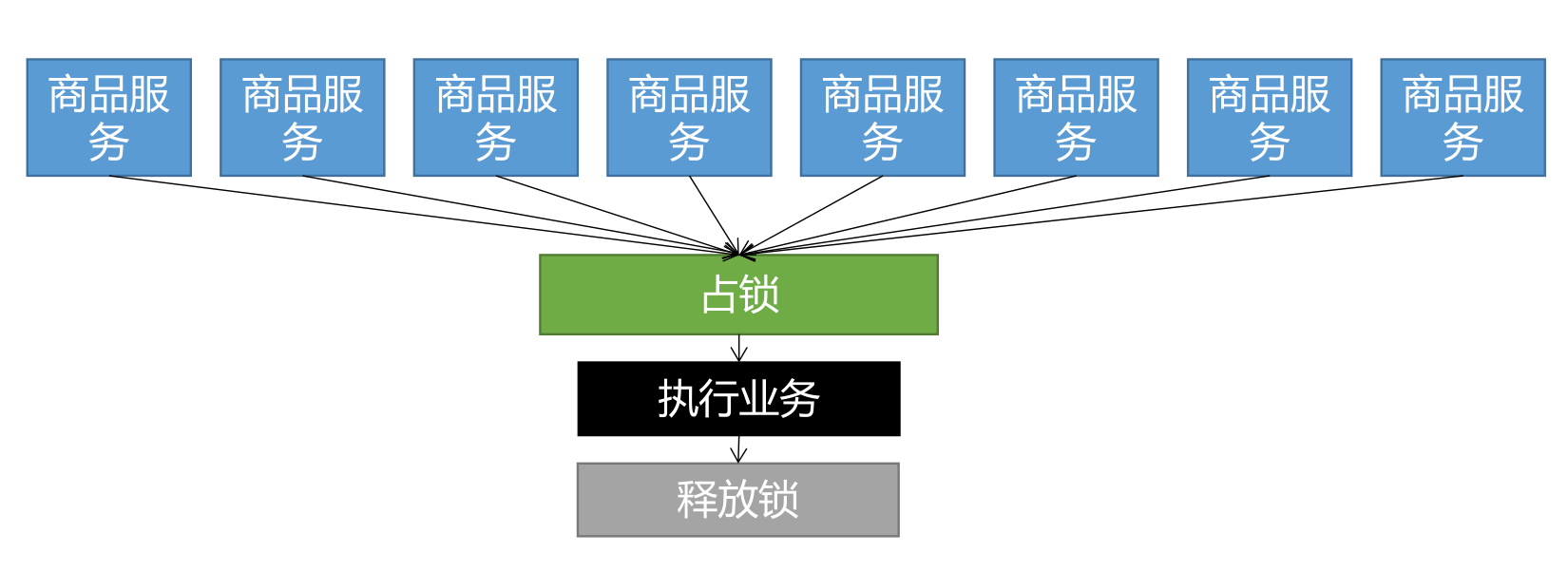
我们可以同时去一个地方“占坑”,如果占到,就执行逻辑。否则就必须等待,直到释放锁。 “占坑”可以去redis,可以去数据库,可以去任何大家都能访问的地方。 等待可以自旋的方式。
分布式锁演进-阶段一
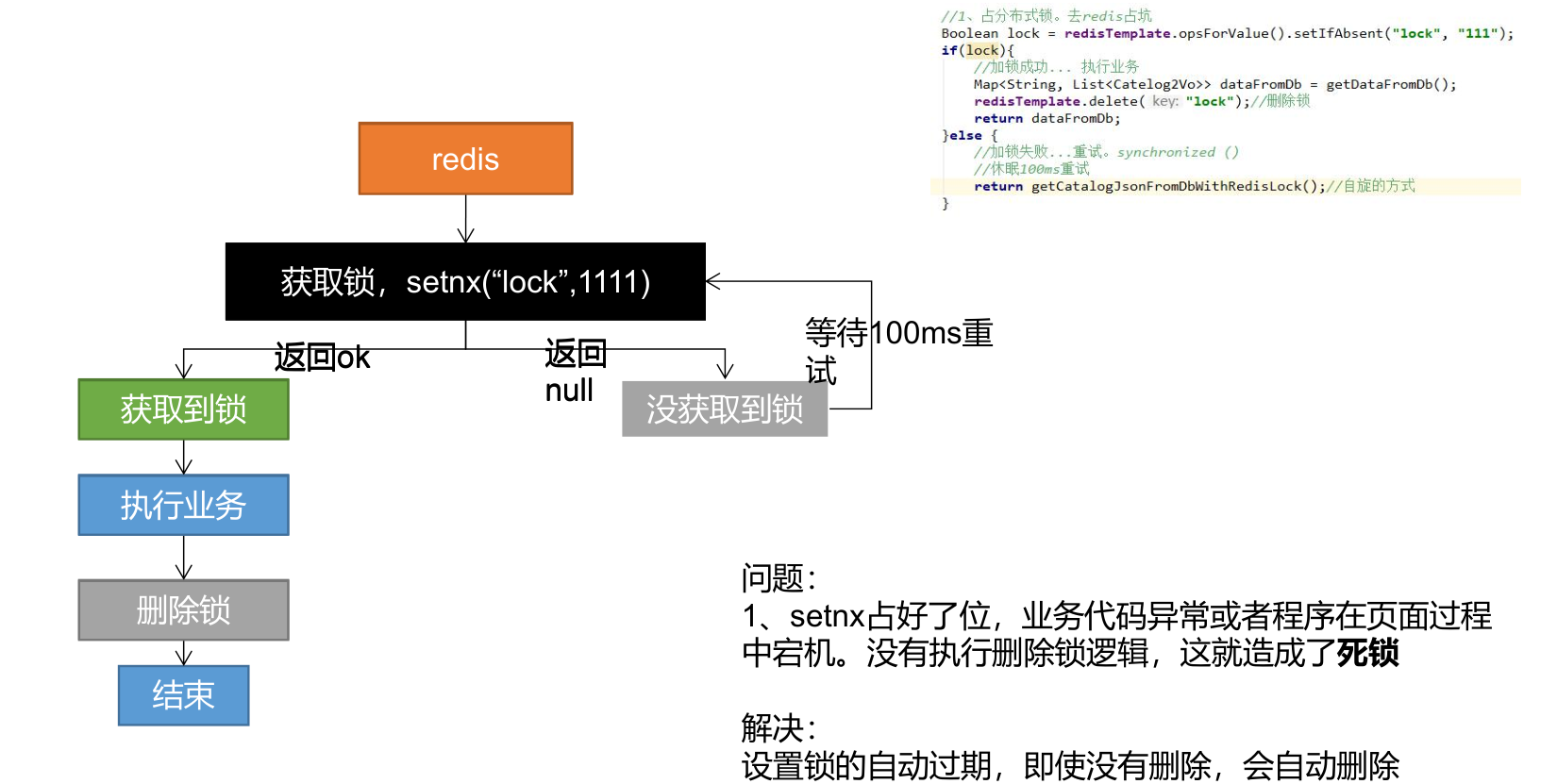
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", "0");
if (lock) {
// 加锁成功..执行业务
Map<String,List<Catelog2Vo>> dataFromDb = getDataFromDB();
redisTemplate.delete("lock"); // 删除锁
return dataFromDb;
} else {
// 加锁失败,重试 synchronized()
// 休眠100ms重试
return getCatelogJsonFromDbWithRedisLock();
}分布式锁演进-阶段二
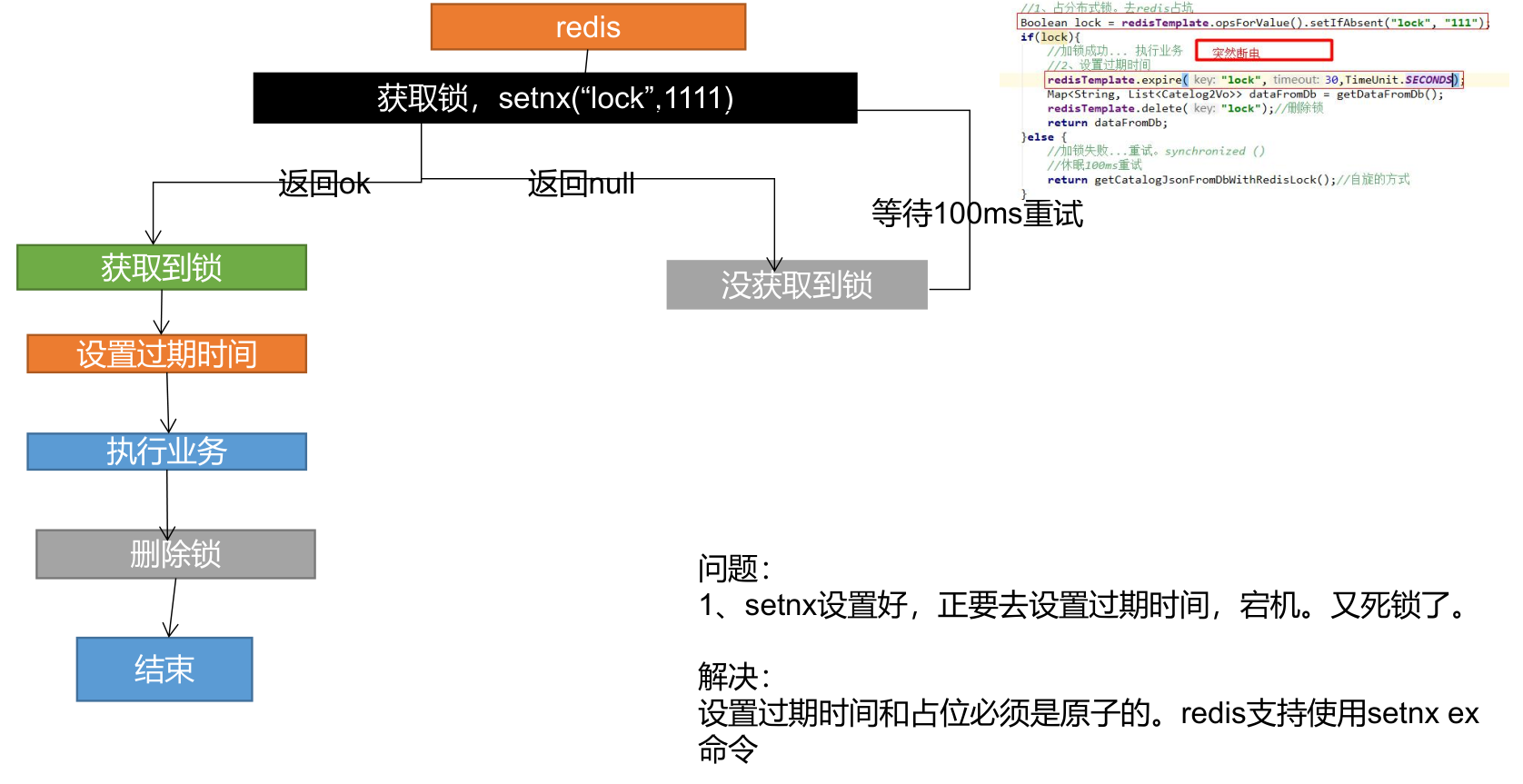
Boolean lock = redisTemplate.opsForValue().setIfAbsent()
if (lock) {
// 加锁成功..执行业务
// 设置过期时间
redisTemplate.expire("lock",30,TimeUnit.SECONDS);
Map<String,List<Catelog2Vo>> dataFromDb = getDataFromDB();
redisTemplate.delete("lock"); // 删除锁
return dataFromDb;
} else {
// 加锁失败,重试 synchronized()
// 休眠100ms重试
return getCatelogJsonFromDbWithRedisLock();
}分布式锁演进-阶段三
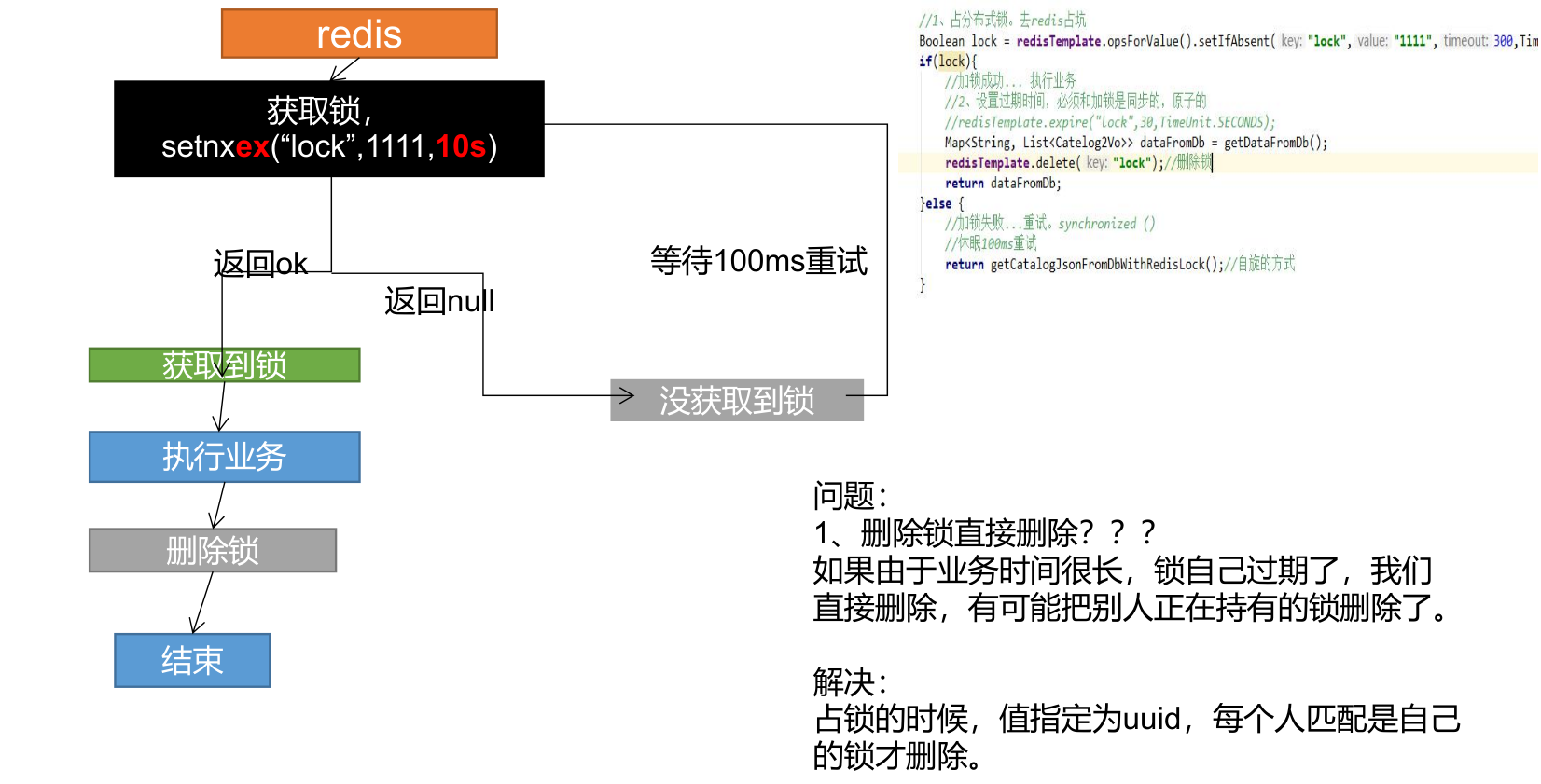
// 设置值同时设置过期时间
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock","111",300,TimeUnit.SECONDS);
if (lock) {
// 加锁成功..执行业务
// 设置过期时间,必须和加锁是同步的,原子的
redisTemplate.expire("lock",30,TimeUnit.SECONDS);
Map<String,List<Catelog2Vo>> dataFromDb = getDataFromDB();
redisTemplate.delete("lock"); // 删除锁
return dataFromDb;
} else {
// 加锁失败,重试 synchronized()
// 休眠100ms重试
return getCatelogJsonFromDbWithRedisLock();
}分布式锁演进-阶段四
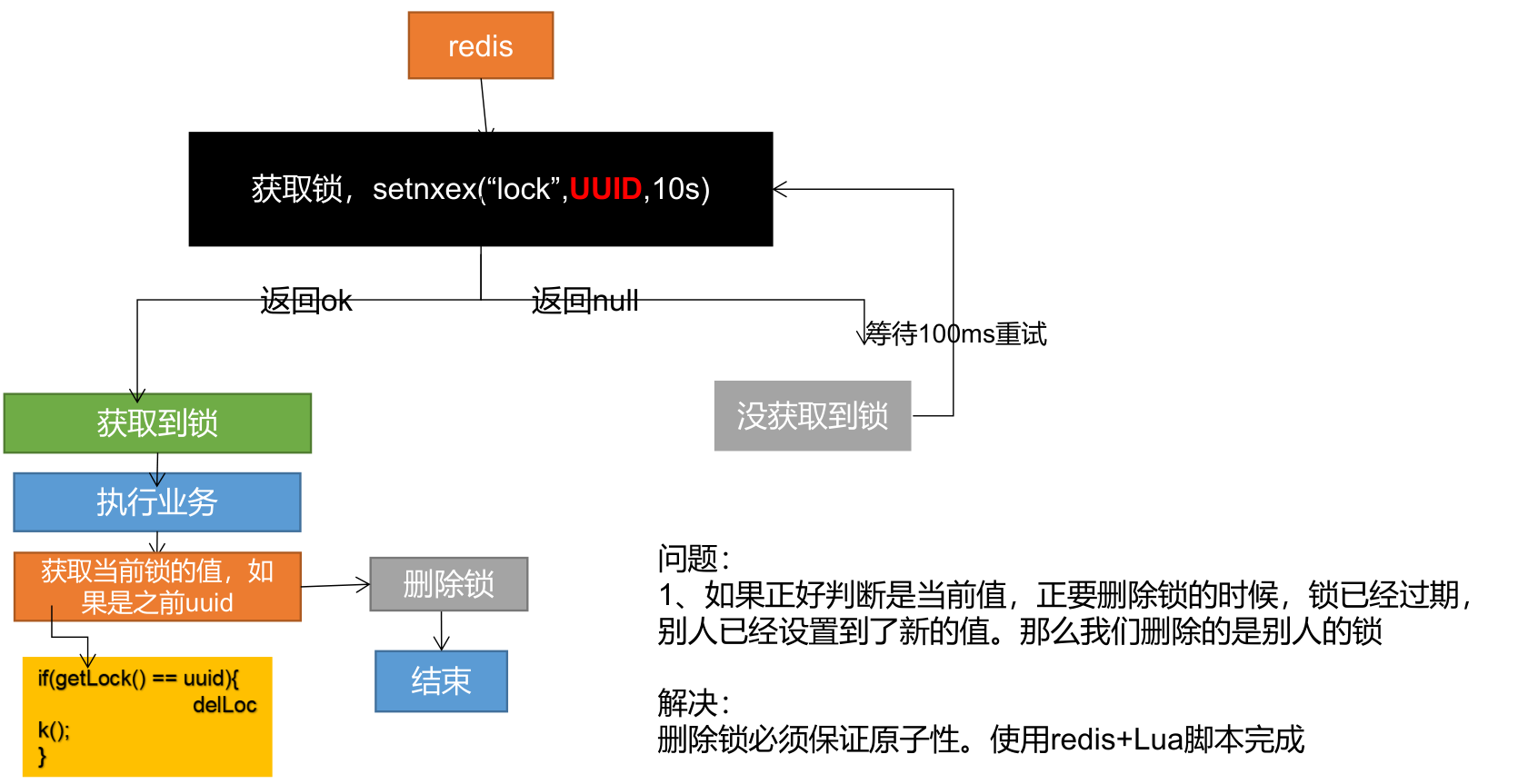
String uuid = UUID.randomUUID().toString();
// 设置值同时设置过期时间
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock",uuid,300,TimeUnit.SECONDS);
if (lock) {
// 加锁成功..执行业务
// 设置过期时间,必须和加锁是同步的,原子的
// redisTemplate.expire("lock",30,TimeUnit.SECONDS);
Map<String,List<Catelog2Vo>> dataFromDb = getDataFromDB();
// String lockValue = redisTemplate.opsForValue().get("lock");
// if (lockValue.equals(uuid)) {
// // 删除我自己的锁
// redisTemplate.delete("lock"); // 删除锁
// }
// 通过使用lua脚本进行原子性删除
String script = "if redis.call('get',KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end";
//删除锁
Long lock1 = redisTemplate.execute(new DefaultRedisScript<Long>(script, Long.class), Arrays.asList("lock"), uuid);
return dataFromDb;
} else {
// 加锁失败,重试 synchronized()
// 休眠100ms重试
return getCatelogJsonFromDbWithRedisLock();
}分布式锁演进-阶段五-最终形态
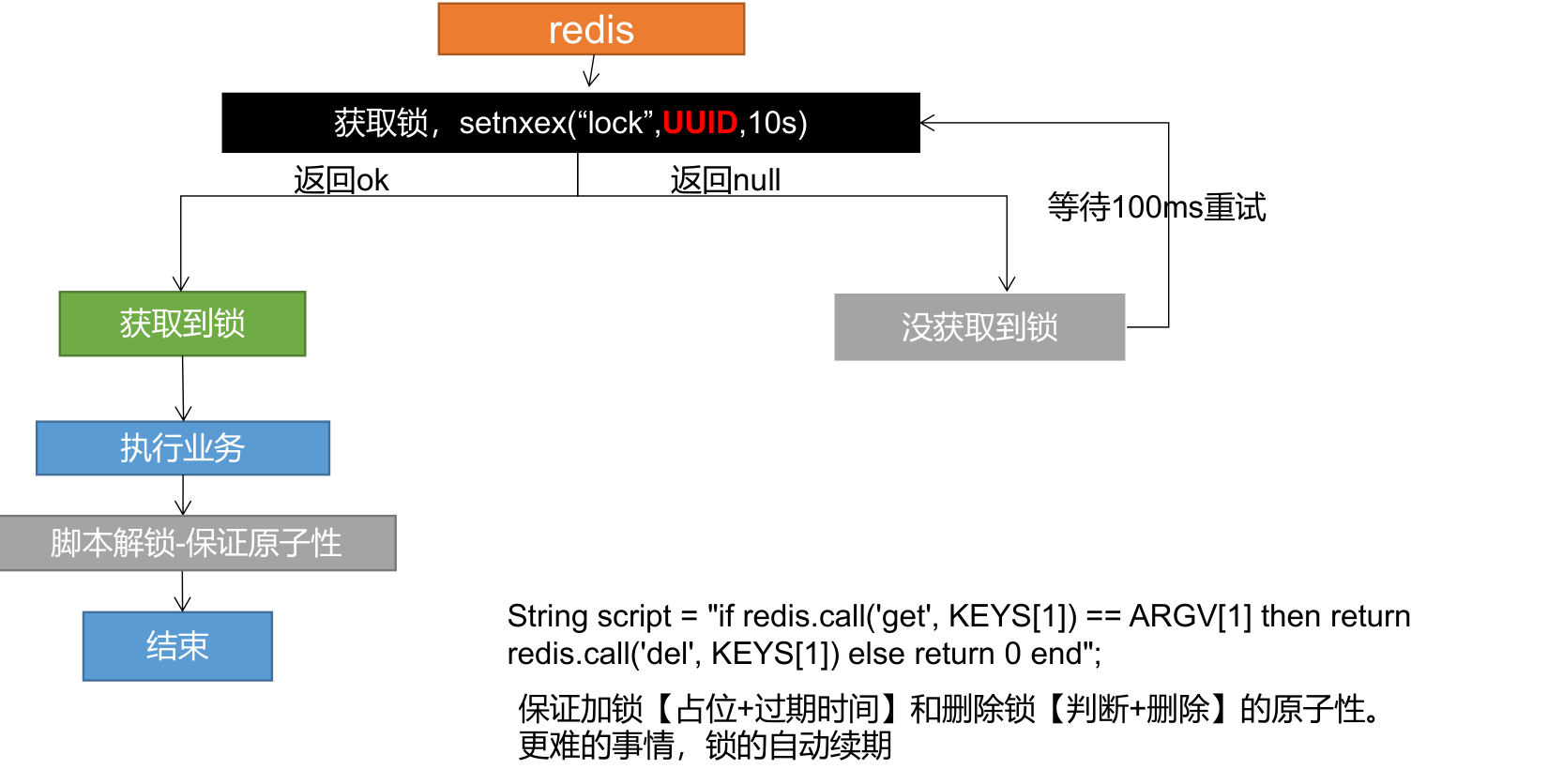
org.klaus.zgg01mall.product.service.impl.CategoryServiceImpl#getCatalogJsonFromDbWithRedisLock
/**
* 使用redis分布式锁来执行业务(luo脚本解锁)
*
* @return
*/
//@Override
public Map<String, List<Catalog2Vo>> getCatalogJsonFromDbWithRedisLock() {
//抢占锁前,每人都获取唯一id设置成lock的value值
String uuid = UUID.randomUUID().toString();
//1、占分布式锁,去redis占坑(原子操作) SET lock(k) 1111(v) NX EX(时间不能太短)
Boolean lock = stringRedisTemplate.opsForValue().setIfAbsent("lock", uuid, 300, TimeUnit.SECONDS);
if (lock) {
System.out.println("获取分布式锁成功.......");
//2、设置过期时间,防止出现死锁情况(若突然断电而无法执行设置过期时间)
//因此设置过期时间,必须和加锁是同步的,原子的
//stringRedisTemplate.expire("lock", 30, TimeUnit.SECONDS);
Map<String, List<Catalog2Vo>> dataFromDb;
try {
//加锁成功.... 执行业务
dataFromDb = getDataFromDb();
} finally {
//无论业务崩溃或异常等情况都执行删除锁,只要保证原子加锁和原子解锁没有问题即可
//因此可以使用luo脚本解锁来实现原子操作
// 指定的lock(key) == 指定的uuid(value) 删除返回1,失败返回0
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
//执行脚本,删除锁
Long lock1 = stringRedisTemplate.execute(
//删除key->成功返回1,失败返回0,返回值为Integer
new DefaultRedisScript<Long>(script, Long.class),
//所有的key集合->得到lock集合
Arrays.asList("lock"), uuid);
}
//获取值对比+对比成功删除=原子操作,否则,即使比对成功也可能删的是别人的锁
// String lockValue = stringRedisTemplate.opsForValue().get("lock");
// //根据占锁的唯一Id值判断是不是同一把锁
// // 极端情况,10s过期时间,执行业务用了9.5s,但获取锁要发送请求到远程的redis来返回数据,所需时间为0.3s,判断需要1s,
// // 即比对成功时锁已过期,删的是redis刚更新的抢占锁
// if (uuid.equals(lockValue)){
// //是同一把锁就把这把锁删掉
// //业务执行完毕后解锁-> 删除锁(key)
// stringRedisTemplate.delete("lock");
// }
return dataFromDb;
} else {
System.out.println("获取分布式锁失败.......等待重试");
//加锁失败....重试。。synchronized ()
//休眠200ms重试
try {
Thread.sleep(200);
} catch (InterruptedException e) {
}
//自旋的方式-> 重新获取锁
return getCatalogJsonFromDbWithRedisLock();
}
}- 给页面返回所有分类的Json数据(加Redis锁)
org.klaus.zgg01mall.product.service.impl.CategoryServiceImpl#getCatalogJson2
/**
* 抽取缓存操作方法(使用了RedisLock)
* 没加缓存注解前的缓存操作业务代码(获取分类的json数据)
* @return
*/
//@Override
public Map<String, List<Catalog2Vo>> getCatalogJson2() {
//给缓存中放json字符串,拿出的json字符串,还要逆转为能用的对象类型【序列化与反序列化】
/**
* 1、空结果缓存,解决缓存穿透
* 2、设置过期时间(加随机值):解决缓存雪崩
* 3、加锁:解决缓存击穿
*/
//1、加入缓存逻辑,缓存中存放的数据是json字符串
//json跨语言,跨平台兼容
String catalogJson = stringRedisTemplate.opsForValue().get("catalogJson");
if (StringUtils.isEmpty(catalogJson)) {
//2、缓存中没有,查询数据库
//保证数据库查询完成以后,将数据放在redis中,这是一个原子操作
System.out.println("缓存不命中。。。。将要查询数据库。。。");
Map<String, List<Catalog2Vo>> catalogJsonFromDb = getCatalogJsonFromDbWithRedisLock();
// //3、查到的数据再放入缓存,将对象转为json放入缓存中
// String s = JSON.toJSONString(catalogJsonFromDb);
// //将数据放入缓存
// stringRedisTemplate.opsForValue().set("catalogJson", s, 1, TimeUnit.DAYS);
//将数据库查到的结果直接返回,即将数据库查到的结果放一份到缓存中并返回
return catalogJsonFromDb;
}
System.out.println("缓存命中。。。。直接返回。。。");
//将数据转为指定类型
Map<String, List<Catalog2Vo>> result = JSON.parseObject(catalogJson, new TypeReference<Map<String, List<Catalog2Vo>>>() {
});
return result;
}3、Redisson 完成分布式锁
1、简介
Redisson 是架设在 Redis 基础上的一个 Java 驻内存数据网格(In-Memory Data Grid)。充分 的利用了 Redis 键值数据库提供的一系列优势,基于 Java 实用工具包中常用接口,为使用者 提供了一系列具有分布式特性的常用工具类。使得原本作为协调单机多线程并发程序的工 具包获得了协调分布式多机多线程并发系统的能力,大大降低了设计和研发大规模分布式 系统的难度。同时结合各富特色的分布式服务,更进一步简化了分布式环境中程序相互之间 的协作。 官方文档:https://github.com/redisson/redisson/wiki/目录
2、引入依赖
<!--以后使用redisson作为所有分布式锁,分布式对象等功能框架 -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.12.0</version>
</dependency>3、配置类
/**
* @author Klaus
* @date 2022/9/7
*/
@Configuration
public class MyRedissonConfig {
/**
* 所有对Redisson的使用都是通过RedissonClient对象
* @return
* @throws IOException
*/
@Bean(destroyMethod="shutdown")
public RedissonClient redisson() throws IOException {
//1、创建配置
//Redis url should start with redis:// or rediss://
Config config = new Config();
//可以用"rediss://"来启用 SSL 连接
config.useSingleServer().setAddress("redis://192.168.10.103:6379");
//2、根据config创建出Redisson实例
RedissonClient redissonClient = Redisson.create(config);
return redissonClient;
}
}4、使用分布式锁
RLock lock = redisson.getLock("anyLock");// 最常见的使用方法
lock.lock();
// 加锁以后 10 秒钟自动解锁// 无需调用 unlock 方法手动解锁
lock.lock(10, TimeUnit.SECONDS);
// 尝试加锁,最多等待 100 秒,上锁以后 10 秒自动解锁
boolean res = lock.tryLock(100,10, TimeUnit.SECONDS);
if (res) {
try {
...
} finally {
lock.unlock();
}
}org.klaus.zgg01mall.product.service.impl.CategoryServiceImpl#getCatalogJsonFromDbWithRedissonLock
/**
* 缓存里面的数据如何和数据库保持一致(使用了RedissonLock)
* 缓存数据一致性
* 1)、双写模式
* 2)、失效模式
*
* @return
*/
//@Override
public Map<String, List<Catalog2Vo>> getCatalogJsonFromDbWithRedissonLock() {
//抢占锁前,每人都获取唯一id设置成lock的value值
//1、占分布式锁,去redis占坑(原子操作)
//注意:传的锁名字一样,锁就一样,锁的粒度,越细越快
//锁的粒度:具体缓存的是某个数据,11号-商品;product-11-lock product-12-lock product-lock
RLock lock = redisson.getLock("catalogJson-lock");
lock.lock();
Map<String, List<Catalog2Vo>> dataFromDb;
try {
dataFromDb = getDataFromDb();
} finally {
lock.unlock();
}
return dataFromDb;
}- 替换Redis锁业务方法为Redisson锁并返回给页面Json数据
Map<String, List<Catalog2Vo>> catalogJsonFromDb = getCatalogJsonFromDbWithRedissonLock();
5、使用其他
补充
1、获取一把锁,只要锁的名字一样,就是同一把锁
- RLock lock = redisson.getLock("my-lock");
2、加锁 阻塞式等待,(默认加的锁都是30s时间)即如果加不到锁,就会在这一直等直到加到锁为止才继续执行下去
- lock.lock();
- 1)、锁的自动续期,如果业务超长,运行期间自动给锁续上新的30s,即不用担心业务时间长而锁自动过期被删掉
- 2)、加锁的业务只要运行完成,就不会给当前锁续期,即使不手动解锁,锁默认在30s以后自动删除
10秒自动解锁,自动解锁时间一定要大于业务的执行时间
- 问题:lock.lock(10, TimeUnit.SECONDS);在锁时间到了以后,不会自动续期
1、如果我们传递了锁的超时时间,就发送给redis执行脚本,进行占锁,默认超时时间就是我们指定的时间
2、如果我们未指定锁的超时时间,就使用30*1000【LockWatchingTimeout看门狗的默认时间】;
只要占锁成功,就会启动一个定时任务【重新给锁设置过期时间,新的过期时间就是看门狗的默认时间】,每隔10s都会自动再次续期,续成30s
internalLockLeaseTime【看门狗时间】/ 3,10s
最佳实战
lock.lock(30, TimeUnit.SECONDS);省掉了整个续期操作,手动解锁
@ResponseBody
@GetMapping("/hello")
public String hello() {
//1、获取一把锁,只要锁的名字一样,就是同一把锁
RLock lock = redisson.getLock("my-lock");
//2、加锁 阻塞式等待,(默认加的锁都是30s时间)即如果加不到锁,就会在这一直等直到加到锁为止才继续执行下去
//lock.lock();
//1)、锁的自动续期,如果业务超长,运行期间自动给锁续上新的30s,即不用担心业务时间长而锁自动过期被删掉
//2)、加锁的业务只要运行完成,就不会给当前锁续期,即使不手动解锁,锁默认在30s以后自动删除
//10秒自动解锁,自动解锁时间一定要大于业务的执行时间
lock.lock(30, TimeUnit.SECONDS);
//todo 问题:lock.lock(10, TimeUnit.SECONDS);在锁时间到了以后,不会自动续期
//1、如果我们传递了锁的超时时间,就发送给redis执行脚本,进行占锁,默认超时时间就是我们指定的时间
//2、如果我们未指定锁的超时时间,就使用30*1000【LockWatchingTimeout看门狗的默认时间】;
// 只要占锁成功,就会启动一个定时任务【重新给锁设置过期时间,新的过期时间就是看门狗的默认时间】,每隔10s都会自动再次续期,续成30s
// internalLockLeaseTime【看门狗时间】/ 3,10s
//最佳实战
//1)、lock.lock(30, TimeUnit.SECONDS);省掉了整个续期操作,手动解锁
try {
System.out.println("加锁成功,执行业务。。。" + Thread.currentThread().getId());
Thread.sleep(30000);
} catch (Exception e) {
} finally {
//3、解锁 假设解锁代码没有运行,redisson会不会出现死锁
System.out.println("释放锁。。。" + Thread.currentThread().getId());
lock.unlock();
}
return "hello";
}1、读+写锁
/**
* 保证一定读到最新数据,修改期间,写锁是一个排它锁(互斥锁、独享锁),读锁是一个共享锁
* 写锁没释放读就必须等待
* 读 + 读: 相当于无锁,并发读,只会在redis中记录好,所有当前的读锁,它们都会同时加锁成功
* 写 + 读: 等待写锁释放
* 写 + 写: 阻塞状态
* 读 + 写: 有读锁,写也需要等待
* 只要有写的存在,都必须等待
* @return
*/
@ResponseBody
@GetMapping("/write")
public String writeValue() {
RReadWriteLock lock = redisson.getReadWriteLock("rw-lock");
String s = "";
RLock rLock = lock.writeLock();
try {
//1、改数据加写锁,读数据加读锁
rLock.lock();
System.out.println("写锁加锁成功..." + Thread.currentThread().getId());
//v
s = UUID.randomUUID().toString();
Thread.sleep(30000);
// k v
redisTemplate.opsForValue().set("writeValue", s);
} catch (Exception e) {
} finally {
rLock.unlock();
System.out.println("写锁释放" + Thread.currentThread().getId());
}
return s;
}
//分布式里的锁跟JUC的API里的锁完全一样
@ResponseBody
@GetMapping("/read")
public String readValue() {
RReadWriteLock lock = redisson.getReadWriteLock("rw-lock");
// ReentrantReadWriteLock reentrantReadWriteLock = new ReentrantReadWriteLock();
String s = "";
RLock rLock = lock.readLock();
//1、读数据加读锁
rLock.lock();
try {
System.out.println("读锁加锁成功....." + Thread.currentThread().getId());
s = redisTemplate.opsForValue().get("writeValue");
Thread.sleep(30000);
} catch (Exception e) {
} finally {
rLock.unlock();
System.out.println("读锁释放" + Thread.currentThread().getId());
}
return s;
}2、信号量
/**
* 车库停车
* 3车位
* 信号量也可以用作分布式限流
* @return
*/
@ResponseBody
@GetMapping("/park")
public String park() throws InterruptedException {
RSemaphore park = redisson.getSemaphore("park");
// park.acquire();//获取一个信号,获取一个值,占一个车位,阻塞式获取,即一定要获取到一个车位
boolean b = park.tryAcquire();//尝试获取车位,有就停,没有就算了
if (b){
//执行业务
}else {
return "error";
}
return "ok=>" + b;
}
/**
* 把车开走,腾空车位
* @return
*/
@ResponseBody
@GetMapping("/go")
public String go(){
RSemaphore park = redisson.getSemaphore("park");
park.release();//释放一个信号(车位)
return "ok";
}3、CountDownLatch闭锁
/**
* 放假 锁门
* 1班没人了,2
* 5个班全部都走完,我们可以锁大门
* @return
*/
@ResponseBody
@GetMapping("/lockDoor")
public String lockDoor() throws InterruptedException {
RCountDownLatch door = redisson.getCountDownLatch("door");
door.trySetCount(5);
door.await();//等待闭锁都完成
return "放假了...";
}
@ResponseBody
@GetMapping("/gogogo/{id}")
public String gogogo(@PathVariable("id") Long id){
RCountDownLatch door = redisson.getCountDownLatch("door");
door.countDown();//计数减一
return id + "班的人都走了...";
}五、Spring Cache
1、简介
Spring 从 3.1 开始定义了 org.springframework.cache.Cache和 org.springframework.cache.CacheManager 接口来统一不同的缓存技术;并支持使用 JCache(JSR-107)注解简化我们开发;
Cache 接口为缓存的组件规范定义,包含缓存的各种操作集合;Cache 接口下 Spring 提供了各种 xxxCache 的实现;如 RedisCache ,EhCacheCache, ConcurrentMapCache 等;
每次调用需要缓存功能的方法时,Spring 会检查检查指定参数的指定的目标方法是否已经被调用过;如果有就直接从缓存中获取方法调用后的结果,如果没有就调用方法并缓存结果后返回给用户。下次调用直接从缓存中获取。
使用 Spring 缓存抽象时我们需要关注以下两点;
1、确定方法需要被缓存以及他们的缓存策略
2、从缓存中读取之前缓存存储的数据
2、基础概念
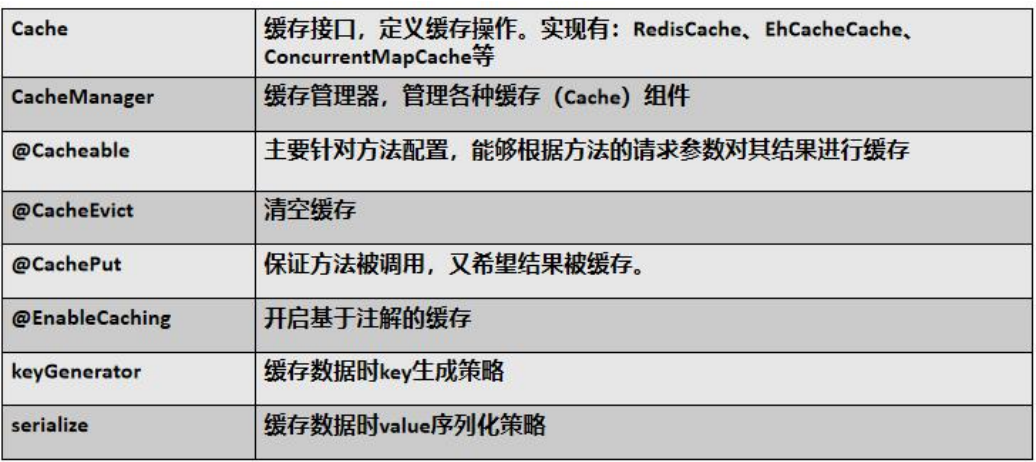
3、注解

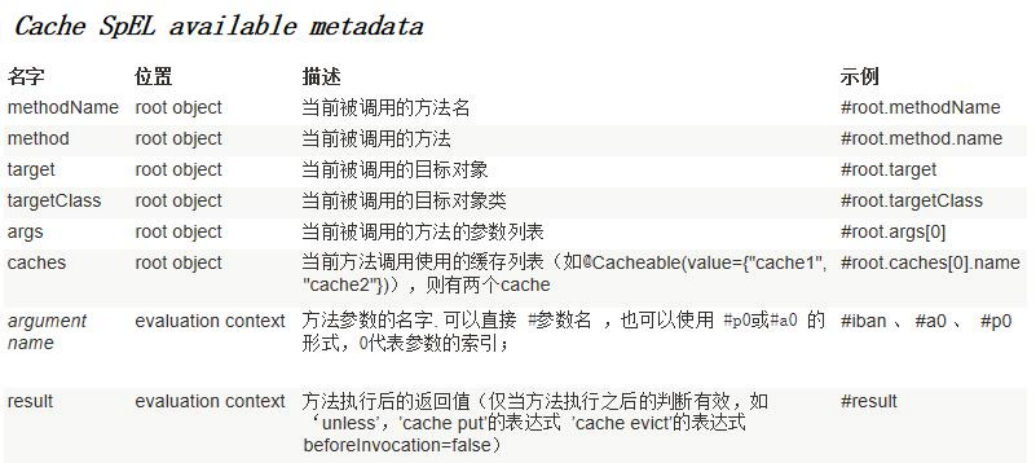
4、表达式语法
5、缓存穿透问题解决(允许 null 值缓存)
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>6、使用
- 添加配置类将配置文件中的所有配置都生效
/**
* @author Klaus
* @date 2022/9/7
*/
@EnableConfigurationProperties(CacheProperties.class)
@EnableCaching
@Configuration
public class MyCacheConfig {
// @Autowired
// CacheProperties cacheProperties;
/**
* 配置文件中的东西没有用上
*
* 1、原来和配置文件绑定的配置类是这样子的
* @ConfigurationProperties( prefix = "spring.cache")
* public class CacheProperties {
* 2、要让它生效
* @EnableConfigurationProperties(CacheProperties.class)
* @return
*/
@Bean
RedisCacheConfiguration redisCacheConfiguration(CacheProperties cacheProperties) {
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig();
//config = config.entryTtl();
//覆盖默认配置
//将数据的key序列化为字符串
config = config.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()));
//将数据的值序列化为json格式 new GenericFastJsonRedisSerializer()兼容各种泛型
config = config.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));
CacheProperties.Redis redisProperties = cacheProperties.getRedis();
//将配置文件中的所有配置都生效
if (redisProperties.getTimeToLive() != null) {
config = config.entryTtl(redisProperties.getTimeToLive());
}
if (redisProperties.getKeyPrefix() != null) {
config = config.prefixKeysWith(redisProperties.getKeyPrefix());
}
if (!redisProperties.isCacheNullValues()) {
config = config.disableCachingNullValues();
}
if (!redisProperties.isUseKeyPrefix()) {
config = config.disableKeyPrefix();
}
return config;
}
}- 配置文件添加相关配置
spring.cache.type=redis
#设置缓存的数据存活时间,即ttl时间(毫秒为单位)
spring.cache.redis.time-to-live=3600000
#todo 设置前缀名配置后,缓存的分区不见了
#如果指定了前缀就用我们指定的前缀CACHE_getLevel1Categorys,没有就默认使用缓存的名字作为前缀
#spring.cache.redis.key-prefix=CACHE_
#不使用前缀就使用自己指定的key值作为缓存名字key = "#root.method.name",getLevel1Categorys
spring.cache.redis.use-key-prefix=true
#是否缓存空值,防止缓存穿透
spring.cache.redis.cache-null-values=true- 获取所有分类Json数据接口
org.klaus.zgg01mall.product.web.IndexController#getCatalogJson
//index/catalog.json
@ResponseBody
@GetMapping("/index/catalog.json")
public Map<String, List<Catalog2Vo>> getCatalogJson() {
Map<String, List<Catalog2Vo>> catalogJson = categoryService.getCatalogJson();
return catalogJson;
}- 获取所有分类Json数据方法实现
org.klaus.zgg01mall.product.service.impl.CategoryServiceImpl#getCatalogJson
/**
* 加入缓存注解,再次简化缓存操作业务代码
* @return
*/
@Cacheable(value = "category", key = "#root.methodName")
@Override
public Map<String, List<Catalog2Vo>> getCatalogJson() {
System.out.println("查询了数据库。。。");
/**
* 缓存为空,进行查询业务
* 1、将数据库的多次查询变为一次,即方法抽取
*/
//查询所有
List<CategoryEntity> selectList = baseMapper.selectList(null);
//1、查出所有1级分类 一级分类集合,一级分类父分类id为0
List<CategoryEntity> level1Categorys = getParent_cid(selectList, 0L);
//2、封装数据
Map<String, List<Catalog2Vo>> map = level1Categorys.stream().collect(Collectors.toMap(
//"pCId":"c2{}"
k -> k.getCatId().toString(),
v -> {
//2.1、每一个的一级分类,查到这个一级分类的[二级分类]
//得到二级分类实体集合 抽取查询方法-> baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("parent_cid", v.getCatId()));
//todo 父分类集合, 当前分类id(v为当前遍历的一级分类)
List<CategoryEntity> catalog2Entities = getParent_cid(selectList, v.getCatId());
//2.2、封装上面的结果
List<Catalog2Vo> catalog2Vos = null;
//父分类不为空,即二级分类实体集合不为空
if (catalog2Entities != null) {
//遍历拿到每个二级分类集合
catalog2Vos = catalog2Entities.stream().map(l2 -> {
//封装二级分类vo数据
Catalog2Vo catalog2Vo = new Catalog2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName());
//2.2.1、找当前二级分类的三级分类封装成vo baseMapper.selectList(new QueryWrapper<CategoryEntity>(). eq("parent_cid", l2.getCatId()));
// (三级分类父分类)父分类集合, 当前分类id(l2为当前遍历的二级分类)
List<CategoryEntity> catalog3Entities = getParent_cid(selectList, l2.getCatId());
List<Catalog2Vo.Catalog3Vo> catalog3Vos = null;
if (catalog3Entities != null) {
catalog3Vos = catalog3Entities.stream().map(l3 -> {
//2.2.2、封装成指定格式
Catalog2Vo.Catalog3Vo catalog3Vo = new Catalog2Vo.Catalog3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());
return catalog3Vo;
}).collect(Collectors.toList());
catalog2Vo.setCatalog3List(catalog3Vos);
}
return catalog2Vo;
}).collect(Collectors.toList());
}
return catalog2Vos;
}));
return map;
}- 首页获取一级分类响应视图渲染接口
org.klaus.zgg01mall.product.web.IndexController#indexPage
@GetMapping({"/", "index.html"})
public String indexPage(Model model) {
// System.out.println("" + Thread.currentThread().getId());
//todo 1、查出所有的1级分类
List<CategoryEntity> categoryEntityList = categoryService.getLevel1Categorys();
//视图解析器进行拼接
//classpath:/templates/ + 返回值 + .html
model.addAttribute("categorys", categoryEntityList);
return "index";
}- 首页获取一级分类方法实现
org.klaus.zgg01mall.product.service.impl.CategoryServiceImpl#getLevel1Categorys
@Cacheable(value = {"category"}, key = "#root.method.name", sync = true)
@Override
public List<CategoryEntity> getLevel1Categorys() {
System.out.println("getLevel1Categorys.....");
long l = System.currentTimeMillis();
//查出一级分类,即父分类为0
List<CategoryEntity> categoryEntities = baseMapper.selectList(new QueryWrapper<CategoryEntity>().
eq("parent_cid", 0));
//System.out.println("消耗时间:" + (System.currentTimeMillis() - l));
return categoryEntities;
}- 级联更新所有关联的数据方法实现
org.klaus.zgg01mall.product.service.impl.CategoryServiceImpl#updateCascade
@CacheEvict:失效模式 1、同时进行多种缓存操作@Caching 2、指定删除某个分区下的所有数据@CacheEvict(value = "category", allEntries = true) 3、存储同一类型的数据,都可以指定成同一个分区,分区名默认就是缓存的前缀
// @Caching(evict = {
// @CacheEvict(value = "category", key = "'getLevel1Categorys'"),
// @CacheEvict(value = "category", key = "'getCatalogJson'")
// })
//category::key 失效模式
@CacheEvict(value = "category", allEntries = true)
// @CachePut//双写模式
@Transactional
@Override
public void updateCascade(CategoryEntity category) {
//先更新自己
this.updateById(category);
categoryBrandRelationService.updateCategory(category.getCatId(), category.getName());
//同时修改缓存中的数据
//redis.del("catalogJSON");等待下次主动查询进行更新
}7、总结
@Cacheable
1、每一个需要缓存的数据我们都来指定要放到哪个名字的缓存【缓存的分区(按照业务类型分)】
2、 @Cacheable({"category"})
代表当前方法的结果需要缓存,
如果缓存中有,方法就不用调用;若缓存中没有,会调用方法,最后将方法的结果放入缓存
3、默认行为
1)、如果缓存中有,方法就不用调用
2)、key默认自动生成:
缓存的名字 ::SimpleKey [](自主生成的key值)3)、缓存的value值,默认使用jdk序列化机制,将序列化后的数据存到redis
4)、默认ttl时间:-1
自定义:缓存分区:value = {"category"} :: 缓存名字:key = "'level1Categorys'"/"#root.method.name"
- 1)、指定生成的缓存使用的key: key属性指定,接受一个SpEl
- SpEl详情:https://docs.spring.io/spring-framework/docs/current/reference/html/integration.html#cache-spel-cont
- 2)、指定缓存的数据的存活时间: 配置文件中修改ttl
- 3)、将数据保存为json格式
4、Spring-Cache的不足:
- 1)、读模式:
- 缓存穿透:查询一个null数据,解决:缓存空数据:cache-null-values=true
- 缓存击穿:大量并发进来同时查询一个正好过期的数据,解决L加锁:?通过调试源码是默认为无加锁的;sync = true(加锁,解决击穿)
- 缓存雪崩:大量的key同时过期,解决:加随机时间,加上过期时间:spring.cache.redis.time-to-live=3600000
- 2)、写模式: (缓存与数据库一致)
- i)、读写加锁(适用于读多写少的系统,但读多了一直加锁等待也不合适)
- ii)、引入Canal,感知到MySql的更新去更新数据库
- iii)、读多写多,直接去数据库查询就行
- 1)、读模式:
总结:
- 常规数据(读多写少,即时性,一致性要求不高的数据):完全可以使用Spring-Cache;写模式(只要缓存的数据有过期时间就足够了)
特殊数据:特殊设计
原理:
- CacheManager(RedisCacheManager)->Cache(RedisCache)->Cache负责缓存的读写
整合SpringCache简化缓存开发
- 1)、引入依赖
- spring-boot-starter-cache、spring-boot-starter-data-redis
- 2)、写配置
- i)、自动配置了哪些
- CacheAutoConfiguration会导入RedisCacheConfiguration
- 自动配好了缓存管理器RedisCacheManager
- ii)、配置使用redis作为缓存
- spring.cache.type=redis
- i)、自动配置了哪些
- 3)、测试使用缓存
- @Cacheable: Triggers cache population. :触发将数据保存到缓存的操作
- @CacheEvict: Triggers cache eviction. : 触发将数据从缓存中删除的操作
- @CachePut: Updates the cache without interfering with the method execution.:不影响方法执行更新缓存
- @Caching: Regroups multiple cache operations to be applied on a method.:组合以上多个操作
- @CacheConfig: Shares some common cache-related settings at class-level.:在类级别共享缓存的相同配置
- i)、开启缓存功能 @EnableCaching
- ii)、只需要使用注解就能完成缓存操作
- 4)、原理:
- CacheAutoConfiguration —> RedisCacheConfiguration ->自动配置了RedisCacheManager -> 初始化所有的缓存->每个缓存决定使用什么配置->如果redisCacheConfiguration有就用已有的,没有就用默认->想改缓存的配置,只需要给容器中放一个RedisCacheConfiguration即可->就会应用到当前RedisCacheManager管理的所有缓存分区中
To Be Continued.