
基本介绍
主从复制是指将主数据库的 DDL 和 DML 操作通过二进制日志传到从库服务器中,然后在从库上对这些日志重新执行(也叫重做),从而使得从库和主库的数据保持同步
MySQL 支持一台主库同时向多台从库进行复制,从库同时也可以作为其他从服务器的主库,实现链状复制
MySQL 复制的优点主要包含以下三个方面:
主库出现问题,可以快速切换到从库提供服务
可以在从库上执行查询操作,从主库中更新,实现读写分离
可以在从库中执行备份,以避免备份期间影响主库的服务(备份时会加全局读锁)
主从复制
主从结构
MySQL 的主从之间维持了一个长连接。主库内部有一个线程,专门用于服务从库的长连接,连接过程:
- 从库执行 change master 命令,设置主库的 IP、端口、用户名、密码以及要从哪个位置开始请求 binlog,这个位置包含文件名和日志偏移量
- 从库执行 start slave 命令,这时从库会启动两个线程,就是图中的 io_thread 和 sql_thread,其中 io_thread 负责与主库建立连接
- 主库校验完用户名、密码后,开始按照从传过来的位置,从本地读取 binlog 发给从库,开始主从复制
主从复制原理图:
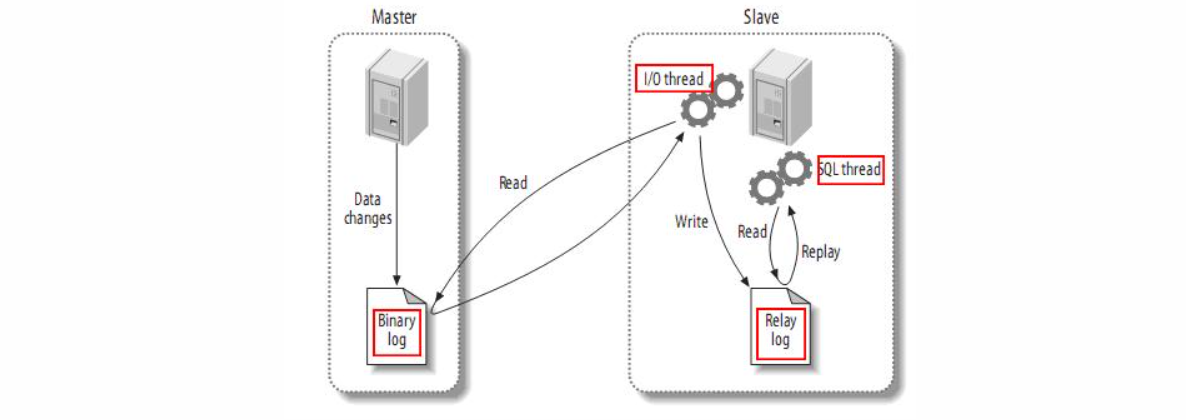
主从复制主要依赖的是 binlog,MySQL 默认是异步复制,需要三个线程:
- binlog thread:在主库事务提交时,把数据变更记录在日志文件 binlog 中,并通知 slave 有数据更新
- I/O thread:负责从主服务器上拉取二进制日志,并将 binlog 日志内容依次写到 relay log 中转日志的最末端,并将新的 binlog 文件名和 offset 记录到 master-info 文件中,以便下一次读取日志时从指定 binlog 日志文件及位置开始读取新的 binlog 日志内容
- SQL thread:监测本地 relay log 中新增了日志内容,读取中继日志并重做其中的 SQL 语句,从库在 relay-log.info 中记录当前应用中继日志的文件名和位点以便下一次执行
同步与异步:
- 异步复制有数据丢失风险,例如数据还未同步到从库,主库就给客户端响应,然后主库挂了,此时从库晋升为主库的话数据是缺失的
- 同步复制,主库需要将 binlog 复制到所有从库,等所有从库响应了之后主库才进行其他逻辑,这样的话性能很差,一般不会选择
- MySQL 5.7 之后出现了半同步复制,有参数可以选择成功同步几个从库就返回响应
主主结构
主主结构就是两个数据库之间总是互为主从关系,这样在切换的时候就不用再修改主从关系
循环复制:在库 A 上更新了一条语句,然后把生成的 binlog 发给库 B,库 B 执行完这条更新语句后也会生成 binlog,会再发给 A
解决方法:
- 两个库的 server id 必须不同,如果相同则它们之间不能设定为主主关系
- 一个库接到 binlog 并在重放的过程中,生成与原 binlog 的 server id 相同的新的 binlog
- 每个库在收到从主库发过来的日志后,先判断 server id,如果跟自己的相同,表示这个日志是自己生成的,就直接丢弃这个日志
主从延迟
延迟原因
正常情况主库执行更新生成的所有 binlog,都可以传到从库并被正确地执行,从库就能达到跟主库一致的状态,这就是最终一致性
主从延迟是主从之间是存在一定时间的数据不一致,就是同一个事务在从库执行完成的时间和主库执行完成的时间的差值,即 T2-T1
- 主库 A 执行完成一个事务,写入 binlog,该时刻记为 T1
- 日志传给从库 B,从库 B 执行完这个事务,该时刻记为 T2
通过在从库执行 show slave status 命令,返回结果会显示 seconds_behind_master 表示当前从库延迟了多少秒
- 每一个事务的 binlog 都有一个时间字段,用于记录主库上写入的时间
- 从库取出当前正在执行的事务的时间字段,跟系统的时间进行相减,得到的就是 seconds_behind_master
主从延迟的原因:
- 从库的机器性能比主库的差,导致从库的复制能力弱
- 从库的查询压力大,建立一主多从的结构
- 大事务的执行,主库必须要等到事务完成之后才会写入 binlog,导致从节点出现应用 binlog 延迟
- 主库的 DDL,从库与主库的 DDL 同步是串行进行,DDL 在主库执行时间很长,那么从库也会消耗同样的时间
- 锁冲突问题也可能导致从节点的 SQL 线程执行慢
主从同步问题永远都是一致性和性能的权衡,需要根据实际的应用场景,可以采取下面的办法:
优化 SQL,避免慢 SQL,减少批量操作
降低多线程大事务并发的概率,优化业务逻辑
业务中大多数情况查询操作要比更新操作更多,搭建一主多从结构,让这些从库来分担读的压力
尽量采用短的链路,主库和从库服务器的距离尽量要短,提升端口带宽,减少 binlog 传输的网络延时
实时性要求高的业务读强制走主库,从库只做备份
并行复制
MySQL5.6
高并发情况下,主库的会产生大量的 binlog,在从库中有两个线程 IO Thread 和 SQL Thread 单线程执行,会导致主库延迟变大。为了改善复制延迟问题,MySQL 5.6 版本增加了并行复制功能,以采用多线程机制来促进执行
coordinator 就是原来的 SQL Thread,并行复制中它不再直接更新数据,只负责读取中转日志和分发事务:
- 线程分配完成并不是立即执行,为了防止造成更新覆盖,更新同一 DB 的两个事务必须被分发到同一个工作线程
- 同一个事务不能被拆开,必须放到同一个工作线程
MySQL 5.6 版本的策略:每个线程对应一个 hash 表,用于保存当前这个线程的执行队列里的事务所涉及的表,hash 表的 key 是数据库名,value 是一个数字,表示队列中有多少个事务修改这个库,适用于主库上有多个 DB 的情况
每个事务在分发的时候,跟线程的冲突(事务操作的是同一个库)关系包括以下三种情况:
- 如果跟所有线程都不冲突,coordinator 线程就会把这个事务分配给最空闲的线程
- 如果只跟一个线程冲突,coordinator 线程就会把这个事务分配给这个存在冲突关系的线程
- 如果跟多于一个线程冲突,coordinator 线程就进入等待状态,直到和这个事务存在冲突关系的线程只剩下 1 个
优缺点:
- 构造 hash 值的时候很快,只需要库名,而且一个实例上 DB 数也不会很多,不会出现需要构造很多项的情况
- 不要求 binlog 的格式,statement 格式的 binlog 也可以很容易拿到库名(日志章节详解了 binlog)
- 主库上的表都放在同一个 DB 里面,这个策略就没有效果了;或者不同 DB 的热点不同,比如一个是业务逻辑库,一个是系统配置库,那也起不到并行的效果,需要把相同热度的表均匀分到这些不同的 DB 中,才可以使用这个策略
MySQL5.7
MySQL 5.7 由参数 slave-parallel-type 来控制并行复制策略:
- 配置为 DATABASE,表示使用 MySQL 5.6 版本的按库(DB)并行策略
- 配置为 LOGICAL_CLOCK,表示的按提交状态并行执行
按提交状态并行复制策略的思想是:
- 所有处于 commit 状态的事务可以并行执行;同时处于 prepare 状态的事务,在从库执行时是可以并行的
- 处于 prepare 状态的事务,与处于 commit 状态的事务之间,在从库执行时也是可以并行的
MySQL 5.7.22 版本里,MySQL 增加了一个新的并行复制策略,基于 WRITESET 的并行复制,新增了一个参数 binlog-transaction-dependency-tracking,用来控制是否启用这个新策略:
COMMIT_ORDER:表示根据同时进入 prepare 和 commit 来判断是否可以并行的策略
WRITESET:表示的是对于每个事务涉及更新的每一行,计算出这一行的 hash 值,组成该事务的 writeset 集合,如果两个事务没有操作相同的行,也就是说它们的 writeset 没有交集,就可以并行(按行并行)
为了唯一标识,这个 hash 表的值是通过
库名 + 表名 + 索引名 + 值(表示的是某一行)计算出来的WRITESET_SESSION:是在 WRITESET 的基础上多了一个约束,即在主库上同一个线程先后执行的两个事务,在备库执行的时候,要保证相同的先后顺序
MySQL 5.7.22 按行并发的优势:
- writeset 是在主库生成后直接写入到 binlog 里面的,这样在备库执行的时候,不需要解析 binlog 内容,节省了计算量
- 不需要把整个事务的 binlog 都扫一遍才能决定分发到哪个线程,更省内存
- 从库的分发策略不依赖于 binlog 内容,所以 binlog 是 statement 格式也可以,更节约内存(因为 row 才记录更改的行)
MySQL 5.7.22 的并行复制策略在通用性上是有保证的,但是对于表上没主键、唯一和外键约束的场景,WRITESET 策略也是没法并行的,也会暂时退化为单线程模型
参考文章:https://time.geekbang.org/column/article/77083
读写分离
读写延迟
读写分离:可以降低主库的访问压力,提高系统的并发能力
- 主库不建查询的索引,从库建查询的索引。因为索引需要维护的,比如插入一条数据,不仅要在聚簇索引上面插入,对应的二级索引也得插入
- 将读操作分到从库了之后,可以在主库把查询要用的索引删了,减少写操作对主库的影响
读写分离产生了读写延迟,造成数据的不一致性。假如客户端执行完一个更新事务后马上发起查询,如果查询选择的是从库的话,可能读到的还是以前的数据,叫过期读
解决方案:
- 强制将写之后立刻读的操作转移到主库,比如刚注册的用户,直接登录从库查询可能查询不到,先走主库登录
- 二次查询,如果从库查不到数据,则再去主库查一遍,由 API 封装,比较简单,但导致主库压力大
- 更新主库后,读从库之前先 sleep 一下,类似于执行一条
select sleep(1)命令,大多数情况下主备延迟在 1 秒之内
确保机制
无延迟
确保主备无延迟的方法:
- 每次从库执行查询请求前,先判断 seconds_behind_master 是否已经等于 0,如果不等于那就等到参数变为 0 执行查询请求
- 对比位点,Master_Log_File 和 Read_Master_Log_Pos 表示的是读到的主库的最新位点,Relay_Master_Log_File 和 Exec_Master_Log_Pos 表示的是备库执行的最新位点,这两组值完全相同就说明接收到的日志已经同步完成
- 对比 GTID 集合,Retrieved_Gtid_Set 是备库收到的所有日志的 GTID 集合,Executed_Gtid_Set 是备库所有已经执行完成的 GTID 集合,如果这两个集合相同也表示备库接收到的日志都已经同步完成
半同步
半同步复制就是 semi-sync replication,适用于一主一备的场景,工作流程:
- 事务提交的时候,主库把 binlog 发给从库
- 从库收到 binlog 以后,发回给主库一个 ack,表示收到了
- 主库收到这个 ack 以后,才能给客户端返回事务完成的确认
在一主多从场景中,主库只要等到一个从库的 ack,就开始给客户端返回确认,这时在从库上执行查询请求,有两种情况:
- 如果查询是落在这个响应了 ack 的从库上,是能够确保读到最新数据
- 如果查询落到其他从库上,它们可能还没有收到最新的日志,就会产生过期读的问题
在业务更新的高峰期,主库的位点或者 GTID 集合更新很快,导致从库来不及处理,那么两个位点等值判断就会一直不成立,很可能出现从库上迟迟无法响应查询请求的情况
等位点
在从库执行判断位点的命令,参数 file 和 pos 指的是主库上的文件名和位置,timeout 可选,设置为正整数 N 表示最多等待 N 秒
SELECT master_pos_wait(file, pos[, timeout]);命令正常返回的结果是一个正整数 M,表示从命令开始执行,到应用完 file 和 pos 表示的 binlog 位置,执行了多少事务
- 如果执行期间,备库同步线程发生异常,则返回 NULL
- 如果等待超过 N 秒,就返回 -1
- 如果刚开始执行的时候,就发现已经执行过这个位置了,则返回 0
工作流程:先执行 trx1,再执行一个查询请求的逻辑,要保证能够查到正确的数据
- trx1 事务更新完成后,马上执行
show master status得到当前主库执行到的 File 和 Position - 选定一个从库执行判断位点语句,如果返回值是 >=0 的正整数,说明从库已经同步完事务,可以在这个从库执行查询语句
- 如果出现其他情况,需要到主库执行查询语句
注意:如果所有的从库都延迟超过 timeout 秒,查询压力就都跑到主库上,所以需要进行权衡
等GTID
数据库开启了 GTID 模式,MySQL 提供了判断 GTID 的命令
SELECT wait_for_executed_gtid_set(gtid_set [, timeout])- 等待直到这个库执行的事务中包含传入的 gtid_set,返回 0
- 超时返回 1
工作流程:先执行 trx1,再执行一个查询请求的逻辑,要保证能够查到正确的数据
- trx1 事务更新完成后,从返回包直接获取这个事务的 GTID,记为 gtid
- 选定一个从库执行查询语句,如果返回值是 0,则在这个从库执行查询语句,否则到主库执行查询语句
对比等待位点方法,减少了一次 show master status 的方法,将参数 session_track_gtids 设置为 OWN_GTID,然后通过 API 接口 mysql_session_track_get_first 从返回包解析出 GTID 的值即可
总结:所有的等待无延迟的方法,都需要根据具体的业务场景去判断实施
参考文章:https://time.geekbang.org/column/article/77636
负载均衡
负载均衡是应用中使用非常普遍的一种优化方法,机制就是利用某种均衡算法,将固定的负载量分布到不同的服务器上,以此来降低单台服务器的负载,达到优化的效果
分流查询:通过 MySQL 的主从复制,实现读写分离,使增删改操作走主节点,查询操作走从节点,从而可以降低单台服务器的读写压力
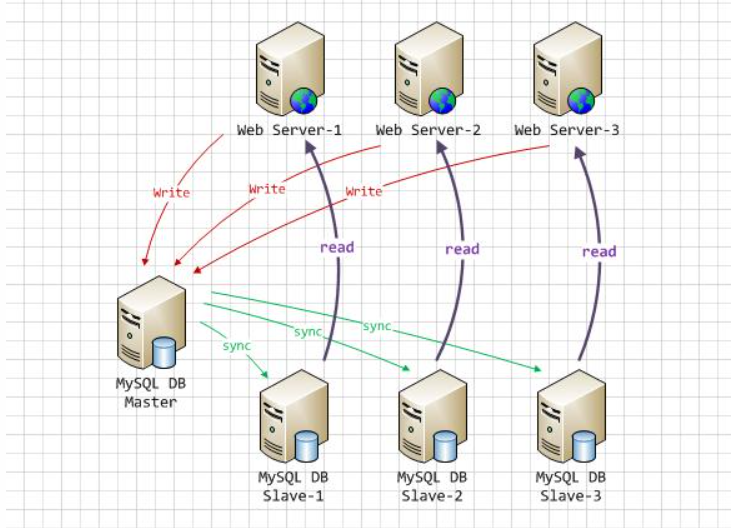
分布式数据库架构:适合大数据量、负载高的情况,具有良好的拓展性和高可用性。通过在多台服务器之间分布数据,可以实现在多台服务器之间的负载均衡,提高访问效率
主从搭建
master
在master 的配置文件(/etc/mysql/my.cnf)中,配置如下内容:
sh#mysql 服务ID,保证整个集群环境中唯一 server-id=1 #mysql binlog 日志的存储路径和文件名 log-bin=/var/lib/mysql/mysqlbin #错误日志,默认已经开启 #log-err #mysql的安装目录 #basedir #mysql的临时目录 #tmpdir #mysql的数据存放目录 #datadir #是否只读,1 代表只读, 0 代表读写 read-only=0 #忽略的数据, 指不需要同步的数据库 binlog-ignore-db=mysql #指定同步的数据库 #binlog-do-db=db01执行完毕之后,需要重启 MySQL
创建同步数据的账户,并且进行授权操作:
sqlGRANT REPLICATION SLAVE ON *.* TO 'klaus'@'192.168.0.137' IDENTIFIED BY '123456'; FLUSH PRIVILEGES;查看 master 状态:
sqlSHOW MASTER STATUS;
- File:从哪个日志文件开始推送日志文件
- Position:从哪个位置开始推送日志
- Binlog_Ignore_DB:指定不需要同步的数据库
slave
在 slave 端配置文件中,配置如下内容:
sh#mysql服务端ID,唯一 server-id=2 #指定binlog日志 log-bin=/var/lib/mysql/mysqlbin执行完毕之后,需要重启 MySQL
指定当前从库对应的主库的IP地址、用户名、密码,从哪个日志文件开始的那个位置开始同步推送日志
sqlCHANGE MASTER TO MASTER_HOST= '192.168.0.138', MASTER_USER='klaus', MASTER_PASSWORD='klaus', MASTER_LOG_FILE='mysqlbin.000001', MASTER_LOG_POS=413;开启同步操作:
sqlSTART SLAVE; SHOW SLAVE STATUS;停止同步操作:
sqlSTOP SLAVE;
验证
在主库中创建数据库,创建表并插入数据:
sqlCREATE DATABASE db01; USE db01; CREATE TABLE user( id INT(11) NOT NULL AUTO_INCREMENT, name VARCHAR(50) NOT NULL, sex VARCHAR(1), PRIMARY KEY (id) )ENGINE=INNODB DEFAULT CHARSET=utf8; INSERT INTO user(id,NAME,sex) VALUES(NULL,'Tom','1'); INSERT INTO user(id,NAME,sex) VALUES(NULL,'Trigger','0'); INSERT INTO user(id,NAME,sex) VALUES(NULL,'Dawn','1');在从库中查询数据,进行验证:
在从库中,可以查看到刚才创建的数据库:

在该数据库中,查询表中的数据:

主从切换
正常切换
正常切换步骤:
在开始切换之前先对主库进行锁表
flush tables with read lock,然后等待所有语句执行完成,切换完成后可以释放锁检查 slave 同步状态,在 slave 执行
show processlist停止 slave io 线程,执行命令
STOP SLAVE IO_THREAD提升 slave 为 master
sqlStop slave; Reset master; Reset slave all; set global read_only=off; -- 设置为可更新状态将原来 master 变为 slave(参考搭建流程中的 slave 方法)
可靠性优先策略:
- 判断备库 B 现在的 seconds_behind_master,如果小于某个值(比如 5 秒)继续下一步,否则持续重试这一步
- 把主库 A 改成只读状态,即把 readonly 设置为 true
- 判断备库 B 的 seconds_behind_master 的值,直到这个值变成 0 为止(该步骤比较耗时,所以步骤 1 中要尽量等待该值变小)
- 把备库 B 改成可读写状态,也就是把 readonly 设置为 false
- 把业务请求切到备库 B
可用性优先策略:先做最后两步,会造成主备数据不一致的问题
参考文章:https://time.geekbang.org/column/article/76795
健康检测
主库发生故障后从库会上位,其他从库指向新的主库,所以需要一个健康检测的机制来判断主库是否宕机
select 1 判断,但是高并发下检测不出线程的锁等待的阻塞问题
查表判断,在系统库(mysql 库)里创建一个表,比如命名为 health_check,里面只放一行数据,然后定期执行。但是当 binlog 所在磁盘的空间占用率达到 100%,所有的更新和事务提交语句都被阻塞,查询语句可以继续运行
更新判断,在健康检测表中放一个 timestamp 字段,用来表示最后一次执行检测的时间
sqlUPDATE mysql.health_check SET t_modified=now();节点可用性的检测都应该包含主库和备库,为了让主备之间的更新不产生冲突,可以在 mysql.health_check 表上存入多行数据,并用主备的 server_id 做主键,保证主、备库各自的检测命令不会发生冲突
基于位点
主库上位后,从库 B 执行 CHANGE MASTER TO 命令,指定 MASTER_LOG_FILE、MASTER_LOG_POS 表示从新主库 A 的哪个文件的哪个位点开始同步,这个位置就是同步位点,对应主库的文件名和日志偏移量
寻找位点需要找一个稍微往前的,然后再通过判断跳过那些在从库 B 上已经执行过的事务,获取位点方法:
- 等待新主库 A 把中转日志(relay log)全部同步完成
- 在 A 上执行 show master status 命令,得到当前 A 上最新的 File 和 Position
- 取原主库故障的时刻 T,用 mysqlbinlog 工具解析新主库 A 的 File,得到 T 时刻的位点
通常情况下该值并不准确,在切换的过程中会发生错误,所以要先主动跳过这些错误:
切换过程中,可能会重复执行一个事务,所以需要主动跳过所有重复的事务
sqlSET GLOBAL sql_slave_skip_counter=1; START SLAVE;设置 slave_skip_errors 参数,直接设置跳过指定的错误,保证主从切换的正常进行
- 1062 错误是插入数据时唯一键冲突
- 1032 错误是删除数据时找不到行
该方法针对的是主备切换时,由于找不到精确的同步位点,只能采用这种方法来创建从库和新主库的主备关系。等到主备间的同步关系建立完成并稳定执行一段时间后,还需要把这个参数设置为空,以免真的出现了主从数据不一致也跳过了
基于GTID
GTID
GTID 的全称是 Global Transaction Identifier,全局事务 ID,是一个事务在提交时生成的,是这个事务的唯一标识,组成:
GTID=source_id:transaction_id- source_id:是一个实例第一次启动时自动生成的,是一个全局唯一的值
- transaction_id:初始值是 1,每次提交事务的时候分配给这个事务,并加 1,是连续的(区分事务 ID,事务 ID 是在执行时生成)
启动 MySQL 实例时,加上参数 gtid_mode=on 和 enforce_gtid_consistency=on 就可以启动 GTID 模式,每个事务都会和一个 GTID 一一对应,每个 MySQL 实例都维护了一个 GTID 集合,用来存储当前实例执行过的所有事务
GTID 有两种生成方式,使用哪种方式取决于 session 变量 gtid_next:
gtid_next=automatic:使用默认值,把 source_id:transaction_id (递增)分配给这个事务,然后加入本实例的 GTID 集合sql@@SESSION.GTID_NEXT = 'source_id:transaction_id';gtid_next=GTID:指定的 GTID 的值,如果该值已经存在于实例的 GTID 集合中,接下来执行的事务会直接被系统忽略;反之就将该值分配给接下来要执行的事务,系统不需要给这个事务生成新的 GTID,也不用加 1注意:一个 GTID 只能给一个事务使用,所以执行下一个事务,要把 gtid_next 设置成另外一个 GTID 或者 automatic
业务场景:
主库 X 和从库 Y 执行一条相同的指令后进行事务同步
sqlINSERT INTO t VALUES(1,1);当 Y 同步 X 时,会出现主键冲突,导致实例 X 的同步线程停止,解决方法:
sqlSET gtid_next='(这里是主库 X 的 GTID 值)'; BEGIN; COMMIT; SET gtid_next=automatic; START SLAVE;前三条语句通过提交一个空事务,把 X 的 GTID 加到实例 Y 的 GTID 集合中,实例 Y 就会直接跳过这个事务
切换
在 GTID 模式下,CHANGE MASTER TO 不需要指定日志名和日志偏移量,指定 master_auto_position=1 代表使用 GTID 模式
新主库实例 A 的 GTID 集合记为 set_a,从库实例 B 的 GTID 集合记为 set_b,主备切换逻辑:
- 实例 B 指定主库 A,基于主备协议建立连接,实例 B 并把 set_b 发给主库 A
- 实例 A 算出 set_a 与 set_b 的差集,就是所有存在于 set_a 但不存在于 set_b 的 GTID 的集合,判断 A 本地是否包含了这个差集需要的所有 binlog 事务
- 如果不包含,表示 A 已经把实例 B 需要的 binlog 给删掉了,直接返回错误
- 如果确认全部包含,A 从自己的 binlog 文件里面,找出第一个不在 set_b 的事务,发给 B
- 实例 A 之后就从这个事务开始,往后读文件,按顺序取 binlog 发给 B 去执行
参考文章:https://time.geekbang.org/column/article/77427
Q.E.D.