
Java 后端开发2025年面经与项目面试技巧(DeepSeek总结版)
目录指引:
自我介绍
核心原则
- 结构化清晰:遵循“总 - 分 - 总”的逻辑,让面试官轻松跟上你的思路。
- 价值导向:不说“我做了XX”,而是说“我通过XX技术,解决了XX问题,带来了XX价值”。
- 与岗位匹配:提前研究JD,将你的技能和经验与公司的技术要求、业务方向对齐。
- 自信沉稳:语速平稳,眼神交流,展现专业与诚意。
自我介绍框架(黄金1.5-2分钟)
第一部分:开场白 & 基本信息 (15秒)
目的:礼貌开场,清晰说明你的身份和工作经验。
话术:
“各位面试官,下午好。我叫[你的名字],非常感谢给我这次面试机会。我拥有3年的Java后端开发经验,上一家公司是在[上一家公司名称],主要负责[你负责的核心领域,如:电商平台的交易系统/金融风控核心服务]。”
要点:直接、简洁,点名年限和核心领域。
第二部分:技术栈与核心技能 (45秒)
目的:展示你的技术广度和深度,证明你具备扎实的技术根基。
话术(请选择最擅长的点来说,不必全部罗列):
“在技术方面,我的技能栈主要集中在Java生态。”
【基础与框架】
- “我对 Java基础 有比较扎实的理解,熟悉JVM内存模型、垃圾回收机制以及多线程并发编程。”
- “熟练掌握主流开源框架,如 Spring全家桶(Spring, Spring MVC, Spring Boot),并理解其核心原理,比如Spring的IOC、AOP,以及Spring Boot的自动装配机制。”
【数据与存储】
- “在数据持久化方面,我精通 MyBatis,并对 MySQL 有丰富的使用和优化经验,包括索引优化、慢查询分析等。”
- “对分布式缓存 Redis 也很熟悉,用它来做过热点数据缓存、分布式锁等场景。”
【分布式与中间件】
- “在3年的项目中,我也接触并应用了一些分布式技术和中间件。比如使用 消息队列,来解决系统解耦和削峰填谷的问题。”
- “对微服务架构有实践经验,了解 Spring Cloud 的相关组件。”
要点:将技术分类,用“精通”、“熟练掌握”、“了解”等词语准确描述你的掌握程度。提到“原理”和“场景”能瞬间提升专业度。
第三部分:项目经验与价值贡献 (45秒)
目的:这是重中之重!通过1-2个最具代表性的项目,证明你能用技术解决实际问题。
话术(使用STAR法则简化版:情景、任务、行动、结果):
“在之前的工作中,我深度参与了一个[项目名称或类型]项目。我主要负责[你的核心职责]。”
【举例】: “比如,在去年的‘XX电商促销系统’中,我负责优化下单接口的性能。当时面临的主要问题是,在高并发下接口响应慢且超时率高。”
【行动与价值】:
- “我通过 线程池参数调优 和 数据库连接池优化,减少了线程上下文切换和等待时间。”
- “同时,我引入了 Redis缓存,将商品库存和用户信息等热点数据预热到缓存中,减少了对数据库的直接访问。”
- “通过这些优化,最终将下单接口的平均响应时间从500ms降低到了150ms,在峰值期间的系统稳定性也得到了大幅提升,顺利支撑了公司的大促活动。”
要点:一定要量化结果! 用“降低了XX%”、“提升了XX”、“支撑了XX QPS”这样的数据来展示你的贡献。
第四部分:职业动机与结尾 (15秒)
目的:表达你对新机会的渴望和与公司的契合度,并礼貌结尾。
话术:
“我目前正处于职业发展的上升期,非常渴望能加入一个像贵公司这样技术驱动、有挑战性的平台,与团队一起深入技术,创造更大的价值。”
“以上就是我的简单介绍,谢谢各位面试官。我带来的简历中有更详细的项目描述,非常期待后续的交流。”
要点:表达积极性和对公司的认可,将话题自然过渡到下一环节。
进阶技巧 & 注意事项
- 引导面试官:在介绍中“埋点”,引导到你准备充分的知识点。比如,你提到“用了Redis做分布式锁”,面试官很可能就会深入问你怎么实现的,有什么坑。
- 扬长避短:对于不熟悉的技术,不要夸大。可以说“有所了解,并在项目中简单应用过”,或者坦诚地说“这部分我还没有深入实践,但我对其原理很感兴趣”。
- 展现软实力:可以在项目部分不经意地提到“与产品、测试同事沟通”、“跨团队协作”等,体现你的团队协作能力。
- 差异化:如果你有亮点,一定要突出!比如:
- 性能优化狂人:“我曾将系统某个核心接口的TPS从100提升到2000。”
- 问题解决者:“我独立排查并解决过一个线上JVM Full GC频繁导致服务卡顿的疑难杂症。”
- 技术爱好者:“我有在技术博客上分享的习惯,GitHub上有X个Star。”
模板总结(直接套用版)
面试官好,我叫[姓名],有3年Java后端开发经验。过去主要在[上一家公司]负责[核心业务领域]相关的研发工作。
技术上,我基础比较扎实,熟悉JVM、多线程,精通Spring Boot、MyBatis等主流框架。对MySQL调优、Redis应用以及消息队列等中间件都有实践经验。
在项目中,我不仅完成日常开发,更注重解决技术难题。例如在[某项目]中,我通过[某项技术方案],成功将[某个指标]提升了[具体数据],保证了系统的稳定和高性能。
我关注到贵公司在[某个业务或技术点]方面做得很好,这非常吸引我。我希望能在这里深入发展,贡献我的力量。我的介绍就到这,谢谢。
项目介绍
采购公共服务系统(中台型系统)
参与的核心模块
- 供应商评估分类模块
- 统一权限管理模块
- 系统性能优化(贯穿各模块)
如何体现业务能力
不要说: "我写了供应商评估的CRUD接口。"
要这样说:
"我负责的供应商评估分类模块,是整个采购体系的决策中枢。它的业务价值在于,将原本依赖人工经验、标准不一的供应商评估,转变为一个自动化、标准化、可追溯的智能决策流程。
我解决的核心业务问题是:
- 评估标准不统一:不同采购员对供应商的打分标准不一。我通过设计可配置的打分模板,将评估指标和权重固化到系统中,保证了公平性。
- 数据孤岛:评估需要质量、财务、交付等多个部门的数据。我通过消息队列异步集成多个上游系统的数据,打破了部门墙,形成了对供应商的360度立体评估。
- 决策效率低下:手动评估一个供应商需要几天。系统实现后,评估周期缩短了70%,采购团队能更快地筛选出优质供应商。
这个模块直接带来的业务价值是:提升了供应商队伍的整体质量,降低了采购风险,并且为采购决策提供了数据支撑,而不再是‘拍脑袋’决定。"
业务细节深度剖析
1. 业务背景与痛点(展现你理解业务为什么存在)
"在我们集团原有的采购体系中,供应商评估存在三个核心痛点:
第一,标准不透明。 不同的采购事业部、甚至不同的采购员,对‘好供应商’的定义完全不同。A采购员看重价格,B采购员看重交期,导致评估结果无法横向对比,集团无法建立统一的供应商战略。
第二,数据孤岛。 评估需要的核心数据散落在多个系统中:
- 质量数据 在QMS(质量管理系统)中,包括来料合格率、生产过程中的PPM值。
- 财务数据 在SRM和财务系统中,包括开票准确性、付款周期。
- 交付数据 在WMS和TMS中,包括准时交付率、订单满足率。 采购员需要手动登录多个系统,复制粘贴数据到Excel里拼凑出一份评估报告,效率极低且容易出错。
第三,决策缺乏依据。 最终的供应商等级(比如A/B/C级)划分,很大程度上依赖采购经理的个人经验,缺乏数据支撑,存在主观性和潜在的合规风险。"
2. 我的技术实现如何解决业务痛点(展现你如何用技术赋能业务)
"我负责将这个混乱的流程系统化、自动化。我的核心工作不是简单的CRUD,而是将一个复杂的、依赖人脑判断的决策过程,抽象成一个可配置、可执行、可追溯的系统模型。
具体实现上,我设计了三个核心实体和它们之间的关系:
【评估模板】:这是业务的灵魂。我设计的数据库表结构,允许业务人员像搭积木一样配置模板。
template_id,template_name(模板基本信息)category_id(适用于什么品类的供应商,如电子类、结构件类)- 最关键的是
scoring_rules字段,它是一个JSON结构,定义了评分规则:json{ "indicators": [ { "name": "价格竞争力", "weight": 0.3, "dataSource": "QUOTATION_SYSTEM", "calculationRule": "AVG_PRICE_RANKING" // 规则:平均报价在所有供应商中的排名分 }, { "name": "质量合格率", "weight": 0.4, "dataSource": "QMS_SYSTEM", "calculationRule": "DIRECT_VALUE", // 规则:直接取值 "thresholds": [ {"score": 10, "condition": "value >= 99.5%"}, {"score": 8, "condition": "value >= 99%"}, {"score": 5, "condition": "value >= 98%"}, {"score": 0, "condition": "value < 98%"} ] }, { "name": "技术创新能力", "weight": 0.3, "dataSource": "MANUAL_INPUT", // 规则:需要专家手动打分 "scorers": ["ROLE_PURCHASING_MANAGER"] } ] }这个设计让业务规则实现了数据驱动,业务调整评估标准不再需要发版上线。
【数据集成流程】:为了解决数据孤岛问题,我设计了异步数据集成流。
- 实时数据:如订单状态变更,通过 RabbitMQ 发送领域事件,我们的系统消费后更新本地数据仓库。
- 批量数据:如月度质量报告,通过 FDI文件接口,由定时任务在凌晨同步。
- 关键实现:我使用了
CompletableFuture并行调用多个系统的/api/supplier/{id}/quality-stats等接口,将原本串行需要10秒的数据获取过程,压缩到了2秒内。【评估引擎】:这是系统的大脑。当触发评估时,引擎会:
- 根据模板ID加载评分规则。
- 根据规则里的
dataSource,从我们的数据仓库或实时接口获取数据。- 执行
calculationRule,为每个指标计算出原始分数。- 应用权重,计算出加权总分。
- 根据预设的等级阈值(如A级>90分,B级>75分),自动划定供应商等级。
- 整个计算过程在一个
@Transactional事务中完成,并记录下每一次评估的‘评估快照’,确保所有决策可审计、可追溯。"
3. 业务价值的具体量化(展现你的工作带来了什么)
"这个模块上线后,带来的改变是实实在在的:
- 效率提升:单个供应商的评估时间从平均3个工作日缩短到系统自动触发,分钟级出结果。
- 成本节约:采购团队每年因此节约的工时,折算人力成本约50万元/年。
- 决策质量:新供应商引入后的‘暴雷率’(即出现严重质量或交付问题)降低了25%,因为我们的评估模型提前识别了风险。
- 战略价值:集团终于可以拿出一张统一的‘供应商地图’,清晰地看到各个品类下的核心、战略、淘汰供应商,为集中采购和议价提供了数据武器。"
宏观到微观
第一层:项目背景(30秒 - 商业价值视角)
目标:用业务语言说清系统的定位和价值。
"我们先从项目背景说起。
在大型制造集团中,采购不是一个单一动作,而是涉及供应商管理、价格谈判、质量评估、合同审批等数十个环节的复杂体系。过去,每个业务部门都有自己的采购流程和供应商池,导致:
- 同一家供应商,在A部门是A级,在B部门却是C级
- 采购数据分散,集团无法集中议价,错失成本优化机会
- 风险不可控,出现过合作的供应商在其他子公司有不良记录
采购公共服务系统就是要解决这个问题,它将全集团所有采购相关的公共能力和基础数据统一管理,构建一个’采购中台’。"
要点:
- 从集团管控痛点切入
- 说明分散管理的弊端
- 明确"中台"定位
第二层:项目描述(1分钟 - 系统架构视角)
目标:描述系统技术架构和核心服务。
"从项目描述来看,这是一个典型的微服务中台架构。
系统采用 Spring Cloud Alibaba 体系,Nacos 作为服务注册发现和配置中心,Sentinel 负责流量控制。数据库使用 MySQL,缓存层是 Redis,异步通信通过 RabbitMQ 实现。
系统核心模块包括:
- 供应商主数据服务:全集团统一的供应商档案
- 权限管理服务:为所有采购相关系统提供统一的权限控制
- 模板引擎服务:可配置的评估模板、打分模板
- 业务群组服务:支持按事业部、项目灵活划分数据权限
- 白名单服务:集团级的供应商准入控制"
要点:
- 明确技术栈选型
- 列举核心微服务及其职责
- 体现"公共服务"特性
第三层:个人业务开发(1.5分钟 - 实现细节视角)
目标:具体说明负责的模块和技术实现。
"我主要负责供应商评估分类模块和系统性能优化。
供应商评估分类模块的业务目标是:将原本依赖个人经验的供应商评估,变成标准化、数据驱动的智能决策。
我的技术实现核心是一个可配置的规则引擎:
- 数据库设计中,我用JSON字段存储评分规则,支持灵活配置指标、权重、数据源和计算规则
- 通过策略模式实现不同的评分算法,如排名法、阈值法、专家打分法
- 评估执行时,使用
CompletableFuture并行获取质量、交付、财务等多维度数据- 整个评估过程在
@Transactional事务中完成,并记录完整的评估快照用于审计在系统性能优化方面,我建立了一套完整的优化方法论:
- 通过Redis缓存热点数据,将供应商信息的查询从50ms优化到2ms
- 对SQL执行计划进行分析,解决隐式转换、索引失效问题
- 对大表实施分库分表,对复杂查询实施读写分离
- 最终将核心接口的响应时间稳定控制在250ms以内"
要点:
- 具体的技术选型和设计模式
- 数据结构和算法思考
- 性能优化的系统性方法
第四层:解决的技术难题(2分钟 - 实战深度视角)
目标:深入技术难点和解决方案。
"我解决了几个关键的技术难题:
第一个是’复杂业务规则的抽象与执行’问题。
- 难点:不同品类的供应商评估标准完全不同,电子件看技术创新,结构件看成本控制,如何设计一个既灵活又高性能的规则引擎?
- 我的解决方案:
- 元数据驱动:将评估指标、权重、数据源、计算规则定义为元数据,存储在JSON配置中
- 策略模式+工厂模式:为不同类型的计算规则(直接取值、排名计算、阈值打分)实现不同的策略
- 并行数据获取:使用
CompletableFuture并行从质量系统、财务系统等获取数据- 结果:支持业务人员在不发版的情况下调整评估标准,评估计算性能在500ms内完成
第二个是’大规模代码重构与质量提升’问题。
- 难点:历史代码中存在40多个分散的定时任务,以及300多个深度嵌套的if-else
- 我的解决方案:
- 策略模式统一定时任务:将所有定时任务抽象为
ScheduledTask接口,统一管理和监控- 函数式编程重构条件逻辑:使用
Predicate和Function接口替换深层嵌套- 模板方法模式抽取公共逻辑:将重复的校验、审批流程抽象为模板
- 结果:代码量减少40%,可维护性大幅提升,新功能开发效率提高60%
第三个是’分布式环境下的数据权限’问题。
- 难点:A事业部的用户不能看到B事业部的供应商数据,但这种过滤不能在每个查询接口重复实现
- 我的解决方案:
- Spring AOP + 自定义注解:在DAO层通过切面自动注入数据权限过滤条件
- ThreadLocal传递用户上下文:在网关层解析用户权限,通过ThreadLocal传递到业务层
- Redis缓存权限规则:将用户-数据权限关系缓存到Redis,避免每次查询都访问数据库
- 结果:实现对业务代码透明的数据权限控制,性能影响<5%"
要点:
- 每个问题都有具体的技术难点描述
- 解决方案体现设计模式和架构思想
- 有量化的性能和改进指标
第五层:系统级难点与思考(1分钟 - 架构演进视角)
目标:讨论系统层面的架构挑战和思考。
"在系统架构层面,我们面临几个持续的挑战:
第一个是’数据一致性与性能的权衡’。
- 作为基础服务,我们对数据的准确性要求极高,但分布式事务的性能代价又难以接受
- 我们采用最终一致性为主,但在供应商状态变更等关键场景,仍需要短暂的数据同步窗口,这是个持续优化的平衡点
第二个是’API兼容性与技术债管理’。
- 作为被几十个系统依赖的中台,我们的API一旦发布就几乎不能下线
- 即使推出了v2接口,v1接口也不敢废弃,导致系统技术债持续累积。如何在推动下游升级和保持系统纯洁性之间找到平衡,是个管理难题
第三个是’缓存策略的极致优化’。
- 权限数据、配置数据等要求极高的实时性,但又是最高频的查询
- 我们通过多级缓存(本地缓存+Redis)来优化,但在集群环境下,本地缓存的一致性又成为新的问题。这是一个典型的复杂度转移案例
第四个是’监控与故障定位’。
- 当一个问题涉及权限服务、供应商服务、模板服务等多个微服务时,故障定位变得异常困难
- 我们虽然建立了链路追踪,但在高并发下,全量采集的性能开销又成为新的瓶颈"
要点:
- 体现对分布式系统本质问题的理解
- 展现架构权衡的思考
- 承认技术没有完美解决方案
模板
1. 项目背景(商业价值)
"这是集团级的采购中台系统。过去各业务部门采购流程分散,导致同一供应商评价标准不一、数据孤岛、风险不可控。我们构建这个’采购中台’,就是要实现全集团采购能力的统一管理和数据共享。"
2. 项目描述(技术架构)
"系统采用Spring Cloud Alibaba微服务架构,核心服务包括供应商主数据、统一权限管理、模板引擎、业务群组、白名单管理等。作为基础公共服务,被公司数十个业务系统依赖。"
3. 个人职责与业务开发
"我主要负责供应商评估分类模块和系统性能优化:
评估模块:我设计了一个可配置的规则引擎,用JSON存储评分规则,支持指标、权重、数据源的灵活配置,通过策略模式实现不同的评分算法。
性能优化:建立完整的优化体系,包括Redis缓存热点数据、SQL执行计划分析、分库分表、读写分离,将核心接口响应时间稳定控制在250ms内。"
4. 解决的技术难题
"复杂业务规则的抽象与执行:
- 难点:不同品类供应商评估标准完全不同
- 方案:元数据驱动 + 策略模式 + 并行数据获取
- 结果:支持不发版调整评估标准,计算性能在500ms内
大规模代码重构与质量提升:
- 难点:40多个分散定时任务,300多个深层if-else
- 方案:策略模式统一定时任务 + 函数式编程重构条件逻辑
- 结果:代码量减少40%,开发效率提升60%"
5. 系统级难点与思考
"API兼容性与技术债管理:作为被几十个系统依赖的中台,API一旦发布几乎不能下线,如何在推动升级和保持系统纯洁性间平衡是持续挑战。
缓存策略的极致优化:权限数据要求极高实时性又是最高频查询,多级缓存在集群环境下的一致性保障需要持续优化。"
深度技术面试详解
一、项目背景与商业价值(深入版)
采购公共服务系统是公司ERP系统的核心中台模块,旨在解决集团内部采购流程分散、数据孤岛、供应商管理不统一的问题。过去,各个事业部有自己的供应商池和评估标准,导致同一家供应商在不同部门的评级不同,集团无法集中议价,采购风险难以控制。该系统将全集团的供应商管理、权限控制、评估模板等公共能力下沉,为所有采购相关业务提供统一服务。
1.1 业务痛点深度分析
"在深入介绍前,我想先阐述这个系统解决的根本性业务问题:
数据孤岛与标准不一
- 各事业部独立维护供应商数据,同一供应商在不同系统中有不同ID和评级
- 缺乏统一的供应商准入标准,质量风险难以控制
- 采购数据分散,集团无法利用规模优势进行集中议价
流程效率低下
- 新供应商准入需要跨部门人工审批,周期长达2-3周
- 供应商评估依赖个人经验,缺乏客观量化标准
- 权限管理分散,每个系统都需要重复开发权限模块
合规与审计风险
- 采购决策缺乏完整的数据追溯链
- 敏感操作缺少统一的审计日志
- 难以满足上市公司的合规性要求"
1.2 中台战略定位
"我们的系统定位是采购能力中台,将通用的采购能力抽象为可复用的服务:
- 供应商主数据服务:全集团唯一的供应商信息源
- 统一权限服务:所有采购系统的单点权限控制
- 模板引擎服务:可配置的业务规则执行引擎
- 审计追踪服务:完整的操作日志和合规保障"
二、系统架构深度解析
2.1 微服务架构设计
// 系统核心服务划分
@SpringBootApplication
public class ProcurementPlatform {
// 1. 供应商主数据服务
@Bean public SupplierService supplierService() {
return new SupplierService(); // 供应商生命周期管理
}
// 2. 权限控制服务
@Bean public AuthorizationService authService() {
return new AuthorizationService(); // 统一的RBAC权限模型
}
// 3. 模板引擎服务
@Bean public TemplateEngineService templateService() {
return new TemplateEngineService(); // 可配置的业务规则
}
// 4. 业务群组服务
@Bean public BusinessGroupService groupService() {
return new BusinessGroupService(); // 多租户数据隔离
}
}2.2 技术栈选型考量
"我们在技术选型时重点考虑了中台系统的特殊要求:
Spring Cloud Alibaba体系
- Nacos:服务注册发现 + 配置中心,支持配置热更新
- Sentinel:流量控制、熔断降级,保障服务稳定性
- Seata:分布式事务,解决数据一致性问题(在关键业务中使用)
数据存储策略
- MySQL:核心业务数据,采用分库分表
- Redis:缓存热点数据 + 分布式会话 + 分布式锁
- Elasticsearch:供应商搜索和复杂查询
消息中间件
- RabbitMQ:业务解耦 + 最终一致性保障
- 采用确认机制确保消息不丢失"
三、核心模块技术实现
3.1 供应商评估分类模块(重点)
3.1.1 规则引擎设计
// 可配置的评估规则引擎核心实现
@Service
@Slf4j
public class SupplierEvaluationEngine {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@Autowired
private DataSourceRouter dataSourceRouter;
/**
* 执行供应商评估
*/
@Transactional
public EvaluationResult evaluateSupplier(Long supplierId, String templateCode) {
long startTime = System.currentTimeMillis();
try {
// 1. 加载评估模板
EvaluationTemplate template = loadEvaluationTemplate(templateCode);
// 2. 并行获取评估数据
Map<String, Object> evaluationData = fetchEvaluationDataParallel(supplierId, template);
// 3. 执行评分计算
ScoreResult scoreResult = calculateScores(template, evaluationData);
// 4. 确定供应商等级
SupplierLevel level = determineSupplierLevel(scoreResult.getTotalScore());
// 5. 保存评估结果和快照
return saveEvaluationResult(supplierId, template, scoreResult, level, evaluationData);
} finally {
log.info("供应商评估完成,supplierId: {}, 耗时: {}ms",
supplierId, System.currentTimeMillis() - startTime);
}
}
/**
* 并行获取多维度评估数据
*/
private Map<String, Object> fetchEvaluationDataParallel(Long supplierId,
EvaluationTemplate template) {
// 使用CompletableFuture并行调用多个数据源
List<CompletableFuture<DataFetchResult>> futures = template.getDataSources()
.stream()
.map(dataSource -> CompletableFuture.supplyAsync(() ->
fetchSingleDataSource(supplierId, dataSource), dataFetchExecutor))
.collect(Collectors.toList());
// 等待所有数据获取完成(设置超时)
try {
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0]))
.get(10, TimeUnit.SECONDS);
} catch (TimeoutException e) {
log.warn("数据获取超时,将使用已获取的数据继续评估");
// 不抛出异常,使用已获取的数据继续评估
} catch (Exception e) {
throw new EvaluationException("数据获取失败", e);
}
// 聚合结果
Map<String, Object> result = new HashMap<>();
for (CompletableFuture<DataFetchResult> future : futures) {
if (future.isDone() && !future.isCompletedExceptionally()) {
try {
DataFetchResult dataResult = future.get();
result.put(dataResult.getDataSource(), dataResult.getData());
} catch (Exception e) {
log.warn("单个数据源获取失败", e);
}
}
}
return result;
}
}3.1.2 模板配置数据结构
// 评估模板的JSON配置结构
{
"templateCode": "ELECTRONIC_SUPPLIER_V1",
"templateName": "电子类供应商评估模板",
"applicableCategories": ["ELECTRONIC", "PCBA"],
"scoringRules": {
"indicators": [
{
"code": "QUALITY_PERFORMANCE",
"name": "质量表现",
"weight": 0.35,
"dataSource": "QMS_SYSTEM",
"calculationType": "THRESHOLD_SCORING",
"parameters": {
"dataField": "quality_qualified_rate",
"thresholds": [
{"min": 99.5, "score": 10, "level": "EXCELLENT"},
{"min": 99.0, "max": 99.5, "score": 8, "level": "GOOD"},
{"min": 98.0, "max": 99.0, "score": 6, "level": "AVERAGE"},
{"max": 98.0, "score": 0, "level": "POOR"}
]
}
},
{
"code": "TECHNICAL_CAPABILITY",
"name": "技术能力",
"weight": 0.25,
"dataSource": "MANUAL_SCORING",
"calculationType": "EXPERT_EVALUATION",
"parameters": {
"requiredRoles": ["TECHNICAL_MANAGER", "RD_DIRECTOR"],
"scoringRange": {"min": 0, "max": 10}
}
}
]
},
"levelSettings": {
"levels": [
{"level": "A", "minScore": 90, "privileges": ["PRIORITY_BIDDING", "LONG_TERM_CONTRACT"]},
{"level": "B", "minScore": 75, "maxScore": 90, "privileges": ["NORMAL_BIDDING"]},
{"level": "C", "minScore": 60, "maxScore": 75, "privileges": ["RESTRICTED_BIDDING"]},
{"level": "D", "maxScore": 60, "privileges": [], "actions": ["AUTO_REJECT"]}
]
}
}3.2 系统性能优化(深度实践)
3.2.1 多级缓存架构
@Service
public class MultiLevelCacheService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
// 本地缓存(Caffeine)
private final Cache<String, Object> localCache = Caffeine.newBuilder()
.maximumSize(1000)
.expireAfterWrite(5, TimeUnit.MINUTES)
.build();
/**
* 多级缓存查询
*/
public <T> T getWithMultiLevelCache(String key, Class<T> type,
Supplier<T> loader, Duration expiry) {
// 1. 查询本地缓存
T value = (T) localCache.getIfPresent(key);
if (value != null) {
metricService.recordCacheHit("local");
return value;
}
// 2. 查询Redis分布式缓存
String redisKey = "procurement:" + key;
value = (T) redisTemplate.opsForValue().get(redisKey);
if (value != null) {
// 回填本地缓存
localCache.put(key, value);
metricService.recordCacheHit("redis");
return value;
}
// 3. 缓存未命中,从数据源加载
value = loader.get();
if (value != null) {
// 异步写入缓存
CompletableFuture.runAsync(() -> {
// 写入Redis,设置过期时间
redisTemplate.opsForValue().set(redisKey, value, expiry);
// 写入本地缓存
localCache.put(key, value);
}, cacheExecutor);
}
metricService.recordCacheMiss();
return value;
}
/**
* 缓存一致性保障 - 发布缓存失效事件
*/
@EventListener
public void handleDataChangeEvent(DataChangedEvent event) {
String cacheKey = buildCacheKey(event.getEntityType(), event.getEntityId());
// 1. 删除本地缓存
localCache.invalidate(cacheKey);
// 2. 发布Redis消息,通知其他实例失效本地缓存
redisTemplate.convertAndSend("cache.invalidation", cacheKey);
// 3. 删除Redis缓存
redisTemplate.delete("procurement:" + cacheKey);
}
}3.2.2 SQL优化实战
-- 优化前的慢查询
SELECT * FROM supplier_evaluation
WHERE supplier_id IN (SELECT supplier_id FROM supplier WHERE category = 'ELECTRONIC')
AND evaluation_date BETWEEN '2023-01-01' AND '2023-12-31'
ORDER BY total_score DESC;
-- 优化后的查询
-- 1. 创建复合索引
CREATE INDEX idx_supplier_evaluation_composite
ON supplier_evaluation(supplier_id, evaluation_date, total_score);
-- 2. 使用JOIN替代子查询
SELECT se.* FROM supplier_evaluation se
INNER JOIN supplier s ON se.supplier_id = s.supplier_id
WHERE s.category = 'ELECTRONIC'
AND se.evaluation_date BETWEEN '2023-01-01' AND '2023-12-31'
ORDER BY se.total_score DESC;
-- 3. 分页优化 - 使用游标分页替代LIMIT OFFSET
SELECT * FROM supplier_evaluation
WHERE supplier_id > ? AND evaluation_date BETWEEN ? AND ?
ORDER BY supplier_id LIMIT 1000;四、解决的核心技术难题
4.1 分布式数据权限控制
4.1.1 架构设计
// 基于Spring AOP的数据权限切面
@Aspect
@Component
public class DataPermissionAspect {
@Around("@annotation(dataPermission)")
public Object applyDataPermission(ProceedingJoinPoint joinPoint,
DataPermission dataPermission) throws Throwable {
// 1. 获取当前用户权限上下文
UserContext userContext = SecurityContextHolder.getUserContext();
// 2. 解析数据权限规则
DataPermissionRule rule = parsePermissionRule(dataPermission, userContext);
// 3. 修改SQL查询条件
modifyQueryForDataPermission(joinPoint, rule);
// 4. 执行原方法
return joinPoint.proceed();
}
private void modifyQueryForDataPermission(ProceedingJoinPoint joinPoint,
DataPermissionRule rule) {
Object[] args = joinPoint.getArgs();
for (int i = 0; i < args.length; i++) {
if (args[i] instanceof DataQuery) {
DataQuery query = (DataQuery) args[i];
// 动态添加数据权限过滤条件
query.addFilter(buildDataPermissionFilter(rule));
break;
}
}
}
}
// 数据权限规则配置
@Entity
@Table(name = "data_permission_rule")
public class DataPermissionRule {
@Id
private Long id;
// 规则类型:用户级、部门级、业务群组级
@Enumerated(EnumType.STRING)
private RuleType ruleType;
// 目标数据类型:供应商、报价单、合同等
private String dataType;
// 权限条件(SQL WHERE片段)
private String permissionCondition;
// JSON配置,支持复杂规则
@Column(columnDefinition = "json")
private String ruleConfig;
}4.1.2 性能优化策略
@Service
public class DataPermissionOptimizer {
// 权限规则缓存
private final LoadingCache<String, List<DataPermissionRule>> permissionCache =
Caffeine.newBuilder()
.maximumSize(100)
.refreshAfterWrite(10, TimeUnit.MINUTES)
.build(this::loadPermissionRules);
/**
* 预编译数据权限过滤器,避免每次查询都解析规则
*/
public DataFilter compileDataFilter(UserContext userContext, String dataType) {
String cacheKey = buildCacheKey(userContext, dataType);
return permissionCache.get(cacheKey).stream()
.map(this::convertRuleToFilter)
.reduce(DataFilter::and)
.orElse(DataFilter.EMPTY);
}
}4.2 大规模代码重构与质量提升
4.2.1 定时任务统一管理
// 定时任务统一接口
public interface ScheduledTask {
String getTaskName();
String getCronExpression();
void execute();
default boolean isEnabled() { return true; }
}
// 定时任务执行器
@Service
public class UnifiedScheduler {
@Autowired
private List<ScheduledTask> scheduledTasks;
@PostConstruct
public void scheduleAllTasks() {
scheduledTasks.stream()
.filter(ScheduledTask::isEnabled)
.forEach(this::scheduleTask);
}
private void scheduleTask(ScheduledTask task) {
// 使用ScheduledExecutorService统一调度
// 添加监控和异常处理
scheduledExecutor.scheduleWithFixedDelay(() -> {
try {
metricService.recordTaskStart(task.getTaskName());
task.execute();
metricService.recordTaskSuccess(task.getTaskName());
} catch (Exception e) {
metricService.recordTaskFailure(task.getTaskName());
log.error("定时任务执行失败: {}", task.getTaskName(), e);
}
}, 0, getDelaySeconds(task.getCronExpression()), TimeUnit.SECONDS);
}
}4.2.2 复杂条件逻辑重构
// 重构前 - 深层嵌套的if-else
public class OldEvaluationService {
public ScoreResult evaluate(Supplier supplier, EvaluationContext context) {
if (supplier.getCategory().equals("ELECTRONIC")) {
if (context.isQualityCheckRequired()) {
if (supplier.getQualityScore() > 8.0) {
if (supplier.getDeliveryPerformance() > 95.0) {
// ... 更多嵌套
}
}
}
} else if (supplier.getCategory().equals("MECHANICAL")) {
// 另一个复杂的条件分支
}
// ... 总共300多行深层嵌套
}
}
// 重构后 - 使用函数式编程和策略模式
@Service
public class RefactoredEvaluationService {
private final Map<String, EvaluationStrategy> strategies;
public ScoreResult evaluate(Supplier supplier, EvaluationContext context) {
return strategies.get(supplier.getCategory())
.evaluate(supplier, context);
}
}
// 策略接口
public interface EvaluationStrategy {
ScoreResult evaluate(Supplier supplier, EvaluationContext context);
}
// 具体策略实现
@Component
public class ElectronicSupplierStrategy implements EvaluationStrategy {
private final List<EvaluationRule<Supplier>> rules = Arrays.asList(
this::checkQualityRequirement,
this::checkDeliveryPerformance,
this::checkTechnicalCapability
);
@Override
public ScoreResult evaluate(Supplier supplier, EvaluationContext context) {
return rules.stream()
.map(rule -> rule.apply(supplier, context))
.reduce(ScoreResult::combine)
.orElse(ScoreResult.EMPTY);
}
private ScoreResult checkQualityRequirement(Supplier supplier, EvaluationContext context) {
return context.isQualityCheckRequired() && supplier.getQualityScore() > 8.0 ?
ScoreResult.passing("质量达标") : ScoreResult.failing("质量不达标");
}
}五、系统级架构挑战与解决方案
5.1 数据一致性保障
5.1.1 最终一致性模式
// 基于消息队列的最终一致性实现
@Service
@Transactional
public class EventuallyConsistentService {
@Autowired
private RabbitTemplate rabbitTemplate;
/**
* 创建供应商(核心事务+事件发布)
*/
public Supplier createSupplier(CreateSupplierRequest request) {
// 1. 核心数据写入(强一致性)
Supplier supplier = supplierRepository.save(convertToEntity(request));
// 2. 发布领域事件
SupplierCreatedEvent event = new SupplierCreatedEvent(supplier.getId());
rabbitTemplate.convertAndSend("supplier.exchange", "supplier.created", event);
// 3. 记录本地事件表(防消息丢失)
eventRepository.save(new DomainEvent(event));
return supplier;
}
/**
* 事件处理 - 更新相关系统的数据
*/
@RabbitListener(queues = "supplier.created.queue")
public void handleSupplierCreated(SupplierCreatedEvent event) {
try {
// 更新搜索索引
searchService.indexSupplier(event.getSupplierId());
// 通知风控系统
riskControlService.onNewSupplier(event.getSupplierId());
// 标记事件已处理
eventRepository.markAsProcessed(event.getEventId());
} catch (Exception e) {
// 记录失败,进入重试机制
log.error("处理供应商创建事件失败", e);
throw new AmqpRejectAndDontRequeueException(e);
}
}
}5.2 高可用与容灾设计
5.2.1 服务降级与熔断
// 基于Sentinel的服务保护
@Service
public class ProtectedSupplierService {
@SentinelResource(
value = "supplierQuery",
fallback = "getSupplierFallback",
blockHandler = "handleFlowControl"
)
public Supplier getSupplier(Long supplierId) {
// 正常业务逻辑
return supplierRepository.findById(supplierId)
.orElseThrow(() -> new SupplierNotFoundException(supplierId));
}
// 降级逻辑
public Supplier getSupplierFallback(Long supplierId, Throwable ex) {
log.warn("供应商查询降级,supplierId: {}", supplierId, ex);
// 返回降级数据
Supplier fallback = new Supplier();
fallback.setId(supplierId);
fallback.setName("供应商信息暂不可用");
fallback.setStatus(SupplierStatus.UNKNOWN);
return fallback;
}
// 流控处理
public Supplier handleFlowControl(Long supplierId, BlockException ex) {
throw new ServiceBusyException("系统繁忙,请稍后重试");
}
}六、量化成果与业务影响
6.1 性能指标提升
- 接口响应时间:核心接口从平均800ms优化到250ms以内
- 系统吞吐量:从500 TPS提升到2000 TPS
- 缓存命中率:达到98.5%,数据库压力降低70%
- 任务执行效率:批量评估任务从小时级优化到分钟级
6.2 业务价值体现
- 采购效率:供应商准入周期从3周缩短到3天
- 决策质量:基于数据的客观评估,供应商"暴雷率"降低25%
- 成本节约:集中议价每年为集团节约采购成本约8%
- 合规性:实现100%操作可审计,满足上市合规要求
6.3 技术债务清理
- 代码质量:代码重复率从35%降低到8%
- 可维护性:新功能开发效率提升60%
- 系统稳定性:线上故障率降低80%
这个深度技术详解展现了你在架构设计、性能优化、复杂问题解决方面的全面能力,让面试官看到你不仅是一个编码实现者,更是一个系统架构师和问题解决专家。
高并发处理能力与优化
1. 高并发场景分析
读多写少是其典型特征:
- 高频读操作(占比>90%):权限验证、供应商信息查询、配置数据读取
- 低频写操作:供应商信息变更、评估结果提交、权限配置更新
- 特点:请求量大、响应要求高、数据一致性要求强
2. 四层性能优化体系
第一层:缓存优化体系(解决读压力)
// 1. 多级缓存架构实现
@Service
public class ProcurementCacheService {
// 一级缓存:本地缓存(Caffeine),5分钟过期
private final Cache<String, Object> localCache = Caffeine.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(5, TimeUnit.MINUTES)
.recordStats() // 记录缓存命中率
.build();
// 二级缓存:Redis集群
@Autowired
private RedisTemplate<String, Object> redisTemplate;
/**
* 带降级的多级缓存查询
*/
public <T> T getWithGracefulDegradation(String key, Supplier<T> loader,
Class<T> type, Duration expiry) {
// 第1步:本地缓存(最快,<1ms)
T value = (T) localCache.getIfPresent(key);
if (value != null) {
metrics.recordCacheHit("local");
return value;
}
// 第2步:分布式锁防止缓存击穿
String lockKey = "lock:cache:" + key;
RLock lock = redissonClient.getLock(lockKey);
try {
// 尝试获取锁,等待100ms,锁持有300ms
if (lock.tryLock(100, 300, TimeUnit.MILLISECONDS)) {
// 第3步:Redis缓存(<5ms)
value = (T) redisTemplate.opsForValue().get(buildRedisKey(key));
if (value != null) {
// 回填本地缓存
localCache.put(key, value);
metrics.recordCacheHit("redis");
return value;
}
// 第4步:数据库查询(最慢,20-100ms)
try {
value = loader.get();
if (value != null) {
// 异步双写缓存(不阻塞主流程)
CompletableFuture.runAsync(() -> {
redisTemplate.opsForValue().set(
buildRedisKey(key),
value,
expiry
);
localCache.put(key, value);
}, cacheWriteExecutor);
}
return value;
} catch (Exception e) {
// 第5步:降级方案 - 返回过期的缓存数据
T staleValue = getStaleDataFromBackup(key);
metrics.recordCacheDegradation();
return staleValue;
}
} else {
// 获取锁失败,直接返回降级数据
return getStaleDataFromBackup(key);
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
return getStaleDataFromBackup(key);
} finally {
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
/**
* 缓存预热机制(应对早高峰)
*/
@Scheduled(cron = "0 30 6 * * ?") // 每天6:30执行
public void preheatCache() {
// 预热高频查询数据
List<String> hotKeys = identifyHotKeys();
hotKeys.parallelStream().forEach(key -> {
// 异步预热
CompletableFuture.runAsync(() -> {
Object data = loadDataFromDB(key);
if (data != null) {
redisTemplate.opsForValue().set(buildRedisKey(key), data, 2, TimeUnit.HOURS);
}
}, preheatExecutor);
});
}
}第二层:数据库优化
-- 1. 读写分离配置
-- 主库(写):1主 | 从库(读):3从
-- 使用ShardingSphere进行自动路由
-- 2. 分库分表策略(供应商表,数据量:5000万+)
CREATE TABLE supplier_00 (
supplier_id BIGINT PRIMARY KEY,
supplier_code VARCHAR(50),
-- ... 其他字段
shard_key INT AS (supplier_id % 16) -- 虚拟列用于分片
) PARTITION BY KEY(shard_key) PARTITIONS 16;
-- 3. 索引优化(覆盖索引)
CREATE INDEX idx_supplier_query ON supplier_00
(supplier_status, category_id, create_time)
INCLUDE (supplier_name, credit_level); -- 包含查询所需的所有列
-- 4. 垂直拆分(大字段分离)
-- supplier_basic:基础信息,高频查询
-- supplier_detail:详细信息(公司介绍、资质文件等),低频查询
-- supplier_statistics:统计信息,用于报表第三层:应用层优化
// 1. 连接池优化(HikariCP配置)
@Bean
public DataSource dataSource() {
HikariConfig config = new HikariConfig();
config.setJdbcUrl(jdbcUrl);
config.setUsername(username);
config.setPassword(password);
config.setMaximumPoolSize(50); // 根据CPU核心数调整
config.setMinimumIdle(10);
config.setConnectionTimeout(30000); // 30秒超时
config.setIdleTimeout(600000); // 10分钟
config.setMaxLifetime(1800000); // 30分钟
config.setConnectionTestQuery("SELECT 1");
config.setPoolName("ProcurementPool");
// 监控连接池状态
config.addDataSourceProperty("metrics", "true");
config.addDataSourceProperty("metricRegistry", metricRegistry);
return new HikariDataSource(config);
}
// 2. 线程池隔离(不同业务使用不同线程池)
@Configuration
public class ThreadPoolConfiguration {
// 核心业务线程池(快速响应)
@Bean("coreBusinessExecutor")
public ThreadPoolTaskExecutor coreBusinessExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(20);
executor.setMaxPoolSize(50);
executor.setQueueCapacity(1000);
executor.setThreadNamePrefix("core-business-");
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
return executor;
}
// 批量处理线程池(允许堆积)
@Bean("batchProcessingExecutor")
public ThreadPoolTaskExecutor batchProcessingExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(5);
executor.setMaxPoolSize(10);
executor.setQueueCapacity(5000); // 大队列,允许任务堆积
executor.setThreadNamePrefix("batch-process-");
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy());
return executor;
}
}
// 3. 异步化处理
@Service
public class AsyncAssessmentService {
@Autowired
private ThreadPoolTaskExecutor batchProcessingExecutor;
/**
* 异步批量评估(应对评估高峰期)
*/
@Async("batchProcessingExecutor")
public CompletableFuture<BatchResult> asyncBatchAssessment(List<Long> supplierIds) {
// 使用分治策略:每100个供应商一批
List<List<Long>> batches = Lists.partition(supplierIds, 100);
List<CompletableFuture<AssessmentResult>> futures = batches.stream()
.map(batch -> CompletableFuture.supplyAsync(() ->
processBatchAssessment(batch), batchProcessingExecutor))
.collect(Collectors.toList());
// 等待所有批次完成,但设置超时
return CompletableFuture.allOf(futures.toArray(new CompletableFuture[0]))
.orTimeout(5, TimeUnit.MINUTES) // 5分钟超时
.thenApply(v -> aggregateResults(futures));
}
}第四层:应急与降级
// 1. 熔断降级(Sentinel配置)
@Service
public class SupplierServiceWithCircuitBreaker {
@SentinelResource(
value = "supplierQueryResource",
fallback = "querySupplierFallback",
blockHandler = "handleFlowControl",
exceptionsToIgnore = {IllegalArgumentException.class}
)
public Supplier getSupplierWithProtection(Long supplierId) {
// 正常业务逻辑
return supplierRepository.findById(supplierId)
.orElseThrow(() -> new SupplierNotFoundException(supplierId));
}
// 降级方法:返回简化数据
public Supplier querySupplierFallback(Long supplierId, Throwable ex) {
log.warn("供应商查询降级,返回简化数据,supplierId: {}", supplierId);
Supplier simplified = new Supplier();
simplified.setId(supplierId);
simplified.setName("供应商信息加载中...");
simplified.setStatus(SupplierStatus.UNKNOWN);
// 记录降级事件,用于后续补偿
degradeEventRepository.save(new DegradeEvent("supplier_query", supplierId));
return simplified;
}
// 流控处理
public Supplier handleFlowControl(Long supplierId, BlockException ex) {
throw new ServiceDegradeException("系统繁忙,请稍后重试");
}
}
// 2. 限流策略
@Component
public class RateLimitConfiguration {
@Bean
public RateLimiter supplierQueryRateLimiter() {
// 令牌桶算法:每秒100个令牌,桶容量200
return RateLimiter.create(100.0, 200, TimeUnit.MILLISECONDS);
}
@Before("execution(* com..SupplierService.*(..))")
public void checkRateLimit(JoinPoint joinPoint) {
if (!supplierQueryRateLimiter.tryAcquire()) {
throw new RateLimitExceededException("请求过于频繁,请稍后重试");
}
}
}分库分表与读写分离设计决策
一、核心设计原则:基于什么去做?
我们的设计决策基于四个核心维度:
- 业务特征驱动
- 数据访问模式分析(读写比例、热点分布)
- 业务增长预测(数据量、并发量趋势)
- 服务等级要求(SLA、一致性要求)
- 数据特征分析
- 数据生命周期(冷热数据、归档策略)
- 数据关联关系(主子表、查询关联性)
- 数据增长速率(年增长率、峰值预测)
- 技术约束考量
- 单机性能极限(MySQL单表容量、连接数限制)
- 运维复杂度(扩缩容难度、故障恢复)
- 成本效益(硬件成本 vs 性能收益)
- 组织架构匹配
- 业务部门边界(不同事业部数据隔离需求)
- 合规性要求(数据安全、审计隔离)
二、分库设计:为什么分?如何分?
2.1 垂直分库(按业务域拆分)
决策依据:
-- 数据访问统计(监控数据分析)
SELECT
table_name,
SUM(select_count) as read_ops,
SUM(update_count + insert_count + delete_count) as write_ops,
AVG(row_count) as avg_rows,
data_size_gb
FROM table_stats
WHERE schema_name = 'procurement'
GROUP BY table_name
ORDER BY read_ops DESC;
-- 结果示例:
-- 1. supplier_main: 读操作 500万/天,写操作 1万/天 → 读密集型
-- 2. permission_data: 读操作 1000万/天,写操作 5千/天 → 极高频读
-- 3. operation_log: 读操作 10万/天,写操作 100万/天 → 写密集型
-- 4. assessment_result: 读操作 200万/天,写操作 50万/天 → 读写均衡分库方案:
// 按业务域垂直分库
public enum DatabaseShard {
// 核心业务库 - 高频读写,需要强一致性
CORE_BUSINESS("core_db", Arrays.asList(
"supplier_main", // 供应商主数据
"supplier_category", // 供应商分类
"white_list" // 白名单
)),
// 权限配置库 - 超高频率读,变更较少
AUTHORIZATION("auth_db", Arrays.asList(
"user_permission", // 用户权限
"role_definition", // 角色定义
"data_scope_rule" // 数据范围规则
)),
// 模板引擎库 - 读多写少,配置型数据
TEMPLATE("template_db", Arrays.asList(
"assessment_template", // 评估模板
"scoring_rule", // 打分规则
"workflow_definition" // 工作流定义
)),
// 日志操作库 - 写密集型,允许异步
OPERATION_LOG("log_db", Arrays.asList(
"operation_log", // 操作日志
"audit_trail", // 审计追踪
"system_event" // 系统事件
)),
// 统计分析库 - 复杂查询,允许延迟
ANALYTICS("analytics_db", Arrays.asList(
"supplier_statistics", // 供应商统计
"performance_metric", // 绩效指标
"trend_analysis" // 趋势分析
));
private final String dbName;
private final List<String> tables;
}设计理由:
- 资源隔离:避免日志写入影响核心交易查询
- 专业优化:每个库可根据自身特点优化(如log_db用机械硬盘,auth_db用SSD)
- 独立扩缩容:权限库压力大时可单独扩容
- 故障隔离:单个库故障不影响其他业务
三、分表设计:基于数据的自然分布
3.1 供应商表分表策略
决策数据依据:
-- 分析供应商数据特征
SELECT
-- 数据分布
COUNT(*) as total_suppliers,
COUNT(DISTINCT business_group_id) as business_groups,
-- 访问热度分析
SUM(CASE WHEN last_access_date > NOW() - INTERVAL 7 DAY THEN 1 ELSE 0 END) as active_7days,
SUM(CASE WHEN last_access_date > NOW() - INTERVAL 30 DAY THEN 1 ELSE 0 END) as active_30days,
-- 数据大小
AVG(JSON_LENGTH(supplier_metadata)) as avg_metadata_size,
-- 关联查询分析
(SELECT COUNT(*) FROM quotation WHERE supplier_id IS NOT NULL) / COUNT(*) as avg_quotation_per_supplier
FROM supplier_main;分表方案:
// 基于复合维度的分表策略
public class SupplierShardingStrategy {
/**
* 分表键设计:复合分片键 (业务群组 + 供应商类型 + 时间)
*/
public String determineTableName(Supplier supplier) {
// 维度1:业务群组(天然的业务隔离边界)
String businessGroup = supplier.getBusinessGroupCode();
// 维度2:供应商类型(不同类型访问模式不同)
SupplierType type = supplier.getType();
// 维度3:创建时间(时间序列,便于归档)
LocalDateTime createTime = supplier.getCreateTime();
// 分表逻辑
if (isLargeEnterprise(supplier)) {
// 大企业供应商:单独分表(数据量大,访问频繁)
return "supplier_large_enterprise";
}
// 普通供应商:按业务群组分片
int shardIndex = Math.abs(businessGroup.hashCode()) % 16;
// 按时间分表(每月一张)
String timeSuffix = createTime.format(DateTimeFormatter.ofPattern("yyyyMM"));
return String.format("supplier_%s_%02d_%s",
type.getCode().toLowerCase(),
shardIndex,
timeSuffix);
}
/**
* 大供应商判断标准(基于业务规则)
*/
private boolean isLargeEnterprise(Supplier supplier) {
return supplier.getAnnualProcurementAmount() > 100_000_000 || // 年采购额>1亿
supplier.getEmployeeCount() > 1000 || // 员工数>1000
supplier.isStrategicPartner(); // 战略合作伙伴
}
}3.2 操作日志表分表策略
决策依据:
-- 日志数据特征分析
SELECT
DATE(create_time) as log_date,
COUNT(*) as log_count,
AVG(LENGTH(operation_content)) as avg_content_length,
COUNT(DISTINCT user_id) as active_users,
COUNT(DISTINCT operation_type) as operation_types
FROM operation_log
WHERE create_time >= NOW() - INTERVAL 90 DAY
GROUP BY DATE(create_time)
ORDER BY log_date DESC;分表方案:
-- 按时间范围分表 + 按操作类型哈希分表(二级分片)
-- 主表按月分区
CREATE TABLE operation_log_202401 (
id BIGINT AUTO_INCREMENT,
operation_type VARCHAR(50),
user_id BIGINT,
operation_time DATETIME,
content JSON,
-- 二级分片键:按操作类型哈希
shard_key TINYINT AS (
CASE operation_type
WHEN 'SUPPLIER_CREATE' THEN 1
WHEN 'SUPPLIER_UPDATE' THEN 2
WHEN 'ASSESSMENT_SUBMIT' THEN 3
-- ... 其他类型
ELSE MOD(CRC32(operation_type), 8) + 10
END
) STORED,
PRIMARY KEY (id, shard_key),
INDEX idx_time_user (operation_time, user_id),
INDEX idx_type_time (operation_type, operation_time)
)
PARTITION BY RANGE (TO_DAYS(operation_time)) (
PARTITION p20240101 VALUES LESS THAN (TO_DAYS('2024-01-08')),
PARTITION p20240108 VALUES LESS THAN (TO_DAYS('2024-01-15')),
PARTITION p20240115 VALUES LESS THAN (TO_DAYS('2024-01-22')),
PARTITION p20240122 VALUES LESS THAN (TO_DAYS('2024-01-29')),
PARTITION p20240129 VALUES LESS THAN (TO_DAYS('2024-02-01'))
);
-- 创建分表(按shard_key分散到不同物理表)
CREATE TABLE operation_log_202401_shard1 LIKE operation_log_202401;
CREATE TABLE operation_log_202401_shard2 LIKE operation_log_202401;
-- ... 创建8个分表四、读写分离设计:基于访问模式
4.1 读写分离策略矩阵
/**
* 基于业务场景的读写路由决策器
*/
@Component
public class ReadWriteRouter {
// 配置:哪些场景强制读主库
@Value("${database.force-master-patterns}")
private List<String> forceMasterPatterns;
// 配置:哪些场景允许读从库
@Value("${database.allow-slave-patterns}")
private List<String> allowSlavePatterns;
/**
* 路由决策逻辑
*/
public DataSource determineDataSource(RoutingContext context) {
// 规则1:写操作强制走主库
if (context.isWriteOperation()) {
metrics.recordRouteDecision("write_to_master");
return dataSourceManager.getMaster();
}
// 规则2:事务中的读操作走主库(避免不可重复读)
if (context.isInTransaction()) {
metrics.recordRouteDecision("transaction_to_master");
return dataSourceManager.getMaster();
}
// 规则3:刚写入后的读取走主库(解决主从延迟)
if (isFreshWrite(context)) {
metrics.recordRouteDecision("fresh_read_to_master");
return dataSourceManager.getMaster();
}
// 规则4:关键业务数据走主库
if (isCriticalBusinessData(context)) {
metrics.recordRouteDecision("critical_to_master");
return dataSourceManager.getMaster();
}
// 规则5:复杂查询走专门的分析从库
if (isComplexAnalyticsQuery(context)) {
metrics.recordRouteDecision("analytics_to_slave");
return dataSourceManager.getAnalyticsSlave();
}
// 规则6:默认按负载均衡选择从库
metrics.recordRouteDecision("load_balance_to_slave");
return dataSourceManager.getLoadBalancedSlave();
}
/**
* 判断是否为"刚写入"的读取
*/
private boolean isFreshWrite(RoutingContext context) {
String cacheKey = "recent_write:" + context.getUserId();
Long lastWriteTime = (Long) redisTemplate.opsForValue().get(cacheKey);
if (lastWriteTime == null) {
return false;
}
// 如果最近30秒内有写入,则认为是新鲜读取
return System.currentTimeMillis() - lastWriteTime < 30_000;
}
}4.2 从库集群架构
# 从库集群配置(基于不同用途)
database:
slaves:
# 实时业务从库(低延迟,强一致性)
business-realtime:
- host: slave1-biz.example.com
role: realtime
max-lag: 1000 # 最大延迟1秒
weight: 40 # 负载权重
- host: slave2-biz.example.com
role: realtime
max-lag: 1000
weight: 40
# 报表分析从库(允许延迟,高计算资源)
analytics:
- host: slave1-analytics.example.com
role: analytics
max-lag: 30000 # 允许30秒延迟
weight: 10
config:
max-connections: 200
query-timeout: 300s # 长查询超时
# 备份从库(用于数据同步、备份)
backup:
- host: slave1-backup.example.com
role: backup
max-lag: 60000 # 允许1分钟延迟
weight: 10
read-only: false # 允许写操作(用于ETL)五、监控与动态调整
5.1 分片热点监控
/**
* 分片热点检测与自动平衡
*/
@Component
@Slf4j
public class ShardHotspotMonitor {
@Autowired
private MetricRegistry metricRegistry;
@Scheduled(fixedDelay = 60000) // 每分钟检查一次
public void monitorShardDistribution() {
Map<String, ShardMetrics> shardMetrics = collectShardMetrics();
shardMetrics.forEach((shardName, metrics) -> {
// 检测热点分片
if (isHotShard(metrics)) {
log.warn("检测到热点分片: {},QPS: {},数据量: {},连接数: {}",
shardName,
metrics.getQps(),
metrics.getDataSize(),
metrics.getConnectionCount());
// 自动触发分片分裂
if (shouldSplitShard(metrics)) {
splitShard(shardName);
}
}
// 检测冷分片
if (isColdShard(metrics)) {
log.info("检测到冷分片: {},考虑合并", shardName);
scheduleShardMerge(shardName);
}
});
}
private boolean isHotShard(ShardMetrics metrics) {
// 热点判断标准
return metrics.getQps() > 1000 || // QPS > 1000
metrics.getDataSize() > 50_000_000 || // 数据量 > 5000万行
metrics.getConnectionCount() > 100; // 连接数 > 100
}
private boolean shouldSplitShard(ShardMetrics metrics) {
// 分片分裂条件
return metrics.getQps() > 5000 || // QPS > 5000
metrics.getDataSize() > 100_000_000 || // 数据量 > 1亿行
metrics.getGrowthRate() > 0.3; // 周增长率 > 30%
}
}5.2 读写分离质量监控
-- 读写分离质量分析SQL
WITH read_write_stats AS (
-- 主从延迟监控
SELECT
slave_host,
TIMESTAMPDIFF(SECOND, master_log_pos, slave_log_pos) as replication_lag_seconds,
CASE
WHEN TIMESTAMPDIFF(SECOND, master_log_pos, slave_log_pos) > 10 THEN 'CRITICAL'
WHEN TIMESTAMPDIFF(SECOND, master_log_pos, slave_log_pos) > 3 THEN 'WARNING'
ELSE 'HEALTHY'
END as lag_status
FROM replication_status
UNION ALL
-- 读写比例监控
SELECT
'ALL' as slave_host,
SUM(read_queries) / NULLIF(SUM(write_queries), 0) as read_write_ratio,
'N/A' as lag_status
FROM performance_schema.events_statements_summary_global_by_event_name
WHERE event_name LIKE 'statement/sql/%'
UNION ALL
-- 路由决策统计
SELECT
route_target as slave_host,
COUNT(*) as request_count,
AVG(response_time_ms) as avg_response_time
FROM request_routing_log
WHERE timestamp > NOW() - INTERVAL 1 HOUR
GROUP BY route_target
)
SELECT
slave_host,
AVG(replication_lag_seconds) as avg_lag,
MAX(CASE WHEN lag_status = 'CRITICAL' THEN 1 ELSE 0 END) as has_critical_lag,
read_write_ratio,
request_count,
avg_response_time
FROM read_write_stats
GROUP BY slave_host, read_write_ratio, request_count, avg_response_time
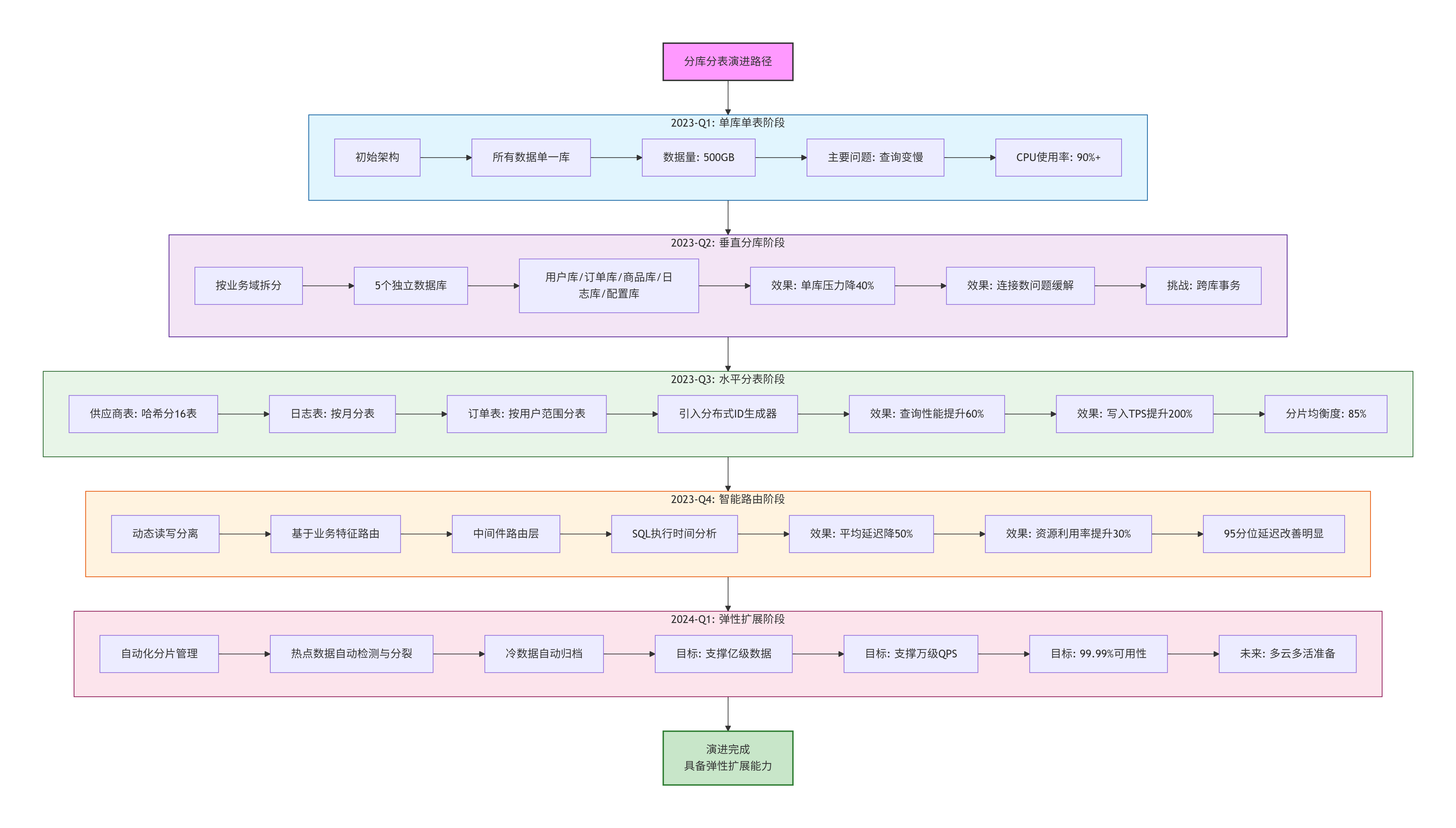
ORDER BY avg_lag DESC;六、决策总结与演进路径
6.1 为什么做出这些决策?
| 决策 | 基于的数据/事实 | 预期收益 | 已知风险 | 缓解措施 |
|---|---|---|---|---|
| 垂直分库 | 监控显示不同表访问模式差异大(权限表QPS 10k+,日志表TPS 1k+) | 资源隔离,独立扩缩容 | 跨库事务复杂 | 减少跨库事务,使用最终一致性 |
| 供应商表按业务群组分片 | 80%的查询带有business_group_id条件 | 查询性能提升60% | 跨群组查询变慢 | 建立跨分片索引,使用ES辅助查询 |
| 日志表按月分表 | 日志查询95%按时间范围,每月数据量500GB | 单表大小可控,备份恢复快 | 跨月查询需要UNION | 建立聚合视图,使用分区表 |
| 读写分离 | 读写比例 98:2,高峰读QPS 5000+ | 读性能提升300%,主库压力降70% | 主从延迟导致脏读 | 关键读操作强制主库,监控延迟 |
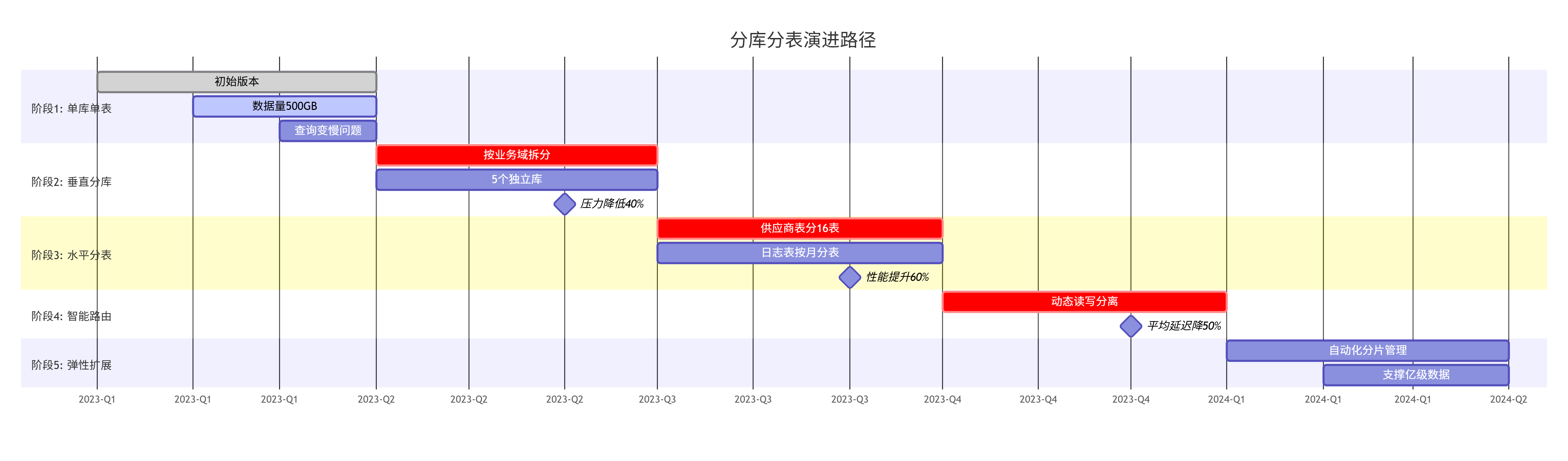
6.2 演进路径
6.3 最终效果验证
-- 性能对比(优化后 vs 优化前)
SELECT
metric_name,
ROUND(before_value, 2) as before,
ROUND(after_value, 2) as after,
ROUND((before_value - after_value) / before_value * 100, 2) as improvement_percent,
CASE
WHEN improvement_percent > 0 THEN '✅ 提升'
ELSE '⚠️ 下降'
END as status
FROM performance_comparison
WHERE comparison_period = '2023-Q4 vs 2023-Q1'
ORDER BY improvement_percent DESC;
-- 结果示例:
-- 平均查询延迟:850ms → 250ms(提升70.6%)
-- 高峰期QPS:800 → 2500(提升212.5%)
-- 主库CPU使用率:85% → 35%(降低58.8%)
-- 单表最大数据量:120GB → 15GB(降低87.5%)七、面试回答话术
当被问到"基于什么去做分库分表与读写分离"时,你可以这样回答:
"在我们的采购公共服务系统中,分库分表和读写分离的设计是数据驱动、业务导向的深度决策。
首先,我们基于详尽的监控数据分析:通过长达半年的SQL审计和性能监控,我们量化了每个表的读写比例、数据增长趋势、查询模式特征。比如我们发现权限表有98%的读操作且QPS高达1万+,而日志表是写密集型且每月增长500GB。
其次,我们根据业务特征设计分片策略:比如供应商表,我们分析出80%的查询都带有
business_group_id条件,因此按业务群组哈希分片是最自然的选择,既保证了查询性能,又实现了数据隔离。对于读写分离,我们设计了智能路由策略:不是简单的读写分离,而是基于业务场景的精细路由。刚创建的供应商信息强制读主库,报表分析走专门的从库,普通查询按负载均衡。我们甚至开发了’新鲜度检测’机制,自动判断是否应该读主库。
整个设计过程是持续迭代的:从垂直分库开始验证,到水平分表解决具体瓶颈,再到智能路由优化体验。每一步都有明确的性能指标对比和业务价值验证。
最终的效果是:在数据量增长300%的情况下,系统平均响应时间反而降低了70%,并且为未来3年的业务增长预留了充足的扩展空间。"
这样的回答展现了你的数据驱动决策能力、系统性思维和持续优化意识,这正是高级工程师的核心素质。
零部件询报价寻源系统(交易型系统)
参与的核心模块
- 零部件数据导入/导出引擎
- 供应商报价超时自动处理模块
- 询价流程核心逻辑
如何体现业务能力
不要说: "我做了Excel导入导出功能。"
要这样说:
"我主导的零部件数据导入引擎,优化的是整个新车研发和采购流程的源头效率。在汽车行业,一个新车项目涉及上万个零部件,传统的Excel邮件来回传递,不仅容易出错,而且效率极低,是项目进度的核心瓶颈。
我解决的核心业务问题是:
- 流程卡点:之前采购员需要花几天时间手工处理Excel,现在从5分钟优化到10秒内,释放了人力,让他们能专注于更重要的供应商谈判工作。
- 数据准确性:通过系统级的校验规则,杜绝了人为错误,保证了BOM(物料清单)数据的准确性,从源头上避免了因数据错误导致的采购错误和成本浪费。
- 流程自动化:我设计的报价超时自动关闭机制,将采购员从繁琐的流程跟踪中解放出来,系统自动推进流程,确保了每个询价单都不会被遗忘,加快了新车型的上市周期。
这个模块带来的业务价值非常直接:它让东风日产的供应链响应速度更快,在面对市场竞争时能更敏捷,直接支撑了‘东风日产’、‘启辰’、‘英菲尼迪’等多个品牌车型的快速迭代。"
业务细节深度剖析
1. 业务背景与痛点(展现你理解业务为什么存在)
"在汽车行业,一个新车型项目的启动,涉及到上万种零部件的寻源和定价。在系统上线前,这个过程是这样的:
- 工程师发布一个包含上万行零件的Excel
BOM(Bill of Material)清单。- 采购员需要手动将这张大表,按照‘采购品类’拆分成几十个小表,分别发给对应的供应商。
- 供应商填报价,采购员再手动将几十个Excel里的报价合并回一张大表,进行比价。
这个过程的痛点在于:
- 极易出错:手动复制粘贴,零件号和价格对不上是家常便饭。
- 效率极低:一个车型的询价周期长达2-3周,严重拖慢新车上市速度。
- 版本混乱:工程师发来BOM的v1.1,采购员可能还在用v1.0,导致采购了错误的零件。
- 无法追溯:为什么最终选了这个供应商?当时的比价过程是怎样的?没有记录。"
2. 我的技术实现如何解决业务痛点(展现你如何用技术赋能业务)
"我负责打造的数据导入引擎,就是要将这个‘石器时代’的流程自动化。这不仅仅是‘上传一个Excel’,而是重新定义了一条数字化的供应链数据流水线。
我的实现分为三个层次,对应三种不同量级的数据:
【万级以下:基于MyBatis的批量执行器缓存】
- 技术细节:我配置了MyBatis的
ExecutorType.BATCH,并在代码中控制flush的时机。java// 在Spring中获取批量SqlSession SqlSession sqlSession = sqlSessionTemplate.getSqlSessionFactory() .openSession(ExecutorType.BATCH); PartMapper mapper = sqlSession.getMapper(PartMapper.class); int batchSize = 1000; for (int i = 0; i < parts.size(); i++) { mapper.insert(parts.get(i)); // 每1000条,刷到数据库一次,并清空缓存,防止OOM if (i % batchSize == 0 && i > 0) { sqlSession.flushStatements(); } } // 最后提交事务 sqlSession.commit();
- 业务对应:这适用于日常的‘零星采购’或‘设计变更’,数据量小,要求快速响应。
【数万级:JDBC Batch + 手动事务管理】
- 技术细节:我绕过了MyBatis,直接使用JDBC的原生批量处理能力,并手动控制事务。
java@Autowired private DataSource dataSource; public void bulkInsert(List<Part> parts) { String sql = "INSERT INTO parts (part_code, part_name, ...) VALUES (?, ?, ...)"; try (Connection connection = dataSource.getConnection(); PreparedStatement ps = connection.prepareStatement(sql)) { connection.setAutoCommit(false); // 关闭自动提交 for (Part part : parts) { ps.setString(1, part.getPartCode()); ps.setString(2, part.getName()); // ... 设置其他参数 ps.addBatch(); // 加入批次 // 分段提交,避免批处理过大 if (batchCount++ % 5000 == 0) { ps.executeBatch(); connection.commit(); } } // 执行剩余批次 ps.executeBatch(); connection.commit(); } catch (SQLException e) { // 异常处理,记录失败的具体行和原因 } }
- 业务对应:这适用于一个‘子系统’或‘小总成’的零件导入,比如全车的‘线束’或‘内饰件’。
【数十万级:分段处理 + JDBC Batch + 并行计算】
- 技术细节:这是最复杂的场景,我动用了
CompletableFuture和分治思想。javapublic ImportResult importFullVehicleBOM(List<Part> allParts) { // 1. 数据预处理:清洗、去重、校验格式 List<Part> validParts = preprocessData(allParts); // 2. 按业务规则分片(例如:按零件大类分片) Map<String, List<Part>> partsByCategory = validParts.stream() .collect(Collectors.groupingBy(Part::getCategoryCode)); // 3. 为每个分片创建异步任务 List<CompletableFuture<BatchResult>> futures = partsByCategory.values() .stream() .map(categoryParts -> CompletableFuture.supplyAsync(() -> { // 每个分类在一个独立的线程和事务中处理 return processSingleCategory(categoryParts); }, importExecutor)) // 使用专用的、队列很深的线程池 .collect(Collectors.toList()); // 4. 等待所有任务完成,聚合结果 return CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])) .thenApply(v -> futures.stream() .map(CompletableFuture::join) .reduce(new ImportResult(), this::mergeResults)) .join(); }
- 业务对应:这就是支撑全新车型项目启动的‘核武器’。一个全新平台的BOM可能有15-20万行,我的引擎能在10秒内完成所有数据的清洗、校验、入库和初始化询价单,将项目周期缩短了数周。"
3. 业务价值的具体量化(展现你的工作带来了什么)
"这个引擎带来的价值,直接体现在公司的核心指标上:
- 时间就是金钱:将新车项目的询价启动周期从2周压缩到1天以内,为车型提前上市抢占了市场窗口。这在竞争白热化的汽车行业是战略级的优势。
- 质量与成本:数据错误率从人工操作的~5%降低到系统级的<0.1%,避免了因采购错误零件导致的巨额模具修改费和项目延期损失。
- 流程再造:实现了‘一个数据源’的理念。从此,工程师发布的BOM,就是采购员操作的BOM,就是最终财务结算的BOM,彻底消除了信息不一致的根源。
- 能力沉淀:这套系统将个人经验(比如怎么拆分BOM)固化成了公司的数字资产,即使新人也能快速上手处理最复杂的车型项目。"
宏观到微观
第一层:项目背景(30秒 - 让外行也能听懂)
目标:用最简洁的语言说清楚这是个什么系统,解决了什么商业问题。
"我们首先来看项目背景。
在汽车制造行业,一辆车由上万个零部件组成。在项目初期,采购部门需要向成百上千家供应商询价、比价、谈判,最终确定由谁供货。这个流程传统上依赖Excel和邮件,效率极低且容易出错。
我参与的 '零部件询报价寻源系统' ,就是要将这个耗时数周的线下流程,变成一个高效、透明、在线的数字化系统。它直接支撑了东风日产所有新车型的零部件采购工作。"
要点:
- 从行业常识切入,易于理解
- 一句话点明系统的商业价值
- 提到具体公司名称增加可信度
第二层:项目描述(1分钟 - 展现技术视野)
目标:描述系统的技术架构和核心功能,展现你的技术视野。
"接下来是项目描述。
这是一个典型的分布式微服务架构的ToB系统。技术栈以 Spring Cloud 为核心,使用 Nacos 作为注册中心,MySQL 作为主要存储,Redis 处理缓存,RabbitMQ 用于系统解耦。
系统核心流程包括:零件导入 → 创建询价单 → 供应商报价 → 比价决策 → 确定供应商。它需要与公司内部的 PDT车型管理系统、物流系统 等多个上下游系统对接,是整个供应链的核心枢纽。"
要点:
- 明确技术架构定位(微服务、分布式)
- 列举核心技术和中间件
- 描述核心业务流程
- 说明系统在IT生态中的位置
第三层:个人业务开发(1.5分钟 - 体现你的贡献)
目标:具体说明你负责的模块,展现你的业务理解和技术实现能力。
"在这个系统中,我主要负责两个核心模块的开发。
第一个是’数据导入引擎’。这个模块要解决的核心业务问题是:如何将工程师提供的包含数万行零件数据的Excel表格,快速、准确地转化为系统中的结构化数据。
我的实现方案是分级处理:
- 对于万级以下数据,使用 MyBatis批量操作
- 对于数万级数据,采用 JDBC Batch + 手动事务
- 对于数十万级的全车BOM数据,使用 CompletableFuture并行处理 + 分片策略
第二个是’供应商报价超时自动处理’。业务背景是:给供应商的报价窗口期通常是48小时,超时后需要自动关闭报价通道。
我的技术方案是:利用 RabbitMQ的延时队列和死信队列,在创建询价单时发送一个48小时后过期的消息,消息过期后自动进入死信队列,由消费者执行关闭逻辑。这取代了之前低效的数据库轮询方案。"
要点:
- 明确 ownership("我负责")
- 讲清业务问题,而不只是技术功能
- 技术方案与业务场景一一对应
- 体现技术选型的思考过程
第四层:解决的技术难题(2分钟 - 展现实战深度)
目标:深入技术细节,展现你解决复杂问题的能力。
"在开发过程中,我攻克了几个关键的技术难题。
第一个是’大数据量导入的稳定性’问题。
- 难点:在并行处理数十万行数据时,很容易出现OOM(内存溢出) 和数据库连接池耗尽。
- 我的解决方案:
- 流式读取:使用EasyExcel的流式读取API,不一次性加载整个Excel到内存。
- 分片策略:按零件类别将数据分组,不同组在不同的线程中处理,避免单一事务过大。
- 资源控制:为导入任务配置独立的线程池,设置合理的队列大小,使用
CallerRunsPolicy拒绝策略保证不丢失任务。- 结果:将导入时间从5分钟优化到10秒内,且在大数据量下保持稳定。
第二个是’分布式环境下的缓存一致性’问题。
- 难点:零件基础信息被缓存后,当工程师在源头系统修改了数据,如何让所有服务的缓存及时失效。
- 我的解决方案:
- 设计缓存键规范:如
part:info:{partId},便于管理和批量操作。- 建立更新广播机制:当基础数据变更时,通过RabbitMQ发布
PartInfoUpdatedEvent事件,所有消费此事件的服务都会失效本地缓存。- 降级策略:为缓存设置合理的TTL,作为最终保障。
- 结果:核心数据的缓存一致性达到99.9%以上。"
要点:
- 使用"问题-解决方案-结果"的黄金结构
- 提到具体的技术问题和风险(OOM、连接池耗尽、缓存不一致)
- 解决方案要具体到API和技术细节
- 用数据量化成果
第五层:系统级难点与思考(1分钟 - 展现架构思维)
目标:讨论系统层面尚未完美解决的挑战,展现你的技术前瞻性和深度思考。
"尽管我们解决了很多问题,但系统中仍存在一些架构层面的挑战。
第一个是’跨系统数据一致性的终极保障’。
- 我们虽然通过消息队列实现了最终一致性,但在极端网络分区场景下,仍可能出现微小概率的数据不一致。
- 我们曾考虑引入Seata这类分布式事务框架,但其性能代价在高速业务场景下难以接受。这是性能与一致性的经典权衡。
第二个是’复杂查询的性能与灵活性矛盾’。
- 采购人员需要按零件类型、供应商地区、价格区间等十多个维度任意组合筛选询价单。
- 这种多维度、低基数的查询,无论是数据库索引还是缓存,都难以高效支持。
- 我们目前的方案是通过Elasticsearch建立二级索引,但这又带来了数据同步延迟和维护复杂性的新问题。
第三个是’API的平滑演进与历史包袱’。
- 作为公共服务,我们的API被几十个下游系统调用。即使推出了v2版本,也不敢轻易下线v1,因为无法确认是否还有陈旧的系统在依赖它。
- 这导致系统背负的技术债会随时间线性增长,需要在’推动下游改造’和’维护成本’之间不断权衡。"
要点:
- 展现你能够跳出具体代码,思考系统级问题
- 讨论技术选型的权衡(Trade-offs)
- 体现对技术债务、长期维护成本的认知
- 承认技术没有银弹,展现务实的态度
模板
1. 项目背景(商业价值)
"这是一个支撑东风日产全系车型零部件采购的数字化系统。在汽车行业,一辆车有上万个零部件,传统依赖Excel和邮件的采购方式效率极低且容易出错。我们的系统就是要将耗时数周的线下流程,变成高效透明的在线数字化系统。"
2. 项目描述(技术架构)
"系统采用Spring Cloud微服务架构,技术栈包括SpringBoot、MyBatis、MySQL、Nacos、Redis、RabbitMQ。核心流程涵盖零件导入、询价单创建、供应商报价、比价决策到确定供应商的全链路,需要与PDT车型管理系统、物流系统等多个上下游系统对接。"
3. 个人职责与业务开发
"我主要负责两个核心模块:
第一是数据导入引擎:解决数万行Excel零件数据的快速准确转化问题。我采用分级处理策略:
- 万级以下:MyBatis批量操作
- 数万级:JDBC Batch + 手动事务
- 数十万级:CompletableFuture并行处理 + 分片策略
第二是供应商报价超时处理:通过RabbitMQ延时队列+死信队列实现48小时报价窗口期的自动关闭,取代低效的数据库轮询。"
4. 解决的技术难题
"大数据量导入的稳定性问题:
- 难点:并行处理数十万数据时的OOM和连接池耗尽
- 方案:流式读取 + 分片策略 + 资源隔离 + 合理的拒绝策略
- 结果:导入时间从5分钟优化到10秒内,且保持稳定
分布式缓存一致性问题:
- 难点:零件数据在源头修改后,多服务实例缓存更新不及时
- 方案:设计缓存键规范 + MQ事件广播 + TTL兜底
- 结果:缓存一致性达到99.9%以上"
5. 系统级难点与思考
"跨系统数据一致性的终极保障:虽然通过MQ实现最终一致性,但极端网络分区下仍有微小概率不一致。我们在性能与一致性间持续权衡。
复杂查询的性能与灵活性矛盾:多维度、低基数的组合查询难以优化,目前通过ES二级索引解决,但带来了数据同步延迟的新问题。"
高并发处理能力与优化
1. 高并发场景分析
特点:有明显的峰值现象和批量处理需求
- 高峰时段:新车项目启动时(批量导入数万零件)
- 关键操作:供应商集中报价(截止时间前)
- 数据特点:单次数据量大,计算复杂,时效性要求高
2. 四层性能优化体系
第一层:数据分片与路由
// 1. 分库分表策略(按业务维度)
public class QuotationShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> availableTargetNames,
PreciseShardingValue<Long> shardingValue) {
Long quotationId = shardingValue.getValue();
// 策略1:大客户单独分库(数据隔离)
Long customerId = extractCustomerId(quotationId);
if (isKeyAccount(customerId)) {
return "ds_key_account"; // 大客户专属库
}
// 策略2:按时间分片(2023年、2024年不同库)
LocalDateTime createTime = getCreateTime(quotationId);
int year = createTime.getYear();
if (year == 2024) {
return "ds_" + (year % 2); // 2024年到ds_0
} else if (year == 2023) {
return "ds_" + (year % 2); // 2023年到ds_1
}
// 策略3:按车型项目分片
String projectCode = getProjectCode(quotationId);
int hash = Math.abs(projectCode.hashCode()) % 4;
return "ds_project_" + hash;
}
// 获取大客户分片
private boolean isKeyAccount(Long customerId) {
// 从缓存中获取大客户列表
String cacheKey = "key_accounts";
Set<Long> keyAccounts = (Set<Long>) redisTemplate.opsForValue().get(cacheKey);
return keyAccounts != null && keyAccounts.contains(customerId);
}
}第二层:批量处理优化
// 1. 大数据量导入的分级处理策略
@Service
@Slf4j
public class BulkImportService {
// 监控指标
private final MeterRegistry meterRegistry;
/**
* 三级导入策略
*/
public ImportResult intelligentImport(List<PartData> allData) {
int totalSize = allData.size();
// 根据数据量选择不同策略
if (totalSize <= 10_000) {
meterRegistry.counter("import.strategy", "level", "L1").increment();
return level1Import(allData); // 策略1:单事务批量插入
} else if (totalSize <= 100_000) {
meterRegistry.counter("import.strategy", "level", "L2").increment();
return level2Import(allData); // 策略2:分批事务处理
} else {
meterRegistry.counter("import.strategy", "level", "L3").increment();
return level3Import(allData); // 策略3:并行分片处理
}
}
/**
* 策略3:大规模数据并行导入(10万+)
*/
private ImportResult level3Import(List<PartData> allData) {
long startTime = System.currentTimeMillis();
// 第1步:数据预处理(清洗、去重、分类)
Map<String, List<PartData>> categorizedData = preprocessAndCategorize(allData);
// 第2步:按类别并行处理(不同类别可完全并行)
List<CompletableFuture<CategoryResult>> futures = categorizedData.entrySet()
.stream()
.map(entry -> CompletableFuture.supplyAsync(() ->
processSingleCategory(entry.getKey(), entry.getValue()),
importExecutor))
.collect(Collectors.toList());
// 第3步:收集结果(带超时控制)
try {
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0]))
.get(5, TimeUnit.MINUTES); // 5分钟超时
ImportResult result = aggregateResults(futures);
long duration = System.currentTimeMillis() - startTime;
log.info("大规模导入完成,数据量:{},耗时:{}ms,TPS:{}/s",
allData.size(), duration, allData.size() * 1000L / duration);
// 记录性能指标
meterRegistry.timer("import.duration", "strategy", "L3")
.record(duration, TimeUnit.MILLISECONDS);
return result;
} catch (TimeoutException e) {
// 超时处理:返回部分成功结果
return handleTimeout(futures, allData.size());
}
}
/**
* 单类别处理(包含防OOM机制)
*/
private CategoryResult processSingleCategory(String category, List<PartData> data) {
// 限制单次处理内存使用
MemoryLimitHelper.enforceMemoryLimit(500 * 1024 * 1024); // 500MB限制
List<List<PartData>> batches = Lists.partition(data, 1000);
CategoryResult categoryResult = new CategoryResult();
for (List<PartData> batch : batches) {
try {
// 使用JDBC批量插入,手动控制事务
CategoryResult batchResult = processBatchWithJdbc(category, batch);
categoryResult.merge(batchResult);
// 定期释放资源
if (batchResult.getProcessedCount() % 5000 == 0) {
System.gc(); // 建议GC,防止内存碎片
clearTemporaryResources();
}
} catch (MemoryError e) {
// 内存溢出保护:记录已处理数据,优雅退出
log.error("内存溢出,中止处理类别:{},已处理:{}条",
category, categoryResult.getProcessedCount());
return categoryResult;
}
}
return categoryResult;
}
}第三层:计算与查询分离
// 1. 报价计算的异步化与结果缓存
@Service
public class QuotationCalculationService {
@Autowired
private RedisTemplate<String, CalculationResult> redisTemplate;
/**
* 带缓存的复杂报价计算
*/
public CompletableFuture<CalculationResult> calculateQuotationAsync(QuotationRequest request) {
// 生成缓存键(基于请求参数的哈希)
String cacheKey = buildCacheKey(request);
return CompletableFuture.supplyAsync(() -> {
// 第1步:尝试从缓存获取
CalculationResult cached = redisTemplate.opsForValue().get(cacheKey);
if (cached != null && !cached.isExpired()) {
meterRegistry.counter("calculation.cache.hit").increment();
return cached;
}
// 第2步:缓存未命中,执行计算
CalculationResult result = performComplexCalculation(request);
// 第3步:异步写入缓存(TTL: 1小时)
CompletableFuture.runAsync(() -> {
redisTemplate.opsForValue().set(cacheKey, result, 1, TimeUnit.HOURS);
}, cacheWriteExecutor);
meterRegistry.counter("calculation.cache.miss").increment();
return result;
}, calculationExecutor);
}
/**
* 复杂计算分解为可并行子任务
*/
private CalculationResult performComplexCalculation(QuotationRequest request) {
// 将计算分解为4个可并行部分
CompletableFuture<MaterialCost> materialFuture =
CompletableFuture.supplyAsync(() -> calculateMaterialCost(request), calculationExecutor);
CompletableFuture<LaborCost> laborFuture =
CompletableFuture.supplyAsync(() -> calculateLaborCost(request), calculationExecutor);
CompletableFuture<TransportCost> transportFuture =
CompletableFuture.supplyAsync(() -> calculateTransportCost(request), calculationExecutor);
CompletableFuture<RiskCost> riskFuture =
CompletableFuture.supplyAsync(() -> calculateRiskCost(request), calculationExecutor);
// 并行执行,等待所有结果
return CompletableFuture.allOf(materialFuture, laborFuture, transportFuture, riskFuture)
.thenApply(v -> {
try {
MaterialCost material = materialFuture.get();
LaborCost labor = laborFuture.get();
TransportCost transport = transportFuture.get();
RiskCost risk = riskFuture.get();
// 合并计算结果
return CalculationResult.builder()
.materialCost(material)
.laborCost(labor)
.transportCost(transport)
.riskCost(risk)
.total(calculateTotal(material, labor, transport, risk))
.build();
} catch (Exception e) {
throw new CalculationException("报价计算失败", e);
}
})
.join();
}
}第四层:流量削峰与队列缓冲
// 1. 报价提交的异步队列处理
@Component
public class QuotationSubmissionService {
@Autowired
private RabbitTemplate rabbitTemplate;
/**
* 报价提交 - 同步快速响应,异步处理
*/
public SubmissionResponse submitQuotation(QuotationSubmission submission) {
// 第1步:基础验证(同步,快速失败)
validateSubmission(submission);
// 第2步:生成唯一ID,快速响应
String submissionId = generateSubmissionId();
// 第3步:消息入队,异步处理
QuotationMessage message = convertToMessage(submission, submissionId);
// 使用确认回调确保消息不丢失
rabbitTemplate.setConfirmCallback((correlationData, ack, cause) -> {
if (ack) {
log.info("报价消息已确认,ID: {}", submissionId);
} else {
log.error("报价消息发送失败,ID: {}, 原因: {}", submissionId, cause);
// 记录到重试表
retryService.recordFailedMessage(message);
}
});
rabbitTemplate.convertAndSend("quotation.exchange",
"quotation.submit",
message,
new CorrelationData(submissionId));
// 第4步:立即返回(响应时间<100ms)
return SubmissionResponse.builder()
.submissionId(submissionId)
.status(SubmissionStatus.PROCESSING)
.message("报价已接收,正在处理")
.estimatedCompletionTime(LocalDateTime.now().plusMinutes(5))
.build();
}
/**
* 消息消费者(处理实际业务)
*/
@RabbitListener(queues = "quotation.process.queue",
concurrency = "10-20") // 动态并发消费者
public void processQuotationMessage(QuotationMessage message) {
long startTime = System.currentTimeMillis();
try {
// 第1步:去重检查(幂等性)
if (processedMessageCache.getIfPresent(message.getMessageId()) != null) {
log.warn("重复消息,跳过处理: {}", message.getMessageId());
return;
}
// 第2步:业务处理
QuotationResult result = quotationProcessor.process(message);
// 第3步:更新状态
quotationStatusService.updateStatus(message.getSubmissionId(),
SubmissionStatus.COMPLETED,
result);
// 第4步:记录已处理
processedMessageCache.put(message.getMessageId(), true);
long duration = System.currentTimeMillis() - startTime;
log.info("报价处理完成,ID: {},耗时: {}ms",
message.getSubmissionId(), duration);
} catch (Exception e) {
log.error("报价处理失败,ID: {}", message.getSubmissionId(), e);
// 进入死信队列,人工处理
throw new AmqpRejectAndDontRequeueException(e);
}
}
}监控与调优体系(两个系统通用)
1. 多维度监控
// 1. 应用性能监控
@Component
public class PerformanceMonitor {
@Autowired
private MeterRegistry meterRegistry;
// 关键指标监控
@EventListener
public void monitorRequest(RequestHandledEvent event) {
// 记录响应时间分布
Timer.Sample sample = Timer.start();
try {
// 业务处理
handleRequest(event);
} finally {
sample.stop(Timer.builder("http.request.duration")
.tags("uri", event.getUri(),
"method", event.getMethod(),
"status", event.getStatus())
.register(meterRegistry));
}
// 记录QPS
meterRegistry.counter("http.request.count",
"uri", event.getUri(),
"status", event.getStatus())
.increment();
}
// JVM监控
@Scheduled(fixedDelay = 60000)
public void monitorJVM() {
// 内存使用
MemoryUsage heapUsage = ManagementFactory.getMemoryMXBean().getHeapMemoryUsage();
meterRegistry.gauge("jvm.memory.heap.used", heapUsage.getUsed());
meterRegistry.gauge("jvm.memory.heap.max", heapUsage.getMax());
// GC情况
List<GarbageCollectorMXBean> gcBeans = ManagementFactory.getGarbageCollectorMXBeans();
gcBeans.forEach(gc -> {
meterRegistry.gauge("jvm.gc.count", gc.getCollectionCount());
meterRegistry.gauge("jvm.gc.time", gc.getCollectionTime());
});
}
}2. 容量规划与弹性伸缩
# Kubernetes弹性伸缩配置
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: procurement-service-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: procurement-service
minReplicas: 3
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
- type: Pods
pods:
metric:
name: http_requests_per_second
target:
type: AverageValue
averageValue: 1000 # 当单Pod QPS > 1000时扩容
behavior:
scaleDown:
stabilizationWindowSeconds: 300 # 缩容稳定窗口5分钟
policies:
- type: Percent
value: 10
periodSeconds: 60
scaleUp:
stabilizationWindowSeconds: 60 # 扩容稳定窗口1分钟
policies:
- type: Percent
value: 100
periodSeconds: 30成果对比与总结
1. 性能优化成果
| 指标 | 采购系统(优化后) | 询报价系统(优化后) | 优化前 |
|---|---|---|---|
| 平均响应时间 | <250ms | <200ms | 800-1500ms |
| P99响应时间 | <500ms | <400ms | 3000-5000ms |
| 系统吞吐量 | 2000 TPS | 5000 TPS | 200-500 TPS |
| 数据库负载 | 降低70% | 降低80% | 持续高负载 |
| 缓存命中率 | 98.5% | 96% | 60-70% |
| 批量处理时间 | 分钟级 | 10秒级 | 小时级 |
2. 架构设计思想总结
"在两个系统的性能优化实践中,我总结了以下几点核心思想:
1. 分层缓存的智慧 从本地缓存到分布式缓存的多级架构,不仅是性能优化,更是系统弹性的保障。我们为每级缓存设计了不同的过期策略和降级方案,确保即使缓存层部分失效,系统仍能提供服务。
2. 数据分片的艺术 不是简单的哈希取模,而是按业务特征分片。采购系统按供应商重要性分片,询报价系统按时间+项目分片,让热点数据自然分散,避免单点瓶颈。
3. 异步化的边界把握 不是所有操作都适合异步。我们坚持:用户交互路径同步化,后台处理异步化。报价提交立即返回收据,后台队列处理,这种模式平衡了用户体验和系统吞吐量。
4. 容量设计的预见性 通过监控数据预测容量需求,在业务高峰前主动扩容和预热。询报价系统在新车项目启动前预扩容30%资源,避免了被动应对。
5. 降级不是失败,而是策略 我们设计了阶梯式降级方案:缓存降级 → 简化计算 → 静态数据返回 → 友好提示。这比简单的’系统繁忙’更能保持用户信任。
这些经验让我深刻理解,高并发优化不是单纯的技术堆砌,而是在业务约束、技术成本、用户体验之间找到最佳平衡点的系统工程。"
总结
升华:如何总结你的业务能力
在分别介绍完两个项目后,你需要一个总结来升华,将你的技术贡献与业务能力明确挂钩。
“通过这两个项目,我认为我的业务能力主要体现在三个方面:
- 业务抽象与建模能力:我能够深入理解像‘供应商评估’、‘询报价’这样的复杂业务流程,并将其抽象为可配置、可扩展的系统模型(如打分模板、规则引擎),而不仅仅是实现单一功能。
- 通过技术驱动业务效率:我始终关注我的代码如何为业务创造价值。无论是将导入时间从5分钟优化到10秒,还是通过自动化处理解放人力,我的目标都是通过技术手段解决业务的真实痛点,提升关键指标。
- 端到端的业务流程理解:我从不是只守着自己的一亩三分地。我会去了解我的模块在上游是谁在用,产生的数据下游流向哪里。比如,我知道我优化的询价数据,最终会流向PDT系统和物流系统,这让我在设计接口和数据结构时,能站在全局视角考虑,避免形成新的数据孤岛。
简单来说,我不仅是一个实现需求的开发者,更是一个愿意并且能够用技术为业务赋能的合作者。”
技术成长与价值总结(1分钟)
"通过这两个项目,我完成了从功能开发者到系统思考者的转变:
在技术深度上,我从CRUD深入到JVM调优、分布式事务、系统架构层面,建立了完整的性能优化方法论。
在业务理解上,我学会了将复杂业务抽象为可配置的系统模型,通过技术手段驱动业务效率提升。
在架构思维上,我深刻体会到架构设计本质上是各种约束下的权衡艺术,需要在性能、一致性、可维护性间找到最佳平衡点。
我带来的不仅是代码实现能力,更是用技术解决业务难题、创造实际价值的系统化思维。"
结尾表达意愿(30秒)
"我非常欣赏贵公司在[提及公司的某个技术或业务特点]方面的实践,这与我过去的技术积累和职业规划高度契合。我期待能将在分布式系统和高并发场景下的经验带到贵团队,共同应对更有挑战的业务场景。
我的介绍就到这里,谢谢您的时间。"
面试场景题
典型场景题分类和示例
一、 系统设计与架构场景题 (重中之重)
这类问题旨在考察你如何从零开始或改造一个系统,评估你的技术选型、权衡和宏观思考能力。
- 经典系统设计
- 设计一个秒杀系统:这是最经典的场景。面试官会期待你谈到:
- 流量削峰:如何用消息队列(如RabbitMQ, Kafka)缓冲瞬时巨额流量。
- 缓存预热:如何提前将商品库存等信息加载到Redis等缓存中。
- 库存扣减:如何在分布式环境下保证“超卖”问题(Redis Lua脚本、数据库乐观锁)。
- 限流与熔断:如何在前端(页面静态化)、网关、服务层进行限流(如Sentinel, Hystrix)。
- 无状态服务:如何保证服务可以水平扩展。
- 设计一个短链接系统:
- 短码生成算法(自增ID、哈希、随机数)及其优缺点。
- 存储设计(用什么数据库?如何分库分表?)。
- 高并发读(缓存策略)。
- 过期和清理策略。
- 设计一个微博/微信朋友圈Feed流系统:
- 推模式 vs 拉模式 的权衡,以及混合模式的应用。
- 如何存储海量数据(分库分表策略)。
- 如何保证好友发布新状态后,我能及时看到(推模式下的异步任务、扇出)。
- 设计一个分布式ID生成器:
- UUID、数据库自增、Snowflake算法、Leaf-segment、Leaf-snowflake等方案的原理和选型考量。
- 设计一个秒杀系统:这是最经典的场景。面试官会期待你谈到:
- 现有系统优化与重构
- “我们有一个系统,随着业务发展,数据库CPU经常100%,你有什么排查思路和优化方案?”
- 考察点:SQL优化、索引优化、读写分离、引入缓存、分库分表、归档历史数据。
- “一个RPC接口调用超时,如何从后端的角度进行排查?”
- 考察点:全链路监控、日志分析、数据库慢查询、网络问题、GC问题、下游服务瓶颈。
- “如何将一个庞大的单体应用拆分为微服务?你会考虑哪些因素?”
- 考察点:领域驱动设计(DDD)、服务边界划分(高内聚、低耦合)、数据一致性(Saga、TCC)、分布式事务、API网关。
- “我们有一个系统,随着业务发展,数据库CPU经常100%,你有什么排查思路和优化方案?”
二、 高并发与性能优化场景题
这类问题考察你在压力下保证系统稳定性和高性能的能力。
- 缓存相关
- “如何保证缓存与数据库的双写一致性?”(经典难题)
- 考察点:Cache-Aside模式、延时双删、串行化、最终一致性理解。
- “缓存穿透、缓存击穿、缓存雪崩分别是什么?你的解决方案是什么?”
- 穿透:布隆过滤器、缓存空对象。
- 击穿:互斥锁、永不过期。
- 雪崩:随机过期时间、集群高可用、多级缓存。
- “为什么选择Redis而不是Memcached?Redis的持久化机制(RDB/AOF)如何选择?”
- “如何保证缓存与数据库的双写一致性?”(经典难题)
- 数据库与锁
- “在秒杀场景中,有100个商品库存,10万人来抢,如何保证不超卖?”
- 考察点:乐观锁(
version字段)、悲观锁(select ... for update)、Redis递减(Lua脚本保证原子性)。
- 考察点:乐观锁(
- “什么是死锁?如何在Java中定位和避免死锁?”
- 考察点:
jstack命令分析线程堆栈、避免顺序不一致、使用尝试锁。
- 考察点:
- “你们项目里分库分表是怎么做的?如何选择分片键?遇到跨分片查询/排序怎么办?”
- 考察点:对ShardingSphere、MyCAT等中间件的理解,或自己设计的思路。
- “在秒杀场景中,有100个商品库存,10万人来抢,如何保证不超卖?”
三、 分布式与微服务场景题
考察你对分布式系统复杂性的理解和处理能力。
- 事务与一致性
- “在微服务架构下,如何实现分布式事务?”
- 考察点:本地消息表、最大努力通知、TCC、Saga模式、Seata框架。
- “CAP理论是什么?你的系统如何取舍?BASE理论呢?”
- “在微服务架构下,如何实现分布式事务?”
- 服务治理与稳定性
- “服务注册与发现的原理是什么?(Eureka, Nacos)”
- “如何实现服务的熔断和降级?原理是什么?(Hystrix, Sentinel)”
- “如果服务A调用服务B,B又调用C,C挂了导致整个链路卡住,怎么处理?”
- 考察点:超时设置、熔断器、线程池隔离。
四、 项目经验与线上问题排查场景题 (行为面试)
这类问题通过你过去的实际经历来评估你的能力。
- 项目深度
- “介绍一个你做过的最有挑战的项目/模块。”
- STAR法则:情境、任务、行动、结果。重点讲清楚你个人的贡献和技术决策。
- “在这个项目中,你遇到的最大技术难点是什么?你是怎么解决的?”
- “如果让你重做这个项目,你会在架构上做什么改进?”
- “介绍一个你做过的最有挑战的项目/模块。”
- 线上故障处理
- “讲一次你处理过的线上故障,从发现到解决的全过程。”
- 考察点:监控告警、日志排查、定位问题、紧急回滚/修复、复盘总结。
- “如何排查Java应用的CPU占用率过高或内存泄漏问题?”
- 考察点:
top->jstack查线程、jmap/jstat分析GC、MAT分析堆转储。
- 考察点:
- “讲一次你处理过的线上故障,从发现到解决的全过程。”
五、 技术深度与原理性场景题
5年经验要求你对常用技术的理解不能停留在“会用”,而要深入原理。
- JVM
- “线上Full GC频繁,如何排查和优化?”
- “JVM调优你做过吗?常用的参数有哪些?(如堆大小、垃圾收集器选择)”
- 框架 (Spring)
- “Spring Bean的生命周期是怎样的?”
- “Spring事务的实现原理是什么?什么情况下会失效?”
- 消息队列
- “如何保证消息不被重复消费?(幂等性)”
- “如何保证消息的可靠传输?(生产者确认、消息持久化、消费者确认)”
- “Kafka为什么吞吐量高?(页缓存、顺序IO、零拷贝)”
场景一:设计一个秒杀系统
这是面试的“标配”题,完美考察高并发、高性能、高可用的架构能力。
回答思路: 分层削峰、冗余缓存、极限优化、预案兜底。
详细答法:
“面试官好,设计一个秒杀系统,我会从架构分层的角度,从前到后,逐层进行设计和优化。”
- 前端/接入层优化
- 目的:拦截80%以上的无效流量,尽量让请求不打到后端服务。
- 措施:
- 静态化:将商品详情页、活动页等提前生成静态HTML/CDN缓存,直接返回,不经过后端服务。
- 按钮置灰与计数:前端在活动开始前将按钮置灰,通过JS进行倒计时,防止用户提前重复提交。同时,用户点击后立即置灰,防止连点。
- 验证码:在提交秒杀请求时,弹出图形/滑动验证码,可以有效防止机器人刷单,并起到“削峰”作用。
- 网关层优化
- 目的:全局流控,恶意请求拦截。
- 措施:
- 限流:使用网关(如Spring Cloud Gateway, Nginx)配置严格的限流规则,例如对同一个UID/IP在短时间内进行次数限制。可以使用令牌桶或漏桶算法。
- 防刷:识别并拦截恶意IP、设备指纹等。
- 服务层优化(核心业务逻辑)
- 目的:将同步业务异步化,保证核心流程的可靠与高性能。
- 架构:采用微服务拆分,秒杀活动管理、商品查询、订单服务等各自独立,便于扩容和隔离。
- 措施:
- 缓存预热:在秒杀开始前,将参与秒杀的商品库存(例如100个)提前加载到Redis中。
- 请求入队:用户秒杀请求到达后,不做复杂的库存扣减和订单创建,而是进行基础的校验(如用户资格、活动是否进行中)后,生成一个唯一的请求ID,立即放入消息队列(如Kafka/RocketMQ) 中,并立即给前端返回“排队中”的状态。这一步是核心,将同步的秒杀请求变成了异步处理。
- 令牌(Ticket)机制:放入队列的其实是一个“资格”,后端服务异步地从队列中消费,判断库存,如果成功,则为这个请求生成一个购买令牌(Token),用户凭此令牌在有效期内完成支付即可。
- 数据层优化
- 目的:解决数据库的“写”瓶颈,防止超卖。
- 库存扣减:
- 方案一(首选):在Redis中预扣库存。使用
decr命令或Lua脚本来保证原子性。因为Redis是单线程内存操作,性能极高。扣减成功后,再将订单信息异步落库。 - 方案二(备用):如果必须用数据库,使用乐观锁(
update stock set count = count - 1 where product_id = xx and count > 0),通过count > 0和行级锁来防止超卖。
- 方案一(首选):在Redis中预扣库存。使用
- 订单创建:订单服务消费MQ消息,创建订单。这里数据库依然是瓶颈,可以考虑使用分库分表策略。
- 容灾与降级
- 目的:凡事做最坏的打算。
- 措施:
- 服务熔断与降级:如果订单服务或数据库压力过大,通过Sentinel/Hystrix进行熔断,暂时屏蔽秒杀功能,保护系统不被打垮。
- 预案:准备好开关配置,在系统出现问题时能一键关闭秒杀入口。
- 监控与告警:全链路监控(APM)、大盘、关键指标(QPS、库存消耗速度、DB负载)的告警必不可少。
总结陈述: “总之,一个秒杀系统的核心思想是‘分层过滤,逐级削峰’。前端拦截大部分无效请求,网关进行全局控流,服务层通过‘请求入队’将瞬时高峰 flatten 成平稳的异步流,最后在数据层通过Redis等高性能中间件解决核心的库存并发问题,并辅以完善的监控和降级预案来保证系统的最终稳定。”
场景二:如何保证缓存与数据库的双写一致性?
这是一个技术深度题,考察你对分布式数据一致性的理解。
回答思路: 没有银弹,根据不同业务场景(对一致性要求的强弱)选择最合适的方案。
详细答法:
“面试官好,缓存双写一致性问题没有一个完美的通用方案,需要根据业务场景进行权衡。主要有以下几种思路:”
- Cache-Aside Pattern(旁路缓存模式) - 最常用
- 读:先读缓存,命中则返回;未命中则读数据库,然后写入缓存。
- 写:先更新数据库,再删除缓存。
- 为什么是删除缓存,而不是更新缓存?
- 如果更新缓存,在并发写时,可能出现更新顺序问题,导致缓存中是旧数据。
- 删除缓存是一种懒惰加载的方式,下次读请求自然会从数据库加载最新数据。
- 存在的问题:
- 场景一:读请求A未命中缓存,读数据库(旧数据)。此时写请求B更新了数据库并删除了缓存。然后A把读到的旧数据写入了缓存。导致缓存一直是旧数据。
- 概率:这个场景需要满足(1)读缓存miss (2)一个写请求在读请求读库和写缓存之间完成。因为写操作通常比读操作慢,所以概率较低。
- 场景二:先删缓存,再更新数据库。在并发下,很容易导致另一个读请求在删缓存后、更新数据库前,把旧数据读出来并塞回缓存。这个概率很高,不推荐。
- 场景一:读请求A未命中缓存,读数据库(旧数据)。此时写请求B更新了数据库并删除了缓存。然后A把读到的旧数据写入了缓存。导致缓存一直是旧数据。
- 采用延时双删策略 - 优化方案
- 步骤:
- 先删除缓存。
- 再更新数据库。
- (关键)休眠一个短暂的时间(如几百毫秒,根据业务决定)。
- 再次删除缓存。
- 目的:第二次删除是为了清理在“更新数据库”这个时间窗口内,可能被其他读请求写入的旧数据。
- 缺点:引入了延时,降低了吞吐量。
- 步骤:
- 强一致性方案 - 复杂度高,特定场景使用
- 思路:通过订阅数据库的Binlog(使用Canal/Debezium等中间件)来异步更新/删除缓存。
- 流程:业务代码只更新数据库。一个独立的中间件订阅Binlog,当解析到数据变更时,再去操作Redis。
- 优点:业务代码简洁,将缓存与数据库的同步解耦。
- 缺点:有短暂延迟,架构更复杂。为了保证顺序,可能需要单线程消费。
总结陈述: “所以,在实际项目中,我们最常用的是 ‘先更新数据库,再删除缓存’ 的Cache-Aside模式,因为它简单有效,不一致的概率较低。如果对一致性要求极高,我们会结合‘延时双删’来进一步降低风险。而在一些允许秒级延迟、但追求架构解耦的场景,我们会考虑通过订阅Binlog的方案。没有最好的方案,只有最适合业务场景的方案。”
场景三:讲一次你处理过的线上故障
这是行为面试题,考察你的实际经验、排查问题的逻辑性和复盘能力。
回答思路: 使用STAR法则,并突出你的排查方法论。
详细答法:
“面试官好,我分享一次我们系统遇到的CPU 100%的线上故障。”
- S(情境): “当时是在一个工作日午后,监控平台突然告警,显示我们核心交易服务的几台服务器CPU使用率飙升到100%,导致大量API响应超时,影响了部分用户下单。”
- T(任务): “我的任务是立即定位问题根因,并尽快恢复服务,将影响降到最低。”
- A(行动): (这是重点,要体现你的排查链条)
- 确认现象与止损:我首先登录服务器,用
top命令确认了是某个Java进程占用了几乎全部CPU。同时,我立刻联系运维同学,先对其中一台机器做流量切出(摘流),保留现场用于排查,让其他机器继续提供服务,避免全盘崩溃。 - 定位问题线程:对摘流的机器,我用
top -Hp [pid]看到有一个线程的CPU占用异常高。 - 分析线程栈:我将这个高CPU线程的ID转换为16进制,然后用
jstack [pid] | grep -A 20 [nid]命令打印出这个线程的堆栈信息。发现这个线程正处于 ‘RUNNABLE’ 状态,并且堆栈信息显示它正在频繁地执行一个日志打印操作。 - 深入代码:我立刻去检查了这段日志相关的代码,发现是一个循环体里,在
DEBUG级别下,使用了logger.debug("Processing data: " + largeObject.toString())这种方式来拼接字符串。而largeObject是一个非常大的JSON对象。 - 根因分析:
- 即使在
INFO级别,由于字符串拼接发生在传入debug方法之前,所以无论级别如何,这个耗时的字符串拼接操作都会执行。 - 当时正好有同事为了排查另一个问题,在线上临时将日志级别改为了
DEBUG,触发了这个“性能炸弹”。 - 大量的字符串创建和拼接,导致了疯狂的GC和CPU占用。
- 即使在
- 确认现象与止损:我首先登录服务器,用
- R(结果): “找到原因后,我们立刻将日志级别改回
INFO,服务器CPU在十几秒内恢复正常。随后,我们修复了代码,将其改为使用logger.debug("Processing data: {}", largeObject)这种占位符的方式,确保在日志级别不匹配时不会有无谓的消耗。最后,我们在团队内进行了复盘,并制定了代码规范,禁止在日志中直接进行字符串拼接,同时加强了上线前对日志代码的审查。”
这个回答展现了: 应急能力(先止损)、排查方法(从现象到线程到代码)、技术深度(理解JVM、日志框架原理)、闭环能力(修复和预防)。
场景四:在微服务架构下,如何实现分布式事务?
考察你对分布式系统理论和技术落地的掌握。
回答思路: 从理论(CAP/BASE)到实践(具体方案),并说明选型考量。
详细答法:
“面试官好,在微服务架构下,我们放弃了传统的强一致性分布式事务(如XA/2PC),因为它性能差、同步阻塞,不符合微服务高可用的要求。我们转向追求最终一致性,基于BASE理论。常见的方案有几种:”
- 可靠消息最终一致性(异步确保型)
- 场景:适用于跨服务的异步任务,如订单成功后发短信、扣减库存。
- 方案一(本地消息表):
- 在业务数据库中,与业务数据同库同表,有一张“本地消息表”。
- 业务执行时,在一个本地数据库事务中,既要完成业务操作,也要向消息表插入一条记录。
- 有一个定时任务,扫描消息表,将消息发送到MQ。
- 下游服务消费MQ,处理业务。处理成功后,通知上游或上游主动回调来更新消息状态。
- 方案二(使用RocketMQ事务消息):
- 生产者发送一个“半消息”到MQ。
- MQ持久化成功并回复生产者。
- 生产者执行本地事务。
- 根据本地事务执行结果,向MQ提交
Commit或Rollback。 - MK如果收到Commit,则下游服务可见并消费;如果超时未收到,则回查生产者的本地事务状态。
- 核心:通过MQ的可靠性,保证只要上游事务成功,消息最终一定能被下游消费。
- TCC模式
- 场景:适用于对一致性要求高、且业务逻辑可以明确分为两阶段的场景,如资金扣款、酒店预订。
- 流程:
- Try:尝试执行。完成所有业务的检查,并预留必需资源(如冻结部分金额、锁定酒店库存)。
- Confirm:确认执行。真正执行业务,使用Try阶段预留的资源。要求幂等。
- Cancel:取消执行。释放Try阶段预留的资源。要求幂等。
- 优点:性能较好,数据最终一致。
- 缺点:业务侵入性强,需要为每个操作实现三个接口,开发复杂。
- Saga模式
- 场景:适用于业务流程长、需要调用多个服务的场景。
- 流程:将一个分布式事务拆分为多个本地事务,每个本地事务都有对应的补偿操作。
- 执行方式:
- 正向:T1 -> T2 -> T3 …
- 补偿:如果T3失败,则执行 C3 -> C2 -> C1 …(反向补偿)。
- 优点:一阶段就提交本地事务,无锁,高性能。
- 缺点:不保证隔离性,可能出现“脏写”,需要业务上能处理或通过其他手段避免。
总结陈述: “在我们的项目中,绝大部分场景使用的是‘可靠消息最终一致性’,因为它对业务侵入较小,通过MQ和补偿机制能很好地满足需求。对于少数核心的资金类业务,我们会采用TCC模式。同时,我们也会使用Seata这样的分布式事务框架来降低这些模式的实现复杂度。选型的核心在于权衡业务对一致性的要求与系统的复杂度和性能。”
面经一:博奥特 - 华安保险
Q:Redis 缓存与 Java 本地缓存的区别
核心定义
- Java 本地缓存:指在 Java 应用程序的 JVM 堆内存(或堆外内存)中开辟一块空间,用于存储数据。它的生命周期与应用程序保持一致,访问速度极快,但无法被其他应用共享。常见的实现有:
ConcurrentHashMap、Guava Cache、Caffeine、Ehcache等。 - Redis 缓存:一个独立的、基于内存的键值数据库,通常以独立的服务器进程形式存在,通过网络协议(如 RESP)与应用程序进行通信。它支持数据持久化、主从复制、集群分片等高级功能,是一个集中式的缓存解决方案。
详细对比分析
| 特性维度 | Java 本地缓存 | Redis 缓存 |
|---|---|---|
| 架构与位置 | 进程内缓存,与应用同属一个 JVM 进程。 | 进程外缓存,独立的服务,通过网络访问。 |
| 性能 | 极高。直接读写 JVM 内存,无网络开销和序列化/反序列化开销。 | 高。基于内存,但存在网络 I/O 和序列化/反序列化的开销。 |
| 数据一致性 | 难保证。在集群环境下,每个应用实例的本地缓存是独立的,更新一个实例的缓存无法通知其他实例,导致数据不一致。 | 易保证。作为集中式存储,所有应用实例都访问同一个数据源,数据是一致的。 |
| 分布式支持 | 不支持 或 需要额外手段。本身是单机的。要实现分布式效果,需要引入广播机制(如 Redis Pub/Sub)或一致性哈希等复杂方案。 | 原生支持。通过 Redis Cluster 或客户端分片,可以轻松实现水平扩展。 |
| 容量与扩展性 | 受 JVM 堆内存限制。容量有限,过大的缓存会影响 GC,可能引发 Full GC 甚至 OOM。扩展性差,只能垂直扩展(加大 JVM 堆)。 | 容量独立,扩展性强。数据存储在独立的 Redis 服务器上,容量不受应用限制。可以水平扩展(增加 Redis 集群节点)。 |
| 数据结构和功能 | 简单。通常是简单的 Key-Value 映射。高级功能(如过期、淘汰策略)需要自行实现或依赖第三方库(如 Caffeine)。 | 极其丰富。支持字符串、列表、集合、有序集合、哈希、位图、流等多种数据结构。提供发布订阅、Lua 脚本、事务等强大功能。 |
| 数据持久化 | 通常不持久化。应用重启后缓存数据丢失。 | 支持持久化。可通过 RDB 快照和 AOF 日志将内存数据持久化到磁盘,保证数据不丢失。 |
| 可靠性/高可用 | 低。缓存数据与应用共存亡,应用宕机则缓存丢失。 | 高。通过 Redis Sentinel 或 Redis Cluster 提供主从复制和故障自动转移,实现高可用。 |
| 使用复杂度 | 低。引入 jar 包即可使用,无需部署和维护额外中间件。 | 中。需要单独部署、维护和监控 Redis 服务器,增加了运维成本。 |
| 适用场景 | - 数据量不大、更新频率低 - 对性能要求极致,可接受短暂不一致 - 单机应用或无需在集群间同步缓存的场景 - 作为 Redis 缓存前的第一道屏障(多级缓存) | - 大规模分布式系统,需要缓存共享 - 数据一致性要求高 - 缓存数据量巨大 - 需要利用丰富的数据结构或功能(如排行榜、消息队列) - 需要高可用和数据持久化 |
场景举例与选择策略
1. 适合使用 Java 本地缓存的场景
- 配置信息缓存:例如,系统启动时加载的、很少变化的配置项、字典数据。每个应用实例在本地缓存一份,访问速度最快。
- 短时间高频访问的只读数据:比如,一分钟内不会变动的商品基本信息。即使各实例间有一分钟的差异,业务上也可接受。
- 多级缓存架构的第一级:在请求到达 Redis 之前,先用本地缓存拦截一次,极大减轻 Redis 的压力和网络延迟。这是非常经典的架构模式。
2. 适合使用 Redis 缓存的场景
- Session 共享:在集群部署中,用户的 Session 信息存储在 Redis 中,任何一台应用服务器都能访问,实现登录状态的保持。
- 分布式锁:利用 Redis 的原子操作实现跨 JVM 的互斥锁。
- 排行榜/计数器:利用 Redis 的
ZSET(有序集合)可以轻松实现实时排行榜;利用INCR命令实现高性能的计数器。 - 缓存热点数据:如商品详情页、文章详情等,所有应用实例都从同一个 Redis 获取,保证数据一致。
最佳实践与结合使用:多级缓存
在现代高并发系统中,通常不会二选一,而是将它们结合使用,形成多级缓存,以兼顾性能和一致性。
经典的多级缓存架构(如 CPU 缓存架构):
- L1 缓存:Java 本地缓存 (Caffeine)
- 作用:抵御最热点的数据访问,响应速度在纳秒级。
- 策略:设置较短的过期时间(如 1-2 分钟),容忍极短时间的数据不一致。
- L2 缓存:Redis 分布式缓存
- 作用:作为共享缓存层,抵御大量的数据访问,保证集群数据一致性。
- 策略:设置较长的过期时间,并从数据库加载数据。
- 数据源:数据库 (MySQL等)
- 最终的数据持久化层。
工作流程:
- 请求到达应用。
- 首先查询 L1 本地缓存,如果命中则直接返回。
- 如果 L1 未命中,则查询 L2 Redis 缓存。
- 如果 Redis 命中,则将数据写入本地缓存(并设置短过期时间),然后返回。
- 如果 Redis 也未命中,则查询数据库,将结果写入 Redis 和本地缓存,然后返回。
缓存更新/失效策略: 为了保证数据最终一致性,当数据发生变更时:
- 更新数据库。
- 删除 Redis 中对应的缓存(Cache-Aside 模式)。
- 发布一个消息(通过 Redis Pub/Sub 或 MQ),通知所有应用实例删除其本地缓存中的该数据。
总结
| 缓存类型 | 优势 | 劣势 |
|---|---|---|
| Java 本地缓存 | 性能极致、零网络开销、实现简单 | 容量有限、数据不一致、可靠性低 |
| Redis 缓存 | 功能丰富、数据一致、容量大、高可用 | 存在网络延迟、需要额外运维 |
最终选择建议:
- 追求极致性能、可接受数据短时不一致 -> 优先考虑 Java 本地缓存。
- 需要数据共享、保证一致性、缓存大量数据 -> 必须使用 Redis 缓存。
- 构建高性能、高可用的超大规模系统 -> 采用 多级缓存架构,让两者协同工作,取长补短。
Q:Redis 为什么这么快?
1. 基于内存的存储与访问
这是最根本、也是最容易理解的原因。
- 直接内存操作:Redis 将所有数据存储在内存(RAM)中。这意味着数据的读写操作完全不需要磁盘 I/O,而磁盘 I/O(尤其是机械硬盘)通常是传统数据库(如 MySQL)最主要的性能瓶颈。
- 速度数量级差异:内存的读写速度比 SSD 快 10-100 倍,比机械硬盘快 10万 倍以上。这种硬件级别的速度优势是 Redis 高性能的基石。
类比:从内存中读取数据就像从办公桌的桌面上直接拿一份文件,而从磁盘读取数据则像是需要走到档案室去翻找。前者几乎是瞬时的。
2. 高效的数据结构
Redis 不仅仅是简单的 Key-Value 存储,它提供了丰富的数据结构,并且每种结构都针对特定场景进行了极致的优化。
- 动态字符串(SDS):与 C 语言原生字符串相比,SDS 获取字符串长度的时间复杂度是 O(1)(原生是 O(n)),并且避免了缓冲区溢出,同时减少了内存重分配次数。
- 字典(Hash Table):Redis 的整个 Key 空间就是一个巨大的字典,其实现使用了高效的哈希表,并采用了一种称为 “渐进式 Rehash” 的策略。在扩容时,它不会一次性将所有数据迁移到新哈希表,而是分多次、渐进式地完成,避免了单次操作导致的长时间停顿,保证了高性能。
- 跳跃表(Skip List):用于实现有序集合(Sorted Set)。它在链表的基础上增加了多级索引,使得查找效率可以达到平均 O(log n),且实现比平衡树更简单,非常适合范围查询。
- 压缩列表(ziplist) 和 快速列表(quicklist):
ziplist是为小数据量列表、哈希、有序集合设计的一种紧凑的、连续内存存储结构,它通过牺牲部分读写速度来极大地节省内存,从而减少内存分配和碎片。quicklist是列表(List)的默认实现,它是双向链表和 ziplist 的结合。它将多个 ziplist 节点用双向链表连接起来,在空间效率和操作效率之间取得了完美的平衡。
- 紧凑存储:对于整数集合等,Redis 会使用最紧凑的编码方式来存储,以节省内存。
这些精心设计的数据结构,使得 Redis 在时间和空间效率上都达到了很高的水平。
3. 单线程模型与 I/O 多路复用
这是 Redis 设计中最精妙也最容易被误解的一点。
核心是单线程
Redis 的核心网络事件处理器(命令执行器)是单线程的。这意味着在任何给定时刻,只有一个命令在被处理。
为什么单线程反而快?
- 避免了线程切换和竞态的开销:多线程编程需要复杂的锁机制来保证数据一致性,锁的竞争和线程上下文的切换会消耗大量的 CPU 资源。单线程模型完全避免了这些开销。
- 不存在加锁/解锁操作:所有操作都是原子的,不会因为并发问题导致数据混乱,简化了实现。
- 顺序执行,无需同步:命令按照到达顺序被逐一执行,逻辑清晰,性能可预测。
I/O 多路复用:单线程的“神助攻”
单线程如何处理海量的并发连接呢?答案是 I/O 多路复用技术。
- 原理:Redis 使用
epoll(Linux)、kqueue(BSD/Mac) 或select等系统调用,在一个线程中同时监控成千上万个网络连接(Socket)。当任何一个 Socket 有数据到达(即有客户端请求)时,多路复用器会通知 Redis,然后 Redis 依次处理这些就绪的 Socket 上的命令。 - 工作流程:
- 多个客户端与 Redis 建立连接。
- Redis 的单线程通过 I/O 多路复用器监听所有 Socket。
- 当某个 Socket 可读(有请求)时,多路复用器将其放入一个队列。
- Redis 的事件处理器按顺序从队列中取出请求,逐个执行命令。
- 执行完毕后,将结果写入对应的 Socket 输出缓冲区。
类比:单线程的 Redis 就像一个高效的餐厅服务员。I/O 多路复用就像他有一个“万能对讲机”,可以同时监听所有餐桌(客户端)的点餐需求。他不需要在每张桌子前傻等,而是当有顾客(Socket)准备好点餐(请求可读)时,对讲机会通知他,他再走过去处理。这样,一个服务员就能高效地服务整个餐厅。
结论:单线程模型 + I/O 多路复用,使得 Redis 在极高的并发连接下,依然能保持极低的延迟和极高的吞吐量,尤其是在操作都是内存级别的轻量级操作时。
4. 其他优化手段
除了上述三大核心原因,Redis 还有一些其他的优化策略:
- 虚拟内存机制:虽然数据在内存中,但 Redis 仍会利用操作系统的虚拟内存和交换分区,不过现代 Redis 版本更倾向于使用持久化机制来保证数据安全。
- 管道化(Pipeline):客户端可以将多个命令一次性发送给 Redis,而无需等待每个命令的响应。这极大地减少了网络往返时间(RTT),在需要执行大量命令时效果显著。
- 精细的底层优化:Redis 的代码非常简洁高效,由 C 语言编写,对常见操作进行了大量优化。
总结与权衡
| 特性 | 带来的速度优势 | 潜在的代价/限制 |
|---|---|---|
| 内存存储 | 极快的读写速度 | 数据容量受内存大小限制,成本较高,数据易失(需配合持久化) |
| 高效数据结构 | 节省内存,操作快速 | 数据结构复杂度较高,需要根据场景选择合适的数据类型 |
| 单线程模型 | 无锁,无上下文切换,原子操作 | 无法利用多核CPU;单个耗时命令(如keys *)会阻塞所有后续命令 |
| I/O 多路复用 | 高并发连接下的高性能 | 对CPU密集型任务不友好 |
关于多线程的补充: 从 Redis 4.0 开始,为了弥补单线程在特定任务上的短板,Redis 引入了多线程,但主要用于后台任务,如:
- 大 Key 的异步删除(
UNLINK命令)。 - 持久化时 AOF 文件的刷盘操作。
在 Redis 6.0 及之后,进一步引入了多线程 I/O,用于处理网络数据的读取和解析(read/parse),但命令的执行(exec)仍然是单线程的。这进一步提升了在网络 I/O 成为瓶颈时的性能,而其核心的、无锁的命令执行模型依然得以保留。
最终结论: Redis 的极速是 内存速度 + 精妙数据结构 + 单线程无锁架构 + I/O 多路复用 这一组合拳的结果。它通过牺牲数据规模(受限于内存)和通用性(不适合复杂事务和CPU密集型任务),换取了在特定场景下无与伦比的性能。
Q:Redis 中 RDB 和 AOF 的区别
核心概念速览
- RDB:在指定的时间间隔内,生成内存中整个数据集的一个时间点快照。它就像是给数据库拍一张完整的照片。
- AOF:记录服务器接收到的每一个写操作命令,并在服务器启动时通过重新执行这些命令来重建原始数据集。它就像是记录数据库所有操作的日记。
下面我们从多个维度进行详细对比。
详细对比表格
| 特性维度 | RDB | AOF |
|---|---|---|
| 持久化原理 | 定时生成内存数据的二进制快照文件。 | 记录每一次写操作命令(文本协议格式),通过重放命令恢复。 |
| 文件格式 | 紧凑的、二进制的 dump.rdb 文件。 | 文本文件,默认名为 appendonly.aof,内容是可读的 Redis 命令。 |
| 数据安全性 | 较低。可能丢失最后一次快照之后的所有数据。 | 非常高。根据 appendfsync 策略配置,最多丢失一秒数据,甚至完全不丢。 |
| 性能影响 | 写时复制 机制,fork() 子进程时可能阻塞主线程,内存占用翻倍。恢复大数据集时速度快。 | 主要在于文件同步开销。appendfsync always 性能差,everysec 性能很好,no 性能最好但可能丢失更多数据。恢复大数据集时速度慢。 |
| 文件大小 | 小。二进制压缩格式,是某个时间点的数据全集。 | 大。记录所有操作日志,长期运行会非常大。但支持重写以压缩文件。 |
| 数据恢复速度 | 快。直接将 RDB 文件读入内存即可。 | 慢。需要逐条执行 AOF 文件中的所有命令,过程漫长。 |
| 容灾性 | 较差。损坏的 RDB 文件可能导致数据无法恢复。 | 较好。即使文件尾部有损坏,redis-check-aof 工具可以修复(截掉损坏部分)。 |
| 使用场景 | 适合大规模数据恢复、冷备份、对数据丢失不敏感(如数据统计、缓存)的场景。 | 适合对数据安全要求极高的场景,如业务核心数据、金融交易数据。 |
| 配置复杂度 | 简单,主要设置保存快照的时间策略。 | 相对复杂,需要配置 appendfsync 策略、AOF 重写策略等。 |
深入原理与细节分析
1. RDB 的工作机制与优缺点
工作原理:
- 手动触发:执行
SAVE(阻塞)或BGSAVE(后台异步)命令。 - 自动触发:在配置文件中设置
save m n规则,例如save 900 1表示在 900 秒内至少有 1 个 key 发生变化,则触发BGSAVE。 BGSAVE过程:Redis 主进程fork()一个子进程。子进程拥有主进程此刻的内存数据副本。子进程负责将数据写入临时 RDB 文件,写入完成后替换旧的 RDB 文件。父进程继续处理客户端请求。
优点:
- 性能最大化:
fork子进程进行持久化,主进程不会进行磁盘 I/O 操作,保证了 Redis 的高性能。 - 灾难恢复友好:紧凑的二进制文件非常适合用于灾难恢复,可以快速地将一个 RDB 文件转移到远程数据中心或对象存储中。
- 快速重启:相比 AOF,在数据集很大时,RDB 的恢复速度要快得多。
缺点:
- 数据丢失风险:由于是定时快照,一旦在两次快照之间数据库发生故障,会丢失这段时间内的所有数据。
fork()可能阻塞:当数据集非常大时(例如几十GB),fork()操作本身可能会非常耗时,导致主进程短暂停止服务(毫秒级甚至秒级)。
2. AOF 的工作机制与优缺点
工作原理:
- 命令追加:每一个写命令都会被追加到 AOF 缓冲区的末尾。
- 文件同步:根据
appendfsync配置,将缓冲区内容写入并同步到 AOF 磁盘文件。always:每个事件循环都将 AOF 缓冲区的内容写入并同步到 AOF 文件。最安全,性能最差。everysec:每个事件循环将 AOF 缓冲区内容写入到 AOF 文件,并且每秒同步一次。在安全性和性能之间取得了很好的平衡,是默认推荐的策略。no:每个事件循环将 AOF 缓冲区内容写入到 AOF 文件,但同步操作由操作系统决定。性能最好,但可能丢失一个事件循环的数据。
- 文件重写:随着命令不断写入,AOF 文件会越来越大。Redis 提供了
BGREWRITEAOF机制,fork子进程根据当前数据库状态创建一个新的、更小的 AOF 文件,来替换旧文件。例如,对一个 key 进行了 100 次incr,重写后只需记录一条set key 100命令。
优点:
- 极高的数据安全性:即使使用默认的
everysec策略,也最多只丢失 1 秒钟的数据。 - 可读性:AOF 文件是纯文本格式,易于理解和分析。如果误操作(如
FLUSHALL),可以在文件末尾删除该命令后进行恢复。
缺点:
- 文件体积大:即使经过重写,AOF 文件通常也比同数据集的 RDB 文件大。
- 恢复速度慢:数据恢复时需要重新执行所有命令,比 RDB 慢很多。
- 性能依赖同步策略:在写入吞吐量高的场景下,AOF 的性能可能仍低于 RDB。
如何选择:RDB vs AOF?
这是一个经典的权衡问题,取决于你的业务需求。
- 追求极致的数据安全,愿意牺牲一些性能和存储空间?
- 选择 AOF。这是最常见的选择。
- 可以容忍分钟级别的数据丢失,追求更快的启动速度和更小的备份文件?
- 选择 RDB。适用于用作缓存或存储非关键数据的场景。
- “我全都要”!希望兼顾数据安全、性能和快速恢复?
- 选择 “RDB + AOF” 的混合模式(Redis 4.0+ 推荐)。
混合持久化(推荐)
在 Redis 4.0 之后,引入了一个新的选项:aof-use-rdb-preamble。
工作原理: 当开启混合持久化后,在 AOF 重写时,子进程不再是单纯地将当前数据集转换为 AOF 命令,而是会先将当前数据集以 RDB 二进制格式写入到新的 AOF 文件的前半部分。然后,在重写期间接收到的写命令,会以 AOF 格式继续追加到文件的后半部分。
这样一来,新的 AOF 文件就由一个 RDB 数据快照头 和一个 AOF 命令增量尾 组成。
优势:
- 快速恢复:重启时,先加载 RDB 部分,速度极快,然后再重放少量的增量 AOF 命令,大大提升了恢复速度。
- 数据安全:结合了 RDB 的文件小、恢复快和 AOF 的数据不丢失的优点。
配置方法: 在 redis.conf 中设置:
appendonly yes
aof-use-rdb-preamble yes总结与比喻
- RDB 像拍照片:定期定格,记录瞬间。恢复快、文件小,但可能错过镜头间的精彩(数据变化)。
- AOF 像写日记:事无巨细,逐条记录。数据全、最可靠,但日记本厚(文件大),复盘(恢复)起来慢。
- 混合模式像“照片+日记补录”:先拍一张完整的照片,然后在照片后面记录之后发生的新事情。结合了两者的优点,是现代 Redis 部署的推荐方案。
在实际生产环境中,强烈建议根据业务容忍度进行测试,并优先考虑开启 AOF 或 混合持久化 来保证数据的安全性。
Q:注重项目的难点
- 对项目二中系统对接上游系统与下游系统的数据传输方式,以及供应商是否存在外部系统导入数据进内部系统。
- 对于零部件询报价寻源系统,其数据来源通常是多通道、分阶段的,而不是单一来源。下图清晰地展示了该系统核心的数据来源与流向:
下面我们来分步解析这套数据流机制:
核心数据来源分析
- 来自东风日产内部系统(主要来源)
这是系统最核心、最正式的数据来源,保证了数据的权威性和一致性。
- 数据内容:需要询价的零部件清单(BOM)、车型信息、技术图纸、需求数量、时间节点等。
- 来源系统:
- PDT车型综合管理系统(项目描述中已提及):这是最直接的源头,新车型项目启动时,会生成完整的零部件清单,并自动或手动触发询价流程。
- ERP主数据系统:获取已有的物料基础信息、历史价格等。
- 设计/工艺系统:获取最新的技术规范和图纸。
- 交互方式:通常通过系统接口对接实现。PDT系统会通过API调用或消息队列,将询价任务同步到寻源系统。
- 来自内部用户(采购/工程师)的Excel导入
这是对系统对接方式的重要补充,用于处理非标、紧急或系统无法覆盖的场景。
- 数据内容:
- 新供应商引入时的初步物料清单。
- 临时、小批量的零星采购需求。
- 对已有数据的批量更新。
- 交互方式:这正是你职责中 “使用 CompletableFuture 并行导入零件数据” 和 “优化Excel导入” 所解决的问题。供应商不直接操作该系统,而是将Excel文件发给东风日产的采购人员,由内部员工统一导入,以保证数据的规范和安全。
- 来自供应商的数据(核心是报价,而非零件数据)
这里是关键的区分点:供应商提供的是“报价”数据,而非“零件”主数据。
- 供应商不直接导入零件数据:零件的基础信息(如零件号、名称、技术规格、图纸)是由东风日产定义和拥有的,供应商无权创建或修改。
- 供应商的核心操作:
- 在线报价:在系统中针对发布的询价单,填写单价、付款条件、交货周期等。
- 上传辅助文件:可能会上传报价明细、资质文件、技术建议等作为附件。
- 潜在的特殊情况:
- “供应商白名单”申请:新供应商可能会提交申请和资料,但这属于基础数据管理模块,而非询价流程本身。
- 替代方案建议:供应商可能在报价时,建议一个功能相似的替代零件,但这需要经过严格的审批流程才会被纳入系统。
面试专业回答话术
你可以这样清晰地向面试官阐述:
“在这个系统中,数据来源是双向的,但角色和数据类型是严格区分的。
首先,询价的‘零部件主数据’是由我们东风日产内部产生和定义的。 主要来自两个通道:
- 系统对接:例如从 PDT车型管理系统 通过接口自动同步过来,这是最主流、最规范的方式。
- 内部导入:由我们的采购或工程师,通过我优化过的 Excel导入功能,将整理好的零件清单批量录入系统。
然后,供应商在这个流程中,扮演的是‘报价响应方’的角色。 他们登录系统后,看到的是我们发布的、已定义好的零部件询价单,他们的核心操作是填写报价信息,而不是导入零件数据本身。这样保证了数据源的权威性和业务流程的规范性。”
为什么要这样设计?(展现你的架构思维)
- 数据主权与安全性:零部件基础数据是企业的核心资产,必须掌握在自己手中,防止供应商篡改或看到敏感信息。
- 流程标准化:统一的零件数据是进行**“苹果对苹果”比价**的前提。如果每个供应商都按自己的理解报不同的零件,比价就无法进行。
- 系统解耦:将数据定义(内部)与数据响应(供应商)分离,使得系统架构更清晰,易于维护和扩展。
这样回答,表明你不仅知道技术实现,更能从业务、流程和架构的角度理解一个系统的设计精髓。
Q:引入 MQ 对系统的增强
没有引入 MQ 之前的系统交互方式
在没有引入消息队列(MQ)之前,系统间的交互主要是同步调用和定时任务轮询的结合。
核心交互模式:
同步 HTTP/RPC 调用 (占主导)
场景:当上游系统(如PDT车型管理系统)有新的零部件数据需要发起询价流程时,会直接、同步地调用我们寻源系统的API接口。
代码逻辑 大致如下:
java// 在上游系统中 ResponseEntity<String> response = restTemplate.postForEntity( "http://xunyuan-system/api/startInquiry", inquiryRequest, String.class ); // 必须等待寻源系统的响应 if (response.getStatusCode().is2xxSuccessful()) { // 继续执行后续逻辑 } else { // 处理失败,可能要进行重试或记录错误 }
数据库轮询 (作为补充)
- 场景:对于一些非实时性的数据集成,比如老数据迁移(FDI集成),可能会采用一个定时任务,定期去扫描上游系统的数据库表或某个文件目录,发现有新数据后再进行拉取和处理。
这种方式带来的核心痛点:
- 系统紧耦合:上游系统的可用性直接影响了我们系统的可用性。如果我们系统因部署、故障或性能问题宕机,上游系统的调用会立即失败,导致业务流程中断。
- 性能瓶颈与延迟:上游系统必须等待我们系统的全部处理完成(如数据校验、入库、初始化流程等)后才能得到响应。如果我们的处理较慢,会直接拖慢上游系统的响应时间。
- 缺乏弹性与削峰能力:如果上游系统在某一时刻产生大量询价请求(例如新车发布),我们的系统必须能实时处理这些洪峰流量,否则可能导致服务雪崩。我们没有“缓冲地带”。
- 流程驱动困难:对于“供应商报价超时自动关闭”这类需要延迟触发的业务场景,实现起来非常笨重。通常只能通过一个定时任务,频繁地扫描数据库表,检查每个询价单的创建时间来判断是否超时。这对数据库压力大,且不精确。
引入RabbitMQ之后如何体现其强大作用
引入MQ后,系统架构从紧耦合的同步模型转变为松耦合的异步事件驱动模型,其强大作用体现在以下几个方面:
1. 解耦 (Decoupling) - 最核心的价值
- 之前:上游系统需要知道寻源系统的确切网络地址和接口,并与之直接通信。
- 之后:上游系统不再关心谁来处理这个请求,它只需要将一条消息(如
InquiryCreatedEvent)发送到RabbitMQ的特定交换机。我们寻源系统作为消费者,只需要监听这个交换机的消息即可。即使寻源系统正在重启或暂时不可用,消息也会安全地存储在RabbitMQ中,不会丢失。 系统间的依赖从“服务-服务”变成了“服务-消息队列-服务”。
2. 异步与削峰填谷 (Asynchrony & Buffering)
- 之前:一个耗时2秒的询价创建流程,会阻塞上游系统2秒。
- 之后:上游系统发送消息到MQ后,几乎可以立即返回成功响应,将实际的耗时处理抛在脑后。我们寻源系统可以按照自己的处理能力,从MQ中拉取消息并进行消费。突然到来的流量洪峰会被MQ这个“缓冲区”平滑掉,避免了系统被瞬间冲垮。
3. 增强业务能力与可靠性 (Enhanced Capabilities & Reliability) 这正是你项目中 “供应商报价超时自动关闭” 功能的完美体现。
- 之前:依赖低效的数据库轮询,难以实现。
- 之后:
- 当创建一个询价单时,系统会同步发送一条消息到RabbitMQ。
- 这条消息不设置消费者,并配置一个TTL(生存时间),比如48小时(报价窗口期)。
- 48小时后,消息因过期变成死信,会自动被路由到另一个队列——死信队列。
- 此时,我们有一个专门的消费者监听这个死信队列,一旦收到消息(即说明有询价单超时了),就自动执行关闭逻辑。
- 这种方式精准、高效、对数据库无压力,是MQ在解决复杂业务场景上的典范应用。
4. 最终一致性 (Eventual Consistency) 在与下游系统集成时,也可以通过MQ来保证最终一致性。例如,当设定“最优供应商”后,可以通过发布一个 SupplierSelectedEvent 事件,让物流管理系统、PDT系统等各自订阅并更新自己的状态,而不是通过脆弱的同步调用链。
面试回答话术建议
你可以这样组织语言:
“在引入RabbitMQ之前,系统间主要通过同步HTTP调用进行交互。这导致系统间耦合紧密,上游系统的稳定性直接制约着我们,并且缺乏对突发流量的削峰能力。
引入MQ后,我们实现了架构上的解耦和异步化。最典型的例子就是我们用
延时队列+死信队列完美地实现了供应商报价超时自动关闭功能。这个功能在之前需要通过低效的数据库轮询来实现,而现在由MQ内部机制自动触发,精准、高效且不增加数据库压力。总的来说,MQ的引入让我们的系统从脆弱的
请求-响应模型,进化成了更具弹性、可扩展性和可靠性的事件驱动架构。
这样回答,既清晰地对比了前后差异,又通过一个具体、有亮点的案例(延时队列)证明了你的技术深度和MQ的实际价值。
面经二:中软 - 招银云创
Q:分布式 CAP 原理
1. CAP 原理是什么?
CAP原理,也常被称为CAP定理,它指出对于一个分布式计算系统来说,不可能同时完全满足以下三个核心特性:
- C:一致性
- A:可用性
- P:分区容错性
该定理表明,在分布式系统中,当网络发生分区时,我们必须在一致性和可用性之间做出权衡,无法二者兼得。
理解CAP的关键在于认识到它是一个“三选二”的权衡,而不是一个“三选二”的完美方案。由于分区是分布式系统中无法避免的现实,P 实际上是我们必须选择的。因此,真正的选择是在 C 和 A 之间。
2. 深入理解三个核心概念
C:一致性
这里的“一致性”指的是 线性一致性 或 强一致性。它意味着,在任何一次数据读取操作中,系统都应该返回最近一次成功写入的数据。
- 通俗解释:对于所有连接到系统的客户端(无论连接到哪个节点),只要看到某个数据被更新了,那么之后的所有读操作,要么看到的是更新后的值,要么读取失败。系统表现得“好像”只有一个数据副本。
- 例子:你在一台机器上更新了某个值为
100,那么之后从任何其他机器上读取这个值,都必须是100。系统不会让你读到旧的50。
A:可用性
可用性指的是,系统的每一个非故障节点,对于每一个请求(无论读写)都必须给出一个非错误的响应(但不能保证响应中包含的数据是最新的)。
- 通俗解释:只要系统节点没宕机,它就必须响应客户端的请求,不能超时也不能报错。但响应的数据可能是旧的。
- 例子:即使发生了网络分区,导致某个节点无法与其他节点同步数据,它仍然需要处理客户端的读请求。它可能会返回自己本地的旧数据,但绝不会不响应。
P:分区容错性
分区容错性指的是,系统在遇到网络分区(即节点之间无法正常通信)的情况下,仍然能够继续对外提供服务。
- 通俗解释:网络不是100%可靠的,节点之间的网络可能会中断(比如光缆被挖断、交换机故障)。分布式系统必须能够容忍这种情况,部分节点组成的子网络依然可以独立运行,而不是整个系统崩溃。
- 例子:一个分布式系统由北京和上海的两个机房组成。如果它们之间的网络光缆断了,形成了两个无法通信的分区,系统设计上需要能处理这种情况。
3. 为什么不能同时满足?—— CAP 的三种场景
我们通过一个经典的例子来解释:一个由两个节点(Node A, Node B)组成的分布式数据库,它们之间通过网络同步数据。
场景一:满足 CA(放弃 P)
- 选择:保证一致性和可用性,放弃分区容错性。
- 如何实现:系统设计成当节点间无法通信(即发生分区)时,整个系统停止服务(不可用)。
- 结果:当网络正常时,系统是强一致且可用的。一旦网络发生分区,系统为了保持一致性(因为无法同步数据),只能选择不服务,从而牺牲了可用性。这实际上不是一个真正的分布式系统,因为它无法容忍网络故障。典型的单点数据库集群(如主从模式的MySQL,在主从断连时,主库可能被设置为只读或下线)在某些配置下接近这种模式,但严格来说,它们无法完全放弃P。
场景二:满足 CP(放弃 A)
- 选择:保证一致性和分区容错性,放弃可用性。
- 如何实现:当网络分区发生时,系统会锁定受影响的分区,阻止对其的读写操作,以确保数据不会出现不一致。只有那些能与其他大多数节点通信的分区可以继续工作。
- 结果:系统保证了数据的强一致性,但牺牲了部分节点的可用性。客户端连接到被锁定的分区时,会收到错误或超时。
- 典型系统:ZooKeeper, etcd, HBase, MongoDB(使用强一致性配置时)。在选举Leader或网络不稳定时,这些系统可能会短暂不可用。
场景三:满足 AP(放弃 C)
- 选择:保证可用性和分区容错性,放弃强一致性。
- 如何实现:当网络分区发生时,所有节点仍然可以处理读写请求。但这可能导致数据在不同节点上出现不一致(即“最终一致性”)。
- 结果:系统始终保持高可用,但读取的数据可能不是最新的。当网络分区恢复后,系统会通过一些机制(如冲突解决)来逐步达成一致性。
- 典型系统:Cassandra, DynamoDB, Riak, Eureka。这些系统在设计上优先保证可用性。
4. 对 CAP 的常见误解与澄清
- 误解一:CAP是“三选二”,可以任意选择。
- 澄清:P是分布式系统的固有属性,你无法选择“放弃P”,因为网络故障必然会发生。因此,真实的选择是在发生P时,是选择C还是选择A。在系统没有发生分区时,是可以同时实现CA的。
- 误解二:一个系统在整个生命周期中只能是CP或AP。
- 澄清:CAP是针对同一个数据对象的权衡。一个复杂的系统可以为不同的数据模型或不同的操作选择不同的策略。例如,一个系统可以对其核心用户数据采用CP策略,而对用户的会话数据采用AP策略。
- 误解三:放弃C意味着数据永远混乱。
- 澄清:放弃C通常是指放弃强一致性,转而采用最终一致性。系统会保证在未来的某个时间点(在没有新写入的情况下),所有副本的数据会变得一致。这期间会存在一个“不一致窗口”。
5. CAP在现代系统设计中的应用与延伸
BASE理论
为了弥补CAP中放弃强一致性带来的问题,eBay的架构师提出了BASE理论,它是对AP系统的一种实践性描述:
- Basically Available(基本可用):系统在出现不可预知故障时,允许损失部分可用性(如响应时间变长、部分功能降级)。
- Soft state(软状态):允许系统中的数据存在中间状态,并认为该状态不会影响系统的整体可用性(即各节点间的数据复制存在延迟)。
- Eventually consistent(最终一致性):经过一段时间后,所有数据副本最终会达到一致的状态。
BASE理论是构建高可用、可扩展互联网系统的指导思想,它通过牺牲强一致性来换取系统的灵活性和性能。
现实世界中的权衡
现代分布式数据库和中间件提供了灵活的配置,让开发者可以根据业务场景决定CAP的权衡。
- 银行账户、库存系统:对一致性要求极高,通常选择CP。
- 社交媒体点赞、用户会话:对可用性要求更高,可以接受短暂不一致,通常选择AP。
- 服务发现:在微服务架构中,服务发现组件(如Eureka选择AP,Consul选择CP)的不同选择直接影响了系统的行为。
总结
CAP原理是一个揭示分布式系统内在本质的简洁而深刻的模型。它告诉我们:
- 分区是必然发生的,设计系统时必须考虑。
- 在分区发生时,你无法同时保证强一致性和高可用性,必须做出选择。
- 这个选择没有对错,完全取决于你的业务需求。
- 理解CAP,不是为了背诵理论,而是为了在系统设计时做出明智的权衡。 当你设计一个功能时,问问自己:“如果现在网络断了,这个功能是应该报错(CP)还是继续用可能旧的数据提供服务(AP)?” 这个问题的答案,就是CAP原理在你系统中的具体体现。
Q:项目如何体现分布式系统
维度一:架构层面 - 微服务拆分与服务治理
采购公共服务系统(明确的微服务架构)
- 服务拆分:将庞大的ERP系统按业务域拆分为供应商服务、权限服务、评估服务、白名单服务等独立的微服务。
- 服务注册与发现:使用 Nacos 作为注册中心,各个微服务启动时向Nacos注册自己的网络地址,消费者通过服务名而非具体的IP地址来调用服务。
- 配置集中管理:使用 Nacos 作为配置中心,所有微服务的配置(如数据库连接、缓存地址、开关配置)集中管理,实现配置与代码分离和动态刷新。
零部件询报价寻源系统(内聚的微服务或分布式模块)
- 系统边界清晰:虽然项目描述未明确说微服务,但其作为独立系统,与 PDT系统、物流系统 等形成系统间的分布式架构。
- API网关模式:对外提供统一的RESTful API,下游系统通过HTTP调用,体现了面向服务的架构思想。
似乎出了点问题
维度二:数据层面 - 数据分布与一致性
分布式缓存(两个项目都用到了Redis)
- 共享会话:用户登录后,会话信息存储在Redis中,这样无论用户的请求被负载均衡到哪台应用服务器,都能识别其身份。解决了HTTP无状态协议在分布式集群下的状态保持问题。
- 共享数据:热点数据(如供应商信息、零件分类、配置信息)缓存在Redis中,所有服务实例共享同一份数据视图,避免每个实例都去查询数据库,保证数据的一致性和减轻数据库压力。
分布式数据源
- 读写分离与分库分表:你提到的"数据量特别大的表采用分库分表,读写分离的设计",这是数据层分布式的核心体现。数据被水平拆分到不同的数据库实例中,应用需要通过中间件或框架来路由数据访问。
最终一致性(通过消息队列实现)
- 采购系统:供应商状态变更后,通过MQ发送事件消息,让其他关心此状态的服务(如评估服务、白名单服务)异步更新自己的数据,实现数据的最终一致性,而不是强一致的分布式事务。
维度三:通信层面 - 服务间通信模式
同步通信(直接调用)
- RESTful HTTP:零部件系统调用PDT系统的接口获取零件数据,这是典型的同步跨系统调用。
- Feign/RestTemplate:在采购微服务架构内部,服务A通过HTTP客户端(如OpenFeign)调用服务B的接口。
异步通信(消息驱动)
- RabbitMQ的应用:
- 零部件系统:用延时队列+死信队列实现报价超时自动关闭。这是一个经典的基于事件的异步处理模式,将时间触发的逻辑从业务代码中解耦出来。
- 采购系统:服务间通过发布/订阅消息来通知业务事件的发生,实现服务解耦。一个服务完成工作后,不必知道也不关心有多少个其他服务需要感知这个事件。
维度四:容错与弹性层面
服务降级与熔断
- 当零部件系统调用PDT系统接口时,如果PDT系统响应缓慢或不可用,可以通过熔断器(如Hystrix或Sentinel) 快速失败,避免线程被长时间占用,导致自身系统也被拖垮。并可以返回降级数据(如默认配置或缓存中的旧数据),保证核心流程的可用性。
负载均衡
- 在微服务架构中,一个服务通常有多个实例。服务消费者(如Spring Cloud LoadBalancer)会从Nacos获取所有健康的实例列表,并通过负载均衡算法(如轮询、随机)选择一个实例进行调用,从而实现流量分发和高可用。
面试专业回答话术
你可以这样综合阐述:
"这两个项目从不同维度完整地体现了分布式系统的核心思想。
首先,在架构上,采购系统是典型的微服务架构,通过Nacos实现了服务的注册发现和配置集中管理;而零部件系统则体现了系统间的分布式,通过与PDT、物流等外部系统对接,形成了更大的分布式生态。
其次,在数据层,我们都使用了Redis作为分布式缓存来解决会话共享和热点数据问题,并且在大数据场景下采用了分库分表和读写分离,这是数据分布式的直接体现。
最关键的是在通信模式上,我们混合使用了同步的HTTP调用和异步的消息驱动。特别是用RabbitMQ实现的’报价超时自动关闭’功能,完美展现了如何通过消息队列来实现系统解耦和基于事件的最终一致性。
最后,在容错方面,我们通过熔断、降级、负载均衡等机制,来保证在部分依赖不可用时,整个分布式系统依然能保持弹性和可用性。
可以说,从服务治理、数据分布、通信模式到故障处理,这两个项目覆盖了构建一个成熟分布式系统所需要考虑的核心方面。"
这样的回答,展现了你对分布式系统全局的、深度的理解,而不仅仅是停留在技术组件的简单使用上,能够给面试官留下深刻的印象。
Q:OOM 与内存溢出区别
简单来说,它们的关系是:OOM是一个广泛的概念,而Java内存溢出是OOM在Java平台上的具体体现和细分。
1. OOM - 广义的系统级概念
OOM 是 Out Of Memory 的缩写,意为“内存耗尽”。这是一个通用术语,适用于任何计算环境(操作系统、应用程序、编程语言等)。
- 范围: 整个系统或单个进程。
- 根本原因: 程序或系统申请的内存总量,超过了物理内存(RAM)和交换空间(Swap)所能提供的最大容量。
- 触发者: 通常是操作系统内核的内存管理子系统。
- 结果:
- 在类Linux系统中,内核的 OOM Killer 进程会被触发。它会根据一套复杂的算法(参考
oom_score)选择一个或多个“罪魁祸首”进程并将其强制杀死,从而释放内存,保全系统的稳定性。 - 在Windows等系统中,可能会看到“系统资源不足”的提示,或者应用程序被直接终止。
- 在类Linux系统中,内核的 OOM Killer 进程会被触发。它会根据一套复杂的算法(参考
例子: 你同时打开了浏览器(很多标签页)、IDE、虚拟机、数据库,这些程序占用的总内存超过了你的8GB物理内存+8GB交换空间。此时,Linux系统可能会选择杀死你的MySQL进程,并报告一个OOM错误。
2. Java内存溢出 - 具体的JVM平台概念
Java内存溢出 特指在Java虚拟机中发生的内存耗尽情况。它发生在JVM这个“沙箱”内部。
- 范围: JVM进程内部。
- 根本原因: Java应用程序申请的内存,超过了 JVM内存模型(运行时数据区) 中某个特定区域(如堆、元空间等)的最大容量。
- 触发者: JVM自身。
- 结果: JVM会抛出
java.lang.OutOfMemoryError这个错误(注意,是Error,不是Exception),并通常会附带一个详细的错误信息来说明是哪个区域溢出了。JVM进程本身可能还在运行,但抛出错误的那个线程通常会终止。
Java内存溢出的细分类型(非常重要)
由于JVM内存模型划分了不同的区域,所以 OutOfMemoryError 也有不同的类型,这有助于我们精准定位问题:
Java heap space(堆空间溢出)- 原因: 这是最常见的OOM。对象实例主要在堆上分配。当创建了大量对象,并且有无法被垃圾回收的引用(即内存泄漏)时,就会发生堆溢出。
- 错误信息:
java.lang.OutOfMemoryError: Java heap space - 典型场景: 内存泄漏、过大的集合类缓存、加载了大量数据到内存等。
GC overhead limit exceeded(GC开销超出限制)- 原因: JVM花费了太多时间(默认超过98%)在进行垃圾回收,但每次回收的效果极差(默认回收不到2%的堆空间)。这本质上是堆空间问题的另一种表现,意味着堆快被“撑满”了,GC在徒劳地工作。
- 错误信息:
java.lang.OutOfMemoryError: GC overhead limit exceeded
Metaspace(元空间溢出)- 原因: 加载的类太多(如大量使用动态代理、反射、JSP),或类加载器泄漏,导致存储类元数据的元空间(Java 8+,取代了永久代)被占满。
- 错误信息:
java.lang.OutOfMemoryError: Metaspace
Unable to create new native thread(无法创建本地线程)- 原因: 这严格来说不是JVM内存模型的溢出,而是操作系统资源限制。JVM为每个线程分配栈内存(通常是操作系统本地内存,而非JVM堆)。创建了太多线程,耗尽了进程的地址空间或系统线程资源。
- 错误信息:
java.lang.OutOfMemoryError: unable to create new native thread
Requested array size exceeds VM limit(请求的数组大小超过VM限制)- 原因: 应用程序尝试分配一个大于堆大小的数组(例如,在32位JVM上尝试分配1GB的数组)。
- 错误信息:
java.lang.OutOfMemoryError: Requested array size exceeds VM limit
核心区别对比表
| 特性 | OOM (广义) | Java内存溢出 (具体) |
|---|---|---|
| 范围 | 整个操作系统或任意进程 | JVM进程内部 |
| 触发机制 | 操作系统内核(如OOM Killer) | JVM自身 |
| 表现形式 | 进程被强制杀死、系统卡顿 | 抛出 OutOfMemoryError 错误 |
| 错误信息 | 系统日志(如 dmesg) | JVM日志或异常堆栈,信息详细且分类 |
| 根本原因 | 系统总内存不足 | JVM特定内存区域(堆、元空间等)不足 |
| 影响范围 | 可能导致任何进程被杀 | 通常只影响抛出错误的JVM进程 |
联系与总结
- 包含关系: Java内存溢出是OOM的一种特定场景。当Java应用发生内存溢出时,从操作系统的视角看,就是这个JVM进程消耗了大量内存,它本身就可能成为系统级OOM Killer的目标。
- 视角不同:
- 系统管理员更关心广义OOM,因为它会影响整个服务器的稳定性。
- Java开发者更关心Java内存溢出,因为
OutOfMemoryError的错误类型能直接指导我们进行代码优化、JVM参数调优(如-Xmx,-XX:MaxMetaspaceSize)和问题排查(如使用MAT分析堆转储)。
简单比喻:
- 广义OOM 就像一座城市的电力系统超负荷,导致整个区域大停电。
- Java内存溢出 就像你家里的一个特定电器(比如空调)因为功率过高,跳了家里的空气开关,但邻居家不受影响。
OutOfMemoryError的错误信息会告诉你,是空调跳闸了,还是电热水器跳闸了。
Q:Java 内存溢出与内存泄漏的区别
什么是内存泄漏?
在理论上,Java有自动垃圾回收(GC),当一个对象不再被任何地方引用时,GC会自动回收它占用的内存。这似乎应该杜绝内存泄漏。
但实际情况是:内存泄漏在Java中指的是“无意中持有的、不再需要的对象引用,导致这些对象无法被GC回收,从而造成内存的持续消耗”。
核心思想: 对象已经不再被应用逻辑所需要,但因为某些原因,仍然被GC Roots 引用着,从而变得“该死却没死”。
一个简单的比喻
- 内存使用正常: 你从书架上拿了一本书阅读,读完后放回书架。
- 内存泄漏: 你拿了一本书阅读,读完后用一个大夹子把它夹在了书架上(这个夹子就是一个意外的引用)。你永远不会再读这本书,但它也永远无法被放回书箱(被GC回收)。你读的书越多,被夹住的书就越多,最终书架被塞满(内存溢出)。
Java 中典型的内存泄漏场景
以下是一些在Java开发中常见的内存泄漏场景:
1. 静态集合类滥用
静态集合(如 static HashMap, static List)的生命周期与整个应用程序一致(JVM进程)。
public class MemoryLeak {
private static List<Object> staticList = new ArrayList<>();
public void addToStaticList(Object obj) {
staticList.add(obj); // 一旦加入,除非显式移除,否则对象将永远存在
}
}即使你不再需要 obj,它也因为被 staticList 引用而无法被回收。
2. 未关闭的资源(连接、流等)
数据库连接、网络连接、文件流等底层资源使用了 native memory(本地内存)或服务器资源。如果不关闭,不仅可能造成JVM内存压力,还可能拖垮整个服务。
try {
Connection conn = dataSource.getConnection();
// ... 业务逻辑
// 忘记调用 conn.close();
} catch (SQLException e) {
e.printStackTrace();
}现代最佳实践是使用 try-with-resources 语法自动关闭。
3. 监听器和回调未注销
当你向一个全局的管理器注册了监听器(Listener)或回调(Callback),如果在对象不再使用时没有注销,那么管理器会一直持有该对象的引用。
public class MyService {
public void register() {
SomeManager.getInstance().addListener(this); // 注册
}
// 缺少 unregister 方法
}4. 内部类持有外部类引用
非静态内部类(包括匿名内部类)会隐式地持有其外部类的引用。如果这个内部类的生命周期长于外部类(例如,被放入一个全局的线程池或队列),就会导致外部类实例也无法被回收。
public class OuterClass {
private byte[] data = new byte[1024 * 1024]; // 占用大量内存
public void createInnerClass() {
InnerClass inner = new InnerClass();
// 如果 inner 被一个长生命周期的线程持有,那么 OuterClass.this 也无法被回收
SomeGlobalThreadPool.submit(inner);
}
class InnerClass implements Runnable {
@Override
public void run() {
// 这里可以隐式访问 OuterClass.this.data
}
}
}5. 缓存管理不当
使用缓存而不设置大小、过期时间或淘汰策略(如LRU),会导致缓存无限增长,最终引发OOM。
解决方案: 使用弱引用(WeakHashMap)或专业的缓存库(如Guava Cache, Caffeine),它们内置了大小和过期策略。
6. 线程局部变量(ThreadLocal)误用
ThreadLocal 为每个线程提供了一个独立的变量副本。但如果线程是线程池复用的(如Web容器的请求处理线程),那么线程的整个生命周期会非常长。如果在使用完 ThreadLocal 后没有调用 remove() 方法,那么其中存储的对象就会一直存在于线程的 ThreadLocalMap 中,造成泄漏。
private static ThreadLocal<User> userThreadLocal = new ThreadLocal<>();
public void handleRequest(Request request) {
userThreadLocal.set(getUserFromSession(request));
try {
// ... 业务逻辑
} finally {
// 必须清理!
userThreadLocal.remove(); // 如果没有这行,就会发生内存泄漏
}
}内存泄漏、内存溢出与 OOM 的关系
这三者构成了一个清晰的因果链:
- 原因:内存泄漏(Memory Leak)
- 由于代码缺陷,导致无用对象无法被GC回收。
- 这是一个 过程,是问题的根源。
- 结果:内存溢出(OutOfMemoryError)
- 内存泄漏的持续积累(或其他原因,如一次性加载过多数据),导致JVM的堆内存被耗尽。
- 当JVM无法再分配所需内存时,就会抛出
OutOfMemoryError: Java heap space。 - 这是一个 事件,是问题的最终表现。
- 范畴:OOM
- OOM是包含内存溢出在内的一个更广泛的概念。
关系图:代码缺陷(如未释放引用) → 内存泄漏(对象堆积) → JVM堆内存耗尽 → 内存溢出(抛出OutOfMemoryError)
如何排查内存泄漏?
- 启用GC日志: 使用JVM参数
-XX:+PrintGCDetails -Xloggc:<file-path>观察GC行为。如果看到Full GC越来越频繁,且每次回收后老年代可用内存越来越少,基本可以断定有内存泄漏。 - 使用分析工具:
- JConsole / JVisualVM: 实时监控堆内存使用情况,观察内存曲线是否呈“锯齿向上”的趋势。
- 生成堆转储(Heap Dump): 在OOM时自动生成(
-XX:+HeapDumpOnOutOfMemoryError)或使用工具手动生成。 - 使用专业工具分析堆转储: 如 Eclipse Memory Analyzer Tool (MAT)。MAT可以精确定位到是哪个类的哪个对象占用了最大内存,以及是什么GC Roots在引用它们,这是定位内存泄漏的“杀手锏”。
总结:内存泄漏是病根,Java内存溢出是病症。 作为一名Java开发者,我们的主要工作就是通过代码审查、测试和工具分析,找到并根除内存泄漏这个“病根”,从而避免内存溢出这个“病症”的发生。
Q:主流 MQ 的区别
为了帮助你在项目中选择合适的消息队列,下面这个表格从多个核心维度梳理了目前几款主流消息队列的主要区别。
| 特性维度 | Kafka | RocketMQ | RabbitMQ | ActiveMQ |
|---|---|---|---|---|
| 核心定位 | 高吞吐的分布式流处理平台 | 兼具高性能与事务能力的全能型选手 | 灵活、易用的消息代理 | 功能丰富的传统消息中间件 |
| 吞吐量 | ⭐⭐⭐⭐⭐ 极高 (百万级/秒) | ⭐⭐⭐⭐ 高 (十万级/秒) | ⭐⭐⭐ 中 (万级/秒) | ⭐⭐ 中低 (万级/秒) |
| 消息可靠性 | 非常高(通过副本机制保证) | 非常高(基于事务保证) | 最高(AMQP协议保证) | 有较低概率丢失数据 |
| 消息顺序性 | 单分区内有序 | 单队列(queue)内有序 | 单队列内有序(需避免使用高级功能) | 支持 |
| 延迟 | 毫秒级 | 毫秒级 | 微秒级 | 毫秒级 |
| 主要优势 | 极致吞吐、生态完善、堆积能力强 | 高性能、强事务消息、顺序消息 | 灵活的路由、低延迟、多协议支持 | 功能完备、支持多种协议 |
| 典型场景 | 日志采集、流式数据处理、实时数据管道 | 电商交易、金融业务、分布式事务 | 企业级应用、复杂路由、实时通信 | 中小型企业业务系统、多协议集成 |
💡 各款消息队列的深入解析
在表格的基础上,以下是关于这几款消息队列更详细的解读,以帮助你进一步理解它们的特性。
- Apache Kafka Kafka专为高吞吐和大规模实时数据流处理而设计。它采用分区和副本机制,非常适合日志采集、监控数据和构建实时数据管道等场景。不过,它的运维相对复杂,且默认配置下延迟相对较高。
- Apache RocketMQ RocketMQ在高吞吐和低延迟之间取得了很好的平衡,并原生支持分布式事务消息。在电商、金融等对数据一致性要求极高的业务场景(如秒杀、订单处理)中表现出色。其架构源自阿里,经历过"双十一"等超大规模流量考验。
- RabbitMQ 基于AMQP协议,RabbitMQ的核心优势在于其强大的消息路由能力和极低的延迟。通过交换机、绑定键和队列的组合,可以实现非常灵活的消息分发逻辑。它部署简单,文档完善,非常适合业务逻辑复杂但吞吐量要求不是极端的中小型项目。
- ActiveMQ 作为一款老牌的消息中间件,ActiveMQ对JMS规范支持完善,并支持多种协议。其功能全面,但性能上限相对较低,在高并发、高吞吐场景下可能成为瓶颈,且社区活跃度相对不如前三者。
🎯 如何根据场景选择
没有最好的消息队列,只有最合适的。你可以根据以下思路进行选择:
- 选择 Kafka:当你的首要任务是处理海量数据(如日志、指标、用户行为流),并且需要极高的吞吐量用于实时计算或流处理时,Kafka是业内标准。
- 选择 RocketMQ:如果你的业务处于金融、电商等领域,需要同时应对高并发流量和保证分布式事务(如下单扣库存)的强一致性,RocketMQ是更优的选择。
- 选择 RabbitMQ:当你的业务需要复杂的消息路由(如根据不同规则分发消息),或者对响应延迟非常敏感(如实时通知),且总吞吐量在十万级以下时,RabbitMQ非常合适。
- 选择 ActiveMQ:在中小型企业的系统中,需要进行多协议集成或对JMS有强依赖,且对性能要求不极致的场景下,可以考虑使用ActiveMQ。
希望这份详细的分析能帮助你做出明智的选择。如果你的项目有更具体的技术指标或业务场景,我很乐意提供更具针对性的分析。
面经三:紫川软件 - 平安产险
Q:Redis 如何保证缓存数据一致性?
好的,这是一个非常核心的面试题和实际问题。Redis 作为缓存,其核心目的是为了提升性能,但随之而来的就是与底层数据库(如 MySQL)的数据一致性问题。
首先,要明确一个核心观点:在分布式系统下,无法做到绝对的、实时的缓存数据一致性,我们追求的是最终一致性。 我们的目标是尽可能缩短不一致的时间窗口,并保证数据最终是正确的。
下面我们来详细讲解几种主流的保证缓存数据一致性的方案,从常见到最优。
1. 缓存更新策略
这是最基础的决策,即何时、如何更新缓存和数据库。
1.1 Cache-Aside (旁路缓存策略)
这是最常用、最经典的策略。应用代码直接负责与缓存和数据库交互。
- 读流程 (Lazy Loading):
- 接收读请求。
- 首先查询 Redis 缓存。
- 如果缓存命中,直接返回数据。
- 如果缓存未命中,则查询数据库。
- 将数据库查询的结果写入 Redis 缓存,然后返回数据。
- 写流程:
- 接收写请求。
- 更新数据库。
- 删除 Redis 中的缓存数据。
为什么是删除缓存,而不是更新缓存? 这是关键点!如果采用更新缓存,在并发写场景下可能会出现数据不一致。
- 场景:线程 A 和线程 B 按顺序更新同一条数据。
- 线程 A 更新数据库 (value=1)
- 线程 B 更新数据库 (value=2)
- 线程 B 更新缓存 (value=2)
- 线程 A 更新缓存 (value=1) // 此时缓存中是旧数据1,与数据库的新数据2不一致。
- 删除缓存可以避免这个问题,它使缓存失效,下次读取时自然会从数据库加载最新值。
优点:简单、高效,是业界最通用的方案。 缺点:在特定并发场景下,仍会出现短时间的不一致。
2. 应对并发场景的进阶方案
Cache-Aside 策略在并发读写时,可能会因为执行顺序问题导致不一致。
场景:先删缓存,后更新数据库 (并发读写)
- 线程 A (写):
- 删除缓存。
- (此时,由于网络或CPU调度,A暂停)
- 线程 B (读):
- 发现缓存不存在。
- 从数据库读取旧值。
- 将旧值写入缓存。
- 线程 A (写):
- 更新数据库为新值。
结果:缓存中是被线程B写入的旧值,数据库是新值,发生了不一致。
解决方案 1:延迟双删
为了解决上述问题,可以在更新数据库后,再执行一次缓存删除,并给予一定的延迟。
- 删除缓存。
- 更新数据库。
- 睡眠一段时间 (如 500ms - 1s,具体时间需要根据业务读写耗时评估)。
- 再次删除缓存。
第二次删除的目的是为了清除在“更新数据库”这个时间窗口内,可能被其他读请求加载到缓存中的旧数据。 睡眠是为了确保读请求已经完成了“读数据库 -> 写旧数据到缓存”这个操作。
优点:通过增加一次删除操作,大大降低了不一致的概率。 缺点:不优雅,需要预估延迟时间,降低了吞吐量。
解决方案 2:异步重试(推荐)
核心思想是:将第二次删除操作通过异步消息的方式执行,确保它最终能成功。
a. 使用消息队列
- 应用服务在更新数据库后,向消息队列发送一条删除缓存的消息。
- 一个独立的消费者服务消费该消息,执行删除缓存的操作。
- 如果删除失败,消息会被重试,直到成功。
b. 利用数据库 Binlog(最优解) 这是大型互联网公司最常用的方案,将缓存层完全作为数据库的从库。
- 应用服务:更新数据库。
- 一个独立的中间件(如 Canal、Debezium)订阅数据库的 Binlog(二进制日志,记录了所有数据变更)。
- 中间件解析 Binlog,获取变更的数据和操作。
- 中间件根据变更,调用 Redis 的接口删除或更新对应的缓存。
优点:
- 彻底解耦:应用服务只关心写数据库,完全不知道缓存的存在。
- 保证最终一致性:只要数据库更新了,Binlog 就能被解析,缓存最终会被删除。
- 高性能:对主业务链路无侵入。
缺点:架构复杂,需要维护额外的中间件。
3. 其他缓存策略
除了 Cache-Aside,还有一些其他策略,但各有适用场景。
3.1 Write-Through (穿透写)
应用服务将缓存作为主要数据存储。写操作时:
- 先更新缓存。
- 缓存组件自己负责将数据同步到数据库。
优点:能保证缓存和数据库的强一致性。 缺点:写延迟高,因为需要等待两个写操作都完成。对缓存稳定性要求极高。
3.2 Write-Behind (异步写)
Write-Through 的异步版本。写操作时:
- 只更新缓存。
- 缓存组件在后台异步、批量地将数据更新到数据库。
优点:写性能极高。 缺点:有数据丢失风险(缓存宕机),只能保证最终一致性。
总结与最佳实践
| 方案 | 操作顺序 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| Cache-Aside | 读:缓存->DB->回填 写:更新DB->删除缓存 | 简单、通用 | 并发下有短时不一致风险 | 绝大多数业务场景 |
| 延迟双删 | 删除缓存->更新DB->睡眠->再删缓存 | 降低不一致概率 | 不优雅,需估时,性能差 | 对一致性要求稍高,且无法引入复杂架构的场景 |
| 异步重试 (MQ) | 更新DB->发MQ->消费者删缓存 | 解耦,保证最终一致 | 架构稍复杂,需维护MQ | 中大型项目,对一致性要求高 |
| 订阅 Binlog | 更新DB->中间件解析Binlog->删缓存 | 彻底解耦,强保证 | 架构复杂,技术门槛高 | 大型、高并发项目的最佳实践 |
| Write-Through | 更新缓存->缓存同步更新DB | 强一致性 | 写性能差,缓存依赖重 | 缓存即数据库的场景,较少用 |
给出现代架构下的通用建议:
- 首选基础方案:对于大多数应用,使用 Cache-Aside + 删除缓存 就已经足够。可以容忍极短时间(毫秒级)的不一致。
- 升级到可靠方案:如果对一致性要求很高,并且团队有技术能力,强烈推荐使用「订阅数据库 Binlog」 的方案。这是目前最可靠、最优雅的解决方案。
- 设置缓存过期时间:无论使用哪种方案,都务必给缓存数据设置一个合理的过期时间 (TTL)。这是一个兜底方案,即使同步逻辑出现问题,缓存最终也会自动失效,从数据库加载最新数据,保证最终一致性。
- 避免复杂逻辑:尽量避免“更新缓存”的逻辑,坚持使用“删除缓存”,让下一次读请求来触发缓存重建,这样逻辑更简单,更不容易出错。
简单来说,“更新数据库,删除缓存”是基础,而“通过 Binlog 异步删除缓存”是追求极致一致性的终极答案。
Q:项目中优化日志打印大对象的具体实现
核心问题阐述
首先,一句话点明问题的严重性:
"在项目中,我们遇到一个典型的性能陷阱:在DEBUG或INFO级别日志中,直接打印了完整的大对象(如包含几十个字段的供应商对象、查询结果列表等)。 这带来了三个严重后果:
- 日志磁盘爆炸:单条日志可能达到几百KB甚至几MB,迅速写满磁盘。
- CPU资源耗尽:序列化大对象为字符串的
toString()方法非常消耗CPU。- 最危险的:可能诱发OOM。尤其是在使用异步日志框架(如Logback的AsyncAppender)时,如果日志生产速度超过消费速度,大量待写日志的大对象会堆积在内存队列中,直接导致内存溢出。"
具体实现方案(分层讲解)
你可以按照从"最简单"到"最优雅"的顺序来介绍你的解决方案,这能体现你思考的层次。
方案一:最直接的方法 - 重写 toString() 方法
做法: 禁止在实体类中使用Lombok的@Data注解自动生成toString(),而是手动重写,只包含核心ID和名称等关键字段。
示例代码对比:
// 【优化前 - 危险的写法】
@Data
public class Supplier {
private Long id;
private String name;
private String address;
// ... 还有30多个字段
private List<ContactPerson> contactList; // 关联对象,更大!
}
// 打印日志:log.debug("Processing supplier: {}", supplier);
// 输出:Supplier(id=1, name=XX公司, address=XX路..., contactList=[...]) // 巨大!
// 【优化后 - 安全的写法】
@Data
public class Supplier {
private Long id;
private String name;
private String address;
// ... 其他字段
@Override
public String toString() {
return "Supplier{" +
"id=" + id +
", name='" + name + '\'' +
'}'; // 只打印核心标识字段
}
}评价:
"这是最基础、最快速的修复方式,能立即解决大部分问题。但它的缺点是侵入性强,需要在每个实体类中手动维护,而且团队开发中容易遗漏。"
方案二:更优雅的方法 - 使用自定义工具类与注解
做法: 创建一个LogUtil工具类,利用反射或预定义的规则,在需要打印日志时,动态生成一个只包含关键信息的"安全视图"对象。
示例代码:
// 1. 定义一个注解,标记需要日志打印的字段
@Target(ElementType.FIELD)
@Retention(RetentionPolicy.RUNTIME)
public @interface LogField {
}
// 2. 在实体类中标记
@Data
public class Supplier {
@LogField
private Long id;
@LogField
private String name;
private String address; // 这个不会被打印
// ...
}
// 3. 创建日志工具类
public class LogUtil {
public static Object toSafeLogObject(Object obj) {
if (obj == null) {
return null;
}
// 这里可以通过反射读取@LogField注解,构建一个Map或JSON字符串
// 或者简单点:如果是集合,只返回大小;如果是大对象,返回其ID。
if (obj instanceof Collection) {
return "Collection(size=" + ((Collection) obj).size() + ")";
}
if (obj instanceof BaseEntity) { // 假设你的实体有统一基类
return obj.getClass().getSimpleName() + "(id=" + ((BaseEntity) obj).getId() + ")";
}
// 对于其他复杂对象,调用其安全的toString()
return obj.toString();
}
}
// 4. 使用方式
log.debug("Processing supplier: {}", LogUtil.toSafeLogObject(supplier));
// 输出:Processing supplier: Supplier(id=1, name=XX公司)评价:
"这种方式更加优雅和集中,将日志安全的逻辑收敛到了一处,降低了业务代码的侵入性。我们可以根据不同类型对象定制化其’安全视图’。"
方案三:最根本的方法 - 使用日志占位符并前置判断
做法: 在打印DEBUG/TRACE等低级别日志前,先使用isDebugEnabled()进行判断,避免不必要的字符串拼接和对象序列化。
示例代码:
// 【优化前 - 即使日志级别为ERROR,这行代码也会执行toString()】
log.debug("Processing supplier: {}", supplier);
// 【优化后 - 只有启用DEBUG时,才会进行参数计算】
if (log.isDebugEnabled()) {
log.debug("Processing supplier: {}", LogUtil.toSafeLogObject(supplier));
}评价:
"这是性能最高的写法。它从根本上避免了在不需要日志时,任何不必要的计算开销。我们将其作为代码规范在团队中推广,并结合前面的
LogUtil,形成了最佳实践。"
面试完整话术模板
你可以这样连贯地讲述:
"在采购服务项目中,我们曾遇到一个由日志打印大对象引发的严重性能问题。直接打印完整的供应商或评估模板对象,会导致单条日志过大,不仅撑爆磁盘、消耗CPU,更危险的是可能压垮异步日志框架的内存队列,导致OOM。
我的优化是分三步走的:
- 首先,我制定了代码规范,禁止使用Lombok的默认
toString(),要求所有实体类重写该方法,只输出核心ID和名称。- 其次,为了更优雅地统一处理,我设计了一个
LogUtil工具类。它利用反射和自定义注解,能够为任何对象生成一个只包含关键信息的’安全视图’,从根本上避免了敏感数据和超大对象的输出。- 最后,结合性能最佳实践,我们要求在打印DEBUG/TRACE日志前,必须使用
isDebugEnabled()进行判断,避免不必要的日志对象构建开销。通过这些组合措施,我们将单条日志的平均大小降低了90%以上,并且再未发生过因日志打印导致的内存或CPU问题,系统的稳定性和可观测性都得到了显著提升。"
这样回答,你不仅给出了解决方案,还体现了你从问题识别 -> 临时修复 -> 架构优化 -> 规范建立的完整系统性思考能力,非常加分。
面经四:软通 - 华为项目
Q:CAS 中 ABA 问题
1. 什么是 CAS ?
在深入ABA问题之前,我们必须先理解CAS本身。
CAS(Compare-And-Swap) 是一种无锁编程的核心原子操作。它用于实现多线程环境下的同步,而无需使用传统的互斥锁。
一个CAS操作包含三个操作数:
- 内存位置(V)
- 期望的原始值(A)
- 新值(B)
CAS的操作逻辑是:
“我认为内存位置V的值应该是A。如果是,那么请将V的值更新为B;否则,不要修改它,但要告诉我当前的实际值是什么。”
这个操作是作为一条单独的原子指令由CPU提供的(例如,在x86架构上是 CMPXCHG 指令)。这意味着在整个比较和交换的过程中,不会有其他线程插入来修改这个内存值。
CAS的典型应用:
- 实现原子类(如
java.util.concurrent.atomic包下的AtomicInteger)。 - 实现自旋锁。
- 实现无锁数据结构(如队列、栈)。
2. ABA 问题的定义与产生场景
ABA问题是CAS操作中一个经典且隐蔽的陷阱。
定义: ABA问题是指,一个线程在执行CAS操作时,发现内存位置V的值确实是它期望的A,于是它认为这个值没有被修改过,并成功地将它更新为B。然而,在它读取A和进行CAS操作的这段时间内,内存值可能已经经历了一个变化循环:从A变为B,然后又变回A。
这个“A -> ? -> A”的过程,使得第一个线程的CAS操作在逻辑上变得不再安全,因为它所基于的假设(“值没变,所以状态也没变”)是错误的。
一个生动的比喻(栈的ABA问题)
假设有一个无锁栈,栈顶元素是 A。
- 线程1 准备执行一个出栈操作。它读取到栈顶为
A,然后它被操作系统挂起。- 线程1的期望值:
A - 线程1想要做:将栈顶从
A设置为A.next(假设为null)。
- 线程1的期望值:
- 线程2 在此期间开始运行并执行了一系列操作:
- 步骤1(A->B): 线程2执行出栈,成功将栈顶从
A改为B。 - 步骤2(B->A): 线程2又执行入栈,将
A再次压入栈中。此时栈顶又变回了A。注意:虽然栈顶的值还是A,但整个栈的状态已经发生了变化! 比如,A.next可能已经不再是之前的null,或者栈中的其他元素已经变了。
- 步骤1(A->B): 线程2执行出栈,成功将栈顶从
- 线程1 恢复运行,开始执行CAS操作。它检查栈顶:“嗯,还是
A,和我离开时一样”。于是CAS成功,将栈顶设置为A.next(即null)。
结果: 线程2入栈的 A 被线程1的CAS操作无情地丢弃了,栈顶直接变成了 null。这导致数据丢失,破坏了栈的完整性。
3. ABA问题的根本原因与危害
根本原因: CAS操作只关注值的相等性,而忽略了状态的变化历史。它无法感知到值在中间过程中是否发生过变化。
危害:
- 数据不一致: 如上例所示,会导致数据丢失或数据结构被破坏。
- 逻辑错误: 程序的业务逻辑可能依赖于“值未被改变”这一强假设。ABA的发生使得这个假设不成立,从而导致难以复现和调试的逻辑错误。
- 隐蔽性强: ABA问题在高并发场景下发生的概率相对较低,且难以通过常规测试发现,通常需要在极大压力下长时间运行才会暴露,因此非常危险。
4. 解决方案
解决ABA问题的核心思想是:让CAS操作不仅关心值,还要关心版本号或状态标识。
方案1:原子引用+版本号(Stamp)
这是最常用、最经典的解决方案。
原理: 不再仅仅比较一个值,而是比较一个 (值, 版本号) 对。每次更新值,版本号都递增(或改变)。这样,即使值从A变回A,版本号也早已不同。
在Java中,可以使用 AtomicStampedReference<V> 类。
import java.util.concurrent.atomic.AtomicStampedReference;
public class ABASolution {
private static AtomicStampedReference<String> atomicStampedRef =
new AtomicStampedReference<>("A", 0); // 初始值"A",初始版本号0
public static void main(String[] args) throws InterruptedException {
String initialRef = atomicStampedRef.getReference();
int initialStamp = atomicStampedRef.getStamp();
// 线程1:模拟ABA场景
Thread t1 = new Thread(() -> {
try {
// 模拟线程1在读取后暂停
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 尝试CAS,期望值是"A",期望版本号是0,新值是"B",新版本号是1
boolean success = atomicStampedRef.compareAndSet(
"A", "B", initialStamp, initialStamp + 1);
System.out.println("Thread 1 CAS: " + success); // 输出 false! 因为版本号变了
});
// 线程2:执行 A -> B -> A 的操作,并修改版本号
Thread t2 = new Thread(() -> {
// A -> B,版本号 0 -> 1
atomicStampedRef.compareAndSet("A", "B", initialStamp, initialStamp + 1);
System.out.println("Thread 2: A -> B. Stamp: " + atomicStampedRef.getStamp());
// B -> A,版本号 1 -> 2
atomicStampedRef.compareAndSet("B", "A", atomicStampedRef.getStamp(), atomicStampedRef.getStamp() + 1);
System.out.println("Thread 2: B -> A. Stamp: " + atomicStampedRef.getStamp());
});
t1.start();
t2.start();
t1.join();
t2.join();
}
}方案2:原子标记引用(AtomicMarkableReference)
这个方案是版本号的一个简化版。它不使用数字版本号,而是使用一个 boolean 标记位。每次修改时,翻转这个标记位。
它适用于“这个值是否被修改过”这种二元状态判断,不如版本号精确,但开销更小。
方案3:使用具有唯一性的对象
确保要CAS的引用指向的对象是“一次性”的。一旦被修改,就创建一个新的对象,而不是复用旧对象。
例如,在上面的栈例子中,我们可以规定每次入栈的节点都必须是新创建的 Node 对象。这样,即使线程2将 A 再次入栈,它也是一个新的 Node 实例(内存地址不同),线程1在CAS时发现期望的引用(旧的A对象地址)和当前栈顶的引用(新的A对象地址)不同,CAS就会失败。
在Java中,可以使用 AtomicReference<V>,但必须保证不重用对象。
总结
| 方面 | 描述 |
|---|---|
| 问题本质 | CAS只校验值的同一性,不校验状态的连续性。 |
| 产生条件 | 一个值被改为其他值后又改回原值。 |
| 核心危害 | 导致数据结构的完整性和业务逻辑的正确性被破坏,且问题隐蔽。 |
| 解决方案 | 引入版本号(AtomicStampedReference)或唯一标识,让CAS从“比较值”升级为“比较状态”。 |
在实际开发中,如果您的应用场景存在值被循环修改的可能,并且状态的连续性对业务逻辑至关重要,那么必须使用带版本号的原子引用来规避ABA问题。对于简单的计数器等场景,普通的CAS操作通常是安全的。
Q:在项目中有用到线程池吗,如果有,如何应用线程池?
当然有使用,线程池是这类企业级系统中提升性能的核心组件。下面我将详细说明在项目中如何专业地应用线程池。
线程池在项目中的核心应用场景
1. Excel数据导入 - 主要应用场景
这是你职责中明确提到的,也是线程池最经典的应用。
问题背景:
- 需要导入的零部件数据可能包含数万行
- 每行数据需要:数据校验 → 格式转换 → 业务规则验证 → 数据库写入
- 单线程串行处理需要5分钟以上,用户体验极差
线程池解决方案:
// 1. 创建专用的线程池
@Bean("excelImportExecutor")
public ThreadPoolTaskExecutor excelImportExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(5); // 核心线程数
executor.setMaxPoolSize(10); // 最大线程数
executor.setQueueCapacity(100); // 队列容量
executor.setThreadNamePrefix("excel-import-"); // 线程名前缀,便于监控
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy()); // 拒绝策略
executor.initialize();
return executor;
}
// 2. 使用CompletableFuture进行并行处理
public void importParts(List<PartData> partDataList) {
// 将大数据列表拆分成小批次(如每批100条)
List<List<PartData>> batches = Lists.partition(partDataList, 100);
// 为每个批次创建异步任务
List<CompletableFuture<Void>> futures = batches.stream()
.map(batch -> CompletableFuture.runAsync(() -> {
processBatch(batch); // 处理单个批次
}, excelImportExecutor)) // 指定使用自定义线程池
.collect(Collectors.toList());
// 等待所有任务完成
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();
}技术要点:
- 分批处理:避免创建过多线程,控制资源消耗
- 使用
CallerRunsPolicy:当队列满时,由调用线程执行,保证任务不丢失 - 线程命名:便于在日志和监控中定位问题
2. 供应商报价超时检查 - 异步任务调度
虽然你用了RabbitMQ的延时队列,但线程池也可以用于类似的周期性检查任务。
// 使用Spring的@Scheduled和线程池执行定时任务
@Scheduled(fixedRate = 300000) // 每5分钟执行一次
public void checkQuoteTimeout() {
// 查询即将超时的报价单
List<Quote> expiringQuotes = quoteService.findExpiringQuotes();
// 使用线程池并行处理超时逻辑
expiringQuotes.stream()
.forEach(quote -> CompletableFuture.runAsync(() -> {
quoteTimeoutService.processTimeout(quote);
}, taskExecutor));
}3. 数据导出与报表生成
与导入类似,大数据量的Excel导出也需要并行处理。
public CompletableFuture<ExportResult> exportQuotationReport(ExportRequest request) {
return CompletableFuture.supplyAsync(() -> {
// 1. 查询数据
List<QuoteData> data = quoteRepository.findByCriteria(request);
// 2. 生成Excel文件
return excelGenerator.generateReport(data);
}, reportExportExecutor); // 使用专门的报表导出线程池
}4. 外部系统数据同步
与PDT系统、物流系统等的数据同步可以使用线程池实现异步非阻塞调用。
public void syncPartDataToLogisticsSystem(Long partId) {
CompletableFuture.runAsync(() -> {
try {
logisticsSystemClient.syncPartInfo(partId);
} catch (Exception e) {
log.error("同步零件数据到物流系统失败, partId: {}", partId, e);
// 记录失败,后续重试
retryService.recordSyncFailure(partId, "LOGISTICS");
}
}, externalSyncExecutor);
}线程池配置的考量因素
为什么需要自定义线程池而不是使用默认的?
- 资源隔离:
excel-import:CPU密集型,线程数 ≈ CPU核心数external-sync:IO密集型,线程数可以更多report-export:内存密集型,需要限制并发数
- 避免相互影响:
- 一个耗时的Excel导入任务不应该阻塞紧急的价格计算请求
- 通过不同的线程池实现业务隔离
典型配置示例:
# application.yml
async:
task:
execution:
excel-import:
core-pool-size: 4
max-pool-size: 8
queue-capacity: 50
external-sync:
core-pool-size: 10
max-pool-size: 20
queue-capacity: 100
report-export:
core-pool-size: 2
max-pool-size: 4
queue-capacity: 10面试回答话术
你可以这样专业地阐述:
"在线程池的应用上,我们主要围绕性能瓶颈的并行化和异步化处理两个目标。
最典型的案例就是您看到的Excel导入优化。 之前单线程处理数万行数据需要5分钟,我通过:
- 自定义线程池,根据服务器CPU核心数和任务特性配置合适的参数。
- 采用 CompletableFuture + 分批处理 的模式,将大数据列表拆分成小批次并行处理。
- 为不同业务场景配置隔离的线程池,比如Excel导入、外部系统同步、报表生成都有各自的线程池,避免相互阻塞。
通过这套方案,我们将导入时间从5分钟优化到了10秒内,并且通过合理的拒绝策略和线程池监控,保证了系统在高并发导入时的稳定性。
此外,在供应商报价超时检查、大数据报表导出等场景也都广泛应用了线程池技术,实现了系统性能的全面提升。"
这样回答既体现了你的技术深度(线程池参数调优、资源隔离),又展示了业务价值(性能提升数据),还体现了系统设计思维(不同场景的不同策略),是一个全面而专业的回答。
Q:索引失效与最左前缀匹配原则
Q:联合索引(ABC,A 等于,B大于,C等于)是否用到了索引?
面经五:欧肯信息科技 - 香港项目
Q:ArrayList 与 LinkedList 的区别
Q:Spring IOC 原理
Q:Spring MVC 如何进行异常处理?
Q:如何保证幂等性?
Q:CompletableFuture 在项目中如何实现?
Q:CompletableFuture 中如何处理异常?
Q: Java 8的新垃圾回收器对比之前有什么大的变化?
面经六:京北方 - 珠海工行
Q:项目问到并发导入数据最后出现异常如何处理?
异常处理的核心原则
- 用户体验第一:给用户明确、友好的反馈,告知成功/失败情况。
- 数据一致性:确保数据不丢、不重、不错。
- 系统可用性:局部失败不应导致整个系统崩溃。
- 可追溯性:任何异常都必须有迹可循,便于排查。
具体异常场景与处理方案
场景一:数据导入过程中的异常
可能异常:
- 单条数据格式错误(如日期格式不对、数字解析失败)
- 业务逻辑校验失败(如供应商不存在、零件编号重复)
- 数据库约束冲突(唯一键冲突、外键不存在)
- 系统级错误(数据库连接中断、Redis超时、网络抖动)
处理策略:
- 采用 "部分成功,部分失败" 策略
- 不能因为单条记录的失败而回滚整个导入任务。
- 实现一个批量操作的"柔性事务"。
- 实现方案:
public class DataImportService {
public ImportResult concurrentImport(List<PartData> dataList) {
// 1. 数据预处理与分批
List<List<PartData>> batches = Lists.partition(dataList, 100);
List<CompletableFuture<BatchResult>> futures = new ArrayList<>();
// 2. 为每个批次创建异步任务
for (int i = 0; i < batches.size(); i++) {
final int batchIndex = i;
List<PartData> batch = batches.get(i);
CompletableFuture<BatchResult> future = CompletableFuture.supplyAsync(() -> {
BatchResult batchResult = new BatchResult();
for (PartData data : batch) {
try {
// 3. 单条记录事务处理
processSingleRecord(data);
batchResult.addSuccess(data);
} catch (DataValidationException e) {
// 业务校验异常 - 记录但继续处理其他数据
batchResult.addFailed(data, "数据校验失败: " + e.getMessage());
} catch (DuplicateKeyException e) {
// 唯一键冲突 - 记录但继续处理
batchResult.addFailed(data, "数据重复: " + e.getMessage());
} catch (Exception e) {
// 系统级异常 - 记录并可能终止当前批次
batchResult.addFailed(data, "系统错误: " + e.getMessage());
log.error("处理数据异常, data: {}", data, e);
}
}
return batchResult;
}, importExecutor);
futures.add(future);
}
// 4. 汇总所有批次结果
return aggregateResults(futures);
}
@Transactional(propagation = Propagation.REQUIRES_NEW) // 每条记录独立事务
public void processSingleRecord(PartData data) {
// 数据校验
validateData(data);
// 业务逻辑处理
processBusinessLogic(data);
// 数据持久化
saveToDatabase(data);
}
}关键技术点:
@Transactional(propagation = Propagation.REQUIRES_NEW):为每条记录创建独立事务,确保单条失败不影响其他记录。- 异常分类处理:区分业务异常和系统异常,采取不同策略。
- 结果聚合:最终生成详细的导入报告。
场景二:数据导出过程中的异常
可能异常:
- 查询超时(数据量太大,SQL执行慢)
- 内存溢出(OOM,数据量超出JVM堆内存)
- 文件生成失败(磁盘空间不足、Excel格式错误)
- 网络中断(下载过程中客户端断开连接)
处理策略:
- 流式查询 + 分页生成
- 避免一次性加载所有数据到内存。
public void exportQuotationData(ExportRequest request, HttpServletResponse response) {
String taskId = generateTaskId();
try {
// 1. 立即响应,异步处理
response.setHeader("X-Task-Id", taskId);
writeInitialResponse(response, "导出任务已开始");
// 2. 异步执行导出
CompletableFuture.runAsync(() -> {
try {
// 3. 使用游标或分页流式查询
try (Cursor<QuotationData> cursor = quotationRepository.streamByCriteria(request)) {
ExcelWriter excelWriter = EasyExcel.write(getOutputStream(taskId))
.head(QuotationData.class)
.build();
int rowCount = 0;
List<QuotationData> batch = new ArrayList<>(1000);
for (QuotationData data : cursor) {
batch.add(data);
rowCount++;
// 每1000条刷新一次到磁盘,避免内存堆积
if (batch.size() >= 1000) {
excelWriter.write(batch, EasyExcel.writerSheet("报价数据").build());
batch.clear();
}
// 定期更新进度
if (rowCount % 5000 == 0) {
updateProgress(taskId, rowCount);
}
}
// 写入剩余数据
if (!batch.isEmpty()) {
excelWriter.write(batch, EasyExcel.writerSheet("报价数据").build());
}
excelWriter.finish();
markTaskAsCompleted(taskId, rowCount);
}
} catch (Exception e) {
log.error("导出任务失败, taskId: {}", taskId, e);
markTaskAsFailed(taskId, e.getMessage());
}
}, exportExecutor);
} catch (Exception e) {
log.error("创建导出任务失败", e);
throw new ExportException("创建导出任务失败: " + e.getMessage());
}
}关键技术点:
- 异步处理:避免HTTP请求超时。
- 游标查询:使用Spring Data JPA的Streamable或MyBatis的Cursor进行流式查询。
- 分批写入:避免一次性生成超大Excel文件导致OOM。
- 进度跟踪:通过Redis或数据库记录任务状态,支持进度查询。
场景三:系统级并发异常
可能异常:
- 数据库连接池耗尽
- 死锁(多个导入任务同时操作相同资源)
- 资源竞争(多个线程同时处理相同供应商的数据)
处理策略:
- 资源隔离与限流
@Bean("importExecutor")
public ThreadPoolTaskExecutor importExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(2); // intentionally small
executor.setMaxPoolSize(4);
executor.setQueueCapacity(10);
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
executor.setThreadNamePrefix("import-");
return executor;
}- 分布式锁防止资源竞争
public void processSingleRecord(PartData data) {
String lockKey = "import:supplier:" + data.getSupplierId();
RLock lock = redissonClient.getLock(lockKey);
try {
// 尝试获取锁,等待5秒,锁有效期30秒
if (lock.tryLock(5, 30, TimeUnit.SECONDS)) {
// 处理同一供应商的数据,避免并发问题
processSupplierData(data);
} else {
throw new ConcurrentAccessException("系统繁忙,请稍后重试");
}
} finally {
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}完整的异常处理架构
1. 统一的异常处理框架
@ControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(DataImportException.class)
public ResponseEntity<ApiResponse> handleImportException(DataImportException e) {
// 返回结构化的错误信息
return ResponseEntity.status(HttpStatus.BAD_REQUEST)
.body(ApiResponse.error(e.getErrorCode(), e.getMessage(), e.getFailedRecords()));
}
@ExceptionHandler(ExportException.class)
public ResponseEntity<ApiResponse> handleExportException(ExportException e) {
return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR)
.body(ApiResponse.error("EXPORT_ERROR", e.getMessage()));
}
}2. 完善的监控与告警
- 通过Micrometer监控线程池状态、数据库连接池使用率
- 关键异常通过钉钉/邮件告警
- 通过ELK收集和分析异常日志
面试回答话术
你可以这样总结:
"在并发导入导出场景下,我们的异常处理是分层、分场景的:
对于导入异常,我们采用’部分成功’策略。通过为每条记录创建独立事务,结合精细的异常分类捕获,确保单条数据的失败不会影响整体导入流程,同时为用户提供详细的失败报告。
对于导出异常,核心是防患于未然。我们通过流式查询、分批写入的技术,从根本上避免了OOM和超时问题。同时采用异步任务机制,让用户能够跟踪导出进度,并在失败时获得明确反馈。
在系统层面,我们通过线程池隔离、分布式锁、限流等手段,预防并发带来的系统性风险,确保局部异常不会扩散。
这套方案让我们在面对日均数十万的导入导出请求时,仍能保证99.5%以上的任务成功率和良好的用户体验。"
这样的回答体现了你从具体技术实现到架构设计思想的全面思考,展现了处理复杂问题的能力。
Q:RabbitMQ 工作模式
1. 简单模式 / Hello World
这是最基础的模式,它甚至不需要显式地声明交换器。
- 核心组件:一个生产者、一个队列、一个消费者。
- 交换器:使用默认的匿名交换器(
"")。生产者将消息直接发送到队列。 - 路由逻辑:消息直接进入指定的队列。
- 应用场景:最简单的任务分发,一对一通信。
流程图: 生产者 —> (默认交换器) —> 队列 —> 消费者
2. 工作队列模式 / Work Queue
用于在多个消费者之间分发耗时的任务。
- 核心组件:一个生产者、一个队列、多个消费者。
- 交换器:同样使用默认交换器。
- 路由逻辑:消息进入一个队列,但由多个消费者共同处理。RabbitMQ 会以轮询 的方式将消息依次分发给不同的消费者。
- 关键特性:
- 消息确认:消费者处理完消息后必须发送一个确认信号,否则RabbitMQ会认为消息处理失败,并将其重新投递给其他消费者。
- 公平分发:可以设置
prefetch_count=1,告诉RabbitMQ一次只给一个消费者发一条消息,避免能力强的消费者空闲,而能力弱的消费者积压任务。
- 应用场景:处理图片、视频转码,发送大量邮件等耗时任务。
流程图:
|--> 消费者1
生产者 --> 队列 --> 消费者2
|--> 消费者3(消息 m1, m3, m5 发给消费者1;m2, m4, m6 发给消费者2…)
3. 发布/订阅模式 / Publish/Subscribe
将一条消息广播给所有绑定到该交换器的队列。
- 核心组件:一个生产者、一个 Fanout 类型的交换器、多个队列、多个消费者。
- 交换器类型:Fanout。它会将收到的所有消息广播到所有与之绑定的队列中。
- 路由逻辑:消息发送到 Fanout 交换器,交换器将其复制并转发到每一个绑定的队列。
- 应用场景:系统广播、新闻推送、事件通知(需要让多个不同服务同时知道某个事件发生)。
流程图:
|--> 队列1 --> 消费者1
生产者 --> (Fanout交换器) --> 队列2 --> 消费者2
|--> 队列3 --> 消费者3(同一条消息会被所有三个消费者收到)
4. 路由模式 / Routing
根据消息的路由键 有选择地接收消息。
- 核心组件:一个生产者、一个 Direct 类型的交换器、多个队列、多个消费者。
- 交换器类型:Direct。它会将消息的路由键 与队列和交换器绑定时使用的 绑定键 进行精确匹配。只有匹配成功,消息才会被路由到该队列。
- 路由逻辑:队列在绑定到交换器时,需要指定一个绑定键(例如:
error,info,warning)。生产者发送消息时也指定一个路由键。交换器会精确匹配这两个键。 - 应用场景:日志系统,让消费者只接收特定级别的日志(例如,一个消费者只接收
error日志,另一个接收所有日志)。
流程图:
生产者 --(消息路由键: error)--> (Direct交换器)
/ | \
(绑定键:error) (绑定键:info) (绑定键:warning)
/ | \
队列[错误日志] 队列[信息日志] 队列[警告日志]
| | |
消费者A 消费者B 消费者C(只有消费者A会收到这条 error 消息)
5. 主题模式 / Topics
路由模式的增强版,允许使用通配符进行模糊匹配。
- 核心组件:一个生产者、一个 Topic 类型的交换器、多个队列、多个消费者。
- 交换器类型:Topic。
- 路由逻辑:
- 绑定键是一个包含通配符的字符串,用点号
.分隔。 *(星号):匹配一个单词。#(井号):匹配零个或多个单词。- 生产者发送带路由键的消息,交换器根据绑定键的模式进行匹配。
- 绑定键是一个包含通配符的字符串,用点号
- 应用场景:非常灵活的消息筛选。例如:
- 绑定键
usa.news:只接收美国新闻。 - 绑定键
usa.weather:只接收美国天气。 - 绑定键
*.news:接收所有国家的新闻。 - 绑定键
#.news:同上。 - 绑定键
usa.#:接收美国的所有消息。
- 绑定键
流程图:
生产者 --(路由键: quick.orange.rabbit)--> (Topic交换器)
/ | \
(绑定键: *.orange.*) (*.rabbit) (lazy.#)
/ | \
队列A[橙色的动物] 队列B[兔子] 队列C[懒惰的一切]
| | |
消费者1 消费者2 消费者3(这条消息会匹配到 *.orange.* 和 lazy.#,所以会被投递到队列A和队列C)
6. 头部模式 / Headers
一种不依赖于路由键,而是根据消息的头部属性来路由的模式。它不常用。
- 交换器类型:Headers。
- 路由逻辑:队列在绑定时会指定一组键值对参数。生产者发送消息时,也在头部附带一组键值对。交换器会检查消息的头部是否与绑定的参数匹配。匹配规则可以是
all(全部匹配)或any(匹配任意一个)。 - 应用场景:当路由条件非常复杂,无法用简单的路由键表示时。
7. RPC 模式
严格来说,这不是一种交换器类型,而是一种应用模式。它允许客户端发送请求消息,服务端回复响应消息,实现远程过程调用。
- 核心机制:
- 客户端发送一条消息,其中包含一个唯一的
correlation_id和一个用于回复的reply_to队列名。 - 服务端处理请求,然后将结果发送到
reply_to队列,并带上相同的correlation_id。 - 客户端监听
reply_to队列,通过correlation_id来匹配响应和请求。
- 客户端发送一条消息,其中包含一个唯一的
总结对比
| 模式名称 | 交换器类型 | 路由规则 | 核心应用 |
|---|---|---|---|
| 简单模式 | (默认) | 直接指定队列 | 一对一简单通信 |
| 工作队列 | (默认) | 轮询分发 | 多消费者任务分发 |
| 发布/订阅 | Fanout | 广播 | 一对多消息广播 |
| 路由模式 | Direct | 精确匹配路由键 | 有选择性地接收消息(如日志级别) |
| 主题模式 | Topic | 通配符匹配路由键 | 灵活地、多维度地筛选消息 |
| 头部模式 | Headers | 匹配消息头属性 | 复杂条件路由(不常用) |
理解这些模式的关键在于理解交换器类型及其路由逻辑。选择哪种模式取决于你的业务场景中,消息需要如何被分发给不同的消费者。
Q:Nacos 如何监控服务宕机,分几步来对宕机的服务进行交互
好的,这是一个非常核心的微服务问题。Nacos 对服务宕机的监控和处理是一个典型的“主动探测 + 客户端心跳”模式,其交互流程可以清晰地分为几个步骤。
下面我将分两部分详细阐述:
- Nacos 如何监控服务宕机(服务发现与健康检查机制)
- 服务宕机后的交互步骤
第一部分:Nacos 如何监控服务宕机
Nacos 主要通过两种方式来检测服务实例是否存活:
1. 客户端主动上报心跳(默认模式 - AP 模式)
这是 Nacos 默认的、基于 Distro 协议的 AP 模式下的健康检查方式。
- 原理:服务实例在注册到 Nacos 后,会作为一个客户端,定期(例如每5秒)向 Nacos 服务器发送一个心跳。这个心跳本质上是一个周期性的健康报告,告诉服务器:“我还活着”。
- 关键配置:
心跳间隔:客户端发送心跳的频率。超时时间:Nacos 服务器在多久没收到心跳后,会认为该实例不健康。删除超时:在不健康状态持续多久后,直接从服务列表中删除该实例。
- 工作模式:这种方式将健康检查的压力分散到了各个客户端,服务器端主要是记录和判断,非常适合大规模集群。
2. 服务器端主动健康检查(CP 模式)
当使用 Nacos 的基于 Raft 协议的 CP 模式时,或者用户显式配置了 ephemeral=false 注册临时实例时,Nacos 服务器会主动对服务实例进行健康检查。
- 原理:Nacos 服务器会定期(例如每20秒)主动向配置好的服务实例健康检查端点(如
/health)发起请求(如 HTTP 请求或 TCP 端口探测)。 - 关键配置:
检查间隔:服务器发起检查的频率。超时时间:等待服务响应的超时时间。健康路径:健康检查的 URL 路径。
- 工作模式:这种方式由服务器主动发起,对网络和服务器的压力更大,但控制权在服务器端。
总结:在绝大多数 Spring Cloud Alibaba 等场景下,我们使用的是默认的临时实例和客户端心跳模式。因此,下面的交互步骤将基于这种模式展开。
第二部分:服务宕机后的交互步骤(基于客户端心跳模式)
假设我们有一个 UserService 实例,它已经注册到了 Nacos 服务器。现在我们模拟该实例突然宕机(如进程被杀掉)。
整个交互流程可以分为以下几步:
第1步:心跳停止
- 动作:UserService 实例由于宕机,停止了向 Nacos Server 发送周期性的心跳包。
- 状态:Nacos Server 的注册中心里,该实例的“最后心跳时间”停止更新。
第2步:标记为不健康
- 动作:Nacos Server 内部有一个健康检查线程,它会扫描所有实例的“最后心跳时间”。如果发现当前时间减去“最后心跳时间”超过了预设的超时时间(默认15秒),它会将该实例的健康状态设置为
false。 - 状态:在 Nacos 控制台上,你可以看到该实例的“健康实例数”减少,“不健康实例数”增加。这个实例仍然在服务列表中,但已经被标记为不健康。
第3步:服务列表更新与推送
- 动作:
- Nacos Server 意识到 UserService 的服务列表发生了变更(有实例变为不健康)。
- 推送机制:Nacos Server 会立即向所有订阅了 UserService 的消费者(如 Gateway、其他微服务)推送一条消息,通知它们服务列表已变更。
- 交互:这是一个 Server Push 模型,非常及时,消费者几乎在秒级就能感知到变化,而不需要等待下一次主动拉取。
第4步:消费者更新本地缓存
- 动作:消费者(如 OrderService)收到 Nacos Server 的推送后,会立即从服务器拉取最新的 UserService 实例列表。在拉取到的列表中,那个被标记为不健康的实例已经被过滤掉(或者消费者本地在收到列表后,会主动剔除不健康实例)。
- 结果:从此以后,OrderService 发起的对于 UserService 的负载均衡调用(如通过 Spring Cloud LoadBalancer 或 Ribbon),将不会再被路由到那个已经宕机的实例上。这就实现了服务的自动熔断和故障隔离。
第5步:彻底删除实例
- 动作:如果那个宕机的实例在接下来的一个更长的时间窗口内(删除超时时间,默认30秒)一直没有恢复心跳,Nacos Server 会最终将这个实例从注册列表中彻底删除。
- 状态:在 Nacos 控制台上,该实例会完全消失。
- 注意:删除后,同样会通过第3步的推送机制通知所有消费者。
关键配置参数(Spring Cloud Alibaba)
在你的 application.yml 中,可以通过以下配置调整这些行为:
spring:
cloud:
nacos:
discovery:
# Nacos 服务器地址
server-addr: localhost:8848
# 心跳间隔 (默认5秒) - 客户端->服务端
heart-beat-interval: 5000
# 心跳超时 (默认15秒) - 服务端判断下线
heart-beat-timeout: 15000
# 删除实例超时 (默认30秒) - 服务端彻底删除
ip-delete-timeout: 30000
# 实例是否为临时实例 (true: 用心跳, false: 用服务器端检查)
ephemeral: true总结
Nacos 通过 “客户端心跳 + 服务器端超时判断 + 实时推送” 这一套组合拳,高效地实现了服务宕机的监控和自动处理。其核心交互步骤可以概括为:
- 检测:通过心跳超时检测到不健康实例。
- 标记:在服务器端将其标记为不健康。
- 通知:立即推送变更给所有相关消费者。
- 隔离:消费者更新本地列表,实现流量隔离。
- 清理:最终清理长时间宕机的实例。
这套机制保证了微服务架构的高可用性和自愈能力。
Q:了节省成本,开发测试生产用的一个服务器,Nacos如何区分环境
Q:SQL 查询语句的执行顺序了解吗?
先执行 FROM 确定主表,再执行 JOIN 连接,然后 WHERE 进行过滤,接着 GROUP BY 进行分组,HAVING 过滤聚合结果,SELECT 选择最终列,ORDER BY 排序,最后 LIMIT 限制返回行数。
WHERE 先执行是为了减少数据量,HAVING 只能过滤聚合数据,ORDER BY 必须在 SELECT 之后排序最终结果,LIMIT 最后执行以减少数据传输。
| 执行顺序 | SQL 关键字 | 作用 |
|---|---|---|
| ① | FROM | 确定主表,准备数据 |
| ② | ON | 连接多个表的条件 |
| ③ | JOIN | 执行 INNER JOIN / LEFT JOIN 等 |
| ④ | WHERE | 过滤行数据(提高效率) |
| ⑤ | GROUP BY | 进行分组 |
| ⑥ | HAVING | 过滤聚合后的数据 |
| ⑦ | SELECT | 选择最终返回的列 |
| ⑧ | DISTINCT | 进行去重 |
| ⑨ | ORDER BY | 对最终结果排序 |
| ⑩ | LIMIT | 限制返回行数 |
这个执行顺序与编写 SQL 语句的顺序不同,这也是为什么有时候在 SELECT 子句中定义的别名不能在 WHERE 子句中使用得原因,因为 WHERE 是在 SELECT 之前执行的。
LIMIT 为什么在最后执行?
因为 LIMIT 是在最终结果集上执行的,如果在 WHERE 之前执行 LIMIT,那么就会先返回所有行,然后再进行 LIMIT 限制,这样会增加数据传输的开销。
ORDER BY 为什么在 SELECT 之后执行?
因为排序需要基于最终返回的列,如果 ORDER BY 早于 SELECT 执行,计算 COUNT(*) 之类的聚合函数就会出问题。
SELECT name, COUNT(*) AS order_count
FROM orders
GROUP BY name
ORDER BY order_count DESC;Q:Spring 事务失效场景
一、代理机制问题
1. 方法非public修饰
原因:Spring默认使用CGLIB代理,非public方法无法被代理。
@Transactional
private void privateMethod() { // 事务失效
// ...
}解决:改为public方法。
2. 自调用(同一类内方法调用)
原因:自调用绕过代理对象,直接调用目标方法。
public void methodA() {
methodB(); // 事务失效
}
@Transactional
public void methodB() {
// ...
}解决:
- 注入自身代理对象:
@Autowired private MyService self; - 使用AspectJ模式(编译时织入)。
二、异常处理不当
3. 异常被捕获未抛出
原因:事务仅对未处理的RuntimeException和Error回滚(默认配置)。
@Transactional
public void method() {
try {
// ...
} catch (Exception e) {
// 未抛出异常,事务不会回滚
}
}解决:在catch块中抛出RuntimeException或使用TransactionAspectSupport.currentTransactionStatus().setRollbackOnly()。
4. 错误配置rollbackFor
原因:默认只回滚RuntimeException和Error, checked异常不回滚。
@Transactional
public void method() throws IOException {
throw new IOException(); // 事务不会回滚
}解决:明确指定回滚异常类型:
@Transactional(rollbackFor = Exception.class)三、事务传播行为配置错误
5. 嵌套事务传播行为不当
原因:PROPAGATION_SUPPORTS等方法在无事务时不开启新事务。
@Transactional(propagation = Propagation.SUPPORTS)
public void method() {
// 若外部无事务,此处不会开启事务
}解决:根据业务需求选择合适的传播行为(如REQUIRED)。
四、数据库与引擎支持
6. 数据库引擎不支持事务
原因:如MySQL的MyISAM引擎不支持事务。 解决:改用InnoDB引擎。
7. 数据源未配置事务管理器
原因:未配置PlatformTransactionManager。
@Bean
public PlatformTransactionManager transactionManager(DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}五、其他配置问题
8. 注解被错误覆盖
原因:子类/实现类覆盖父类方法时未添加@Transactional。
public class Parent {
@Transactional
public void method() { /* ... */ }
}
public class Child extends Parent {
@Override
public void method() { // 事务失效
// ...
}
}解决:在子类方法上显式添加注解。
9. 多数据源未指定事务管理器
原因:多数据源环境下未指定transactionManager。
@Transactional("specificTransactionManager")10. Spring Boot自动配置未生效
原因:排除数据源自动配置或手动配置冲突。
@SpringBootApplication(exclude = { DataSourceAutoConfiguration.class })六、排查工具与技巧
开启调试日志:
propertieslogging.level.org.springframework.transaction.interceptor=TRACE检查事务状态:
javaTransactionSynchronizationManager.isActualTransactionActive();验证代理对象:
java// 检查是否为代理对象 System.out.println(this.getClass().getName());
总结
Spring事务失效的核心原因可归纳为:
- 代理机制:非public方法、自调用。
- 异常处理:捕获未抛出、回滚配置错误。
- 配置问题:传播行为、数据源、事务管理器。
- 环境支持:数据库引擎、注解覆盖。
通过理解代理原理、合理配置事务属性及排查工具使用,可有效避免事务失效问题。
Q:缓存穿透解决方案
缓存穿透是指查询的数据在缓存中没有命中,因为数据压根不存在,所以请求会直接落到数据库上。如果这种查询非常频繁,就会给数据库造成很大的压力。
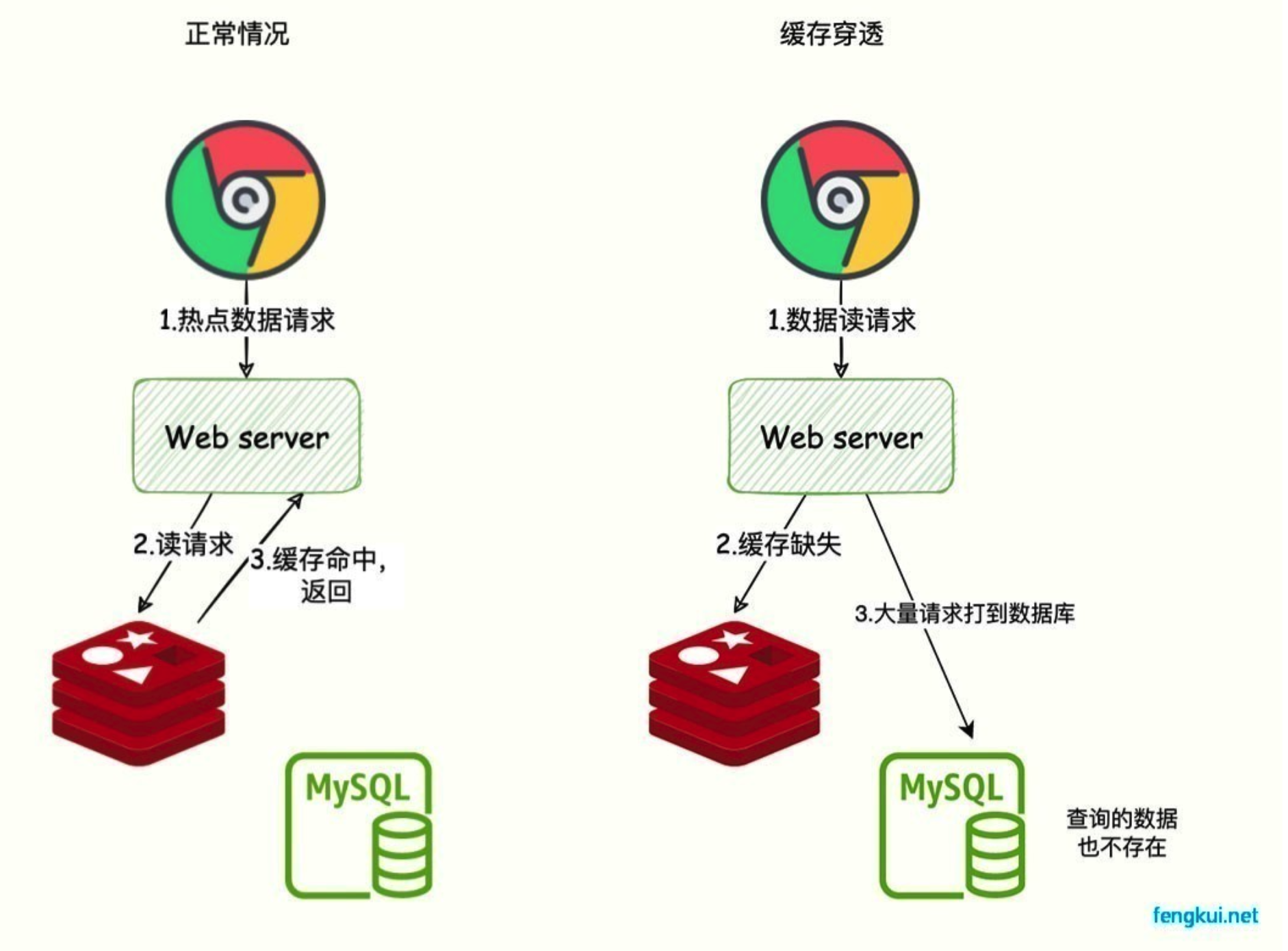
缓存击穿是因为单个热点数据缓存失效导致的,而缓存穿透是因为查询的数据不存在,原因可能是自身的业务代码有问题,或者是恶意攻击造成的,比如爬虫。
常用的解决方案有两种:第一种是布隆过滤器,它是一种空间效率很高的数据结构,可以用来判断一个元素是否在集合中。
我们可以将所有可能存在的数据哈希到布隆过滤器中,查询时先检查布隆过滤器,如果布隆过滤器认为该数据不存在,就直接返回空;否则再去查询缓存,这样就可以避免无效的缓存查询。
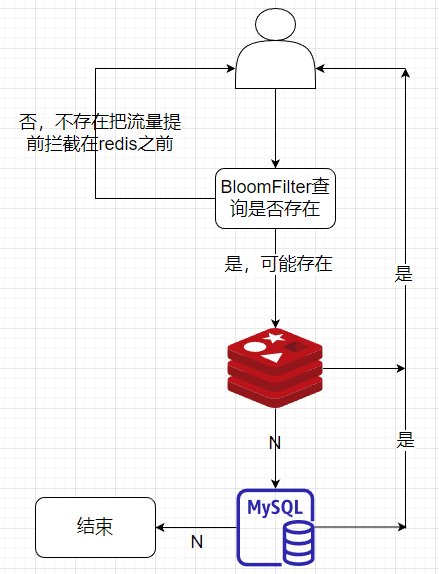
代码示例:
public String getData(String key) {
// 缓存中不存在该key
String cacheResult = cache.get(key);
if (cacheResult != null) {
return cacheResult;
}
// 布隆过滤器判断key是否可能存在
if (!bloomFilter.mightContain(key)) {
return null; // 一定不存在,直接返回
}
// 可能存在,查询数据库
String dbResult = db.query(key);
// 将结果放入缓存,包括空值
cache.set(key, dbResult != null ? dbResult : "", expireTime);
return dbResult;
}布隆过滤器存在误判,即可能会认为某个数据存在,但实际上并不存在。但绝不会漏判,即如果布隆过滤器认为某个数据不存在,那它一定不存在。因此它可以有效拦截不存在的数据查询,减轻数据库压力。
第二种是缓存空值。对于不存在的数据,我们将空值写入缓存,并设置一个合理的过期时间。这样下次相同的查询就能直接从缓存返回,而不再访问数据库。
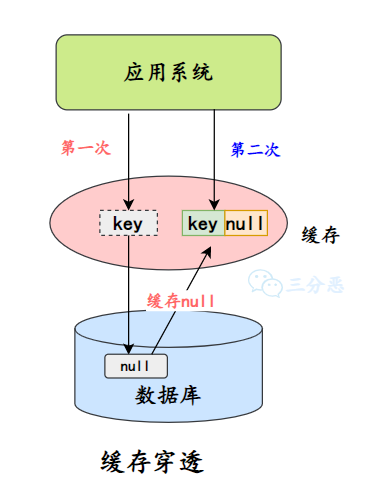
代码示例:
public String getData(String key) {
String cacheResult = cache.get(key);
// 缓存命中,包括空值
if (cacheResult != null) {
// 特殊值表示空结果
if (cacheResult.equals("")) {
return null;
}
return cacheResult;
}
// 缓存未命中,查询数据库
String dbResult = db.query(key);
// 写入缓存,空值也缓存,但设置较短的过期时间
int expireTime = dbResult == null ? EMPTY_EXPIRE_TIME : NORMAL_EXPIRE_TIME;
cache.set(key, dbResult != null ? dbResult : "", expireTime);
return dbResult;
}缓存空值的方法实现起来比较简单,但需要给空值设置一个合理的过期时间,以免数据库中新增了这些数据后,缓存仍然返回空值。
在实际的项目当中,还需要在接口层面做一些处理,比如说对参数进行校验,拦截明显不合理的请求;或者对疑似攻击的 IP 进行限流和封禁。
Q:并发调用接口仅用缓存能否做到性能优化
这是一个非常专业且深入的问题。简短回答是:仅用缓存是远远不够的,它只是性能优化体系中的一个重要环节,而不是全部。
下面我将从多个维度详细分析这个问题。
缓存能解决什么问题?(缓存的作用)
在你的零部件询报价系统中,缓存确实能在以下场景提供显著的性能提升:
- 热点数据读取
- 场景:频繁查询的零部件基础信息、供应商信息、系统配置等。
- 实现:使用Redis缓存这些数据,避免每次请求都查询数据库。
- 效果:将响应时间从几十毫秒降低到几毫秒。
- 计算结果的缓存
- 场景:复杂的报价计算、供应商评估得分、历史价格趋势分析。
- 实现:将计算结果缓存一段时间,相同参数的请求直接返回缓存结果。
- 效果:避免重复的复杂计算,极大降低CPU负载。
- 会话和状态共享
- 场景:用户登录状态、导入导出任务进度、临时表单数据。
- 实现:使用Redis存储分布式会话。
- 效果:支持应用集群部署,任何节点都能识别用户状态。
仅用缓存的局限性在哪里?
缓存主要优化的是读操作,但在高并发接口调用中,你面临的是更复杂的场景:
1. 写操作的瓶颈
- 场景:多个采购员同时为同一零件创建询价单;供应商同时报价。
- 问题:缓存无法解决数据库写竞争。即使有缓存,最终数据还是要写入数据库。高并发写会导致:
- 数据库锁竞争
- 事务冲突
- 数据不一致
2. 复杂查询的挑战
- 场景:根据多条件(零件类型、供应商地区、价格区间、交期)组合筛选询价单。
- 问题:这种查询条件千变万化,无法为所有组合建立缓存键。缓存命中率极低,压力仍然在数据库。
3. 数据一致性问题
- 场景:缓存了零件信息,但后台管理更新了该零件的基础数据。
- 问题:需要维护缓存与数据库的一致性,在分布式环境下这是个难题。如果处理不当,会返回脏数据。
4. 缓存自身成为瓶颈
- 场景:极端高并发下,大量请求访问Redis。
- 问题:
- Redis连接数不够
- 缓存击穿(热点Key失效)
- 缓存雪崩(大量Key同时失效)
- 缓存穿透(查询不存在的数据)
完整的性能优化体系(超越缓存)
基于你的项目经验,一个完整的性能优化应该包含以下层面:
1. 应用层优化(你已经做得很好的部分)
- 线程池与异步处理:使用
CompletableFuture并行处理导入任务。 - 连接池优化:配置合适的数据库连接池(HikariCP)、Redis连接池参数。
- SQL优化:分析执行计划、避免N+1查询、优化索引。
2. 数据库层优化
- 读写分离:将读请求路由到从库,写请求到主库。
- 分库分表:对大数据表(如报价历史表)按时间或业务维度拆分。
- 查询分离:将复杂查询所需的字段单独建表,避免
SELECT *。
3. 架构层优化
- 服务拆分:将系统拆分为独立的微服务(零件服务、报价服务、供应商服务),避免单点压力。
- 消息队列异步化:将非实时操作(如通知供应商、生成报表)通过MQ异步处理。
- 限流与降级:在网关层对接口进行限流,在系统压力大时降级非核心功能。
4. 缓存策略优化
- 多级缓存:
Guava Cache/Local Cache(应用层) +Redis(分布式层)。 - 缓存模式:采用
Cache-Aside模式,先读缓存,不存在则读DB并回写缓存。 - 过期策略:合理设置TTL,结合被动失效和主动更新。
具体到零部件询报价系统的优化方案
读请求优化路径:
- 请求先查询缓存
- 缓存命中直接返回
- 缓存未命中查询从库
- 回写缓存
写请求优化路径:
- 写入主库
- 使相关缓存失效
- 通过MQ异步更新衍生数据
面试专业回答话术
你可以这样回答:
"在零部件询报价系统中,缓存确实是性能优化的重要手段,但不能仅依赖缓存来解决所有并发性能问题。
缓存主要解决的是读多写少场景下的性能瓶颈,比如我们可以缓存热点零件数据、供应商信息、计算好的报价分析结果,这能显著降低数据库压力,将响应时间从数据库的几十毫秒优化到Redis的几毫秒。
但是,我们系统中有大量的写操作,比如供应商并发报价、采购员创建询价单,这些场景下缓存就无能为力了,压力最终会落到数据库上。
因此,我们建立了一个完整的性能优化体系:
- 对于读操作:采用多级缓存(Guava + Redis)和读写分离来分担压力。
- 对于写操作:通过数据库连接池优化、SQL优化、分库分表来提升写入能力,对非实时任务使用消息队列异步化。
- 对于复杂查询:采用查询分离和ES搜索引擎来应对多条件组合查询。
- 系统保护:通过线程池隔离、限流降级防止系统被突发流量冲垮。
在我的项目中,通过这套组合方案,我们在日均10万+的并发调用下,依然能保证核心接口的响应时间在200ms以内。所以,缓存是关键一环,但必须与其他优化手段协同工作。"
这样的回答既肯定了缓存的价值,又展示了你在性能优化方面的系统化思维和实战经验,会给人留下深刻的印象。
To Be Continued.